This article is a comprehensive guide to the OpenPose library for real-time multi-person keypoint detection. We review its architecture and features and compare it with other human pose estimation methods.
In the following, we will cover the following:
- Pose Estimation in Computer Vision
- What is OpenPose? How does it work?
- How to Use OpenPose? (research, commercial)
- OpenPose Alternatives
- What’s Next
A video depicting the output of a pose estimation application built using Viso Suite.
More and more computer vision and machine learning (ML) applications need 2D human pose estimation as input information. This also involves subsequent tasks in image recognition and AI-based video analytics. Single and multi-person pose estimation are computer vision tasks important for action recognition, security, sports, and more.
Pose Estimation is still a pretty new computer vision technology. However, in recent years, human pose estimation accuracy has achieved great breakthroughs with Convolutional Neural Networks (CNNs).
Pose Estimation with OpenPose
A human pose skeleton denotes the orientation of an individual in a particular format. Fundamentally, it is a set of connected data points describing one’s pose. We can also refer to each data point in the skeleton as a part coordinate or point.
We refer to a relevant connection between two coordinates as a limb or pair. However, it is important to note that not all combinations of data points give rise to relevant pairs.
Knowing one’s orientation paves the road for many real-life applications, many of them in sports and fitness. The first-ever technique estimated the pose of a single individual in an image consisting of a single person. OpenPose provides a more efficient and robust approach that applies pose estimation to images with crowded scenes.

What is OpenPose?
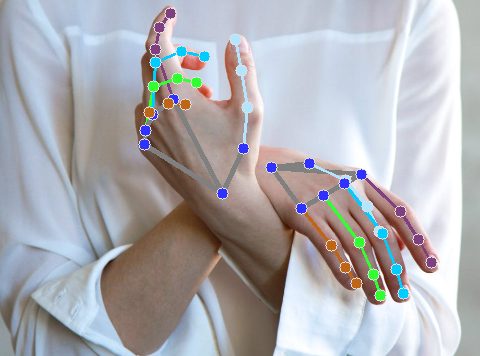
OpenPose is a real-time multi-person human pose detection library. It can jointly detect the human body, foot, hand, and facial key points on a single image. OpenPose is capable of detecting a total of 135 key points.
The method won the COCO 2016 Keypoints Challenge and is popular for quality and robustness in multi-person settings.

Who Created OpenPose?
Ginés Hidalgo, Yaser Sheikh, Zhe Cao, Yaadhav Raaj, Tomas Simon, Hanbyul Joo, and Shih-En Wei created OpenPose technique. It is, however, maintained by Yaadhav Raaj and Ginés Hidalgo.
What are the Features of OpenPose?
The OpenPose human pose detection library has many features, but given below are some of the most remarkable ones:
- Real-time 3D single-person keypoint detections
- 3D triangulation with multiple camera views
- Flir camera compatibility
- Real-time 2D multi-person keypoint detections
- 15, 18, 27-keypoint body/foot keypoint estimation
- 21 hand keypoint estimation
- 70 face keypoint estimation
- Single-person tracking for speeding up the detection and visual smoothing
- Calibration toolbox for the estimation of extrinsic, intrinsic, and distortion camera parameters
Costs of OpenPose for Commercial Purposes
OpenPose falls under a license for free non-commercial use and redistribution under these conditions. If you want to use OpenPose in commercial applications, they require a non-refundable annual fee of USD 25000.
How to Use OpenPose
Lightweight OpenPose
Pose Estimation models usually require significant computational resources and deal with heavy, large models. This makes them unsuitable for real-time video analytics and deployment on edge devices in edge computing. Hence, there is a need for lightweight real-time human pose estimators deployable to devices for edge machine learning.
Lightweight OpenPose effectively performs real-time inference on the CPU with minimal accuracy loss. It detects a skeleton with key points and connections to determine human poses for every person in the image. The pose may include multiple key points, including ankles, ears, knees, eyes, hips, nose, wrists, neck, elbows, and shoulders.
Hardware and Camera
OpenPose supports input from:
- Image, video, webcam
- Webcam Flir/Point Grey cameras
- IP cameras (CCTV)
- Custom input sources (depth cameras, stereo lens cameras, etc.)
Hardware-wise, OpenPose supports different versions of Nvidia GPU (CUDA), AMD GPU (OpenCL), and non-GPU (CPU) computing. We can run it on Ubuntu, Windows, Mac, and Nvidia Jetson TX2.
How to Use OpenPose?
The fastest and easiest way to use OpenPose is by using a platform like Viso Suite. This end-to-end solution provides everything needed to build, deploy, and scale OpenPose applications. Using Viso Suite, you can easily:
- Apply OpenPose using common cameras (CCTV, IP, Webcams, etc.)
- Implement multi-camera systems
- Compute workloads on different AI hardware at the Edge or in the Cloud (Get the Whitepaper here)
Find the official installation guide of OpenPose here.
Find tutorials on the Lightweight implementation version here.
How Does OpenPose Work?
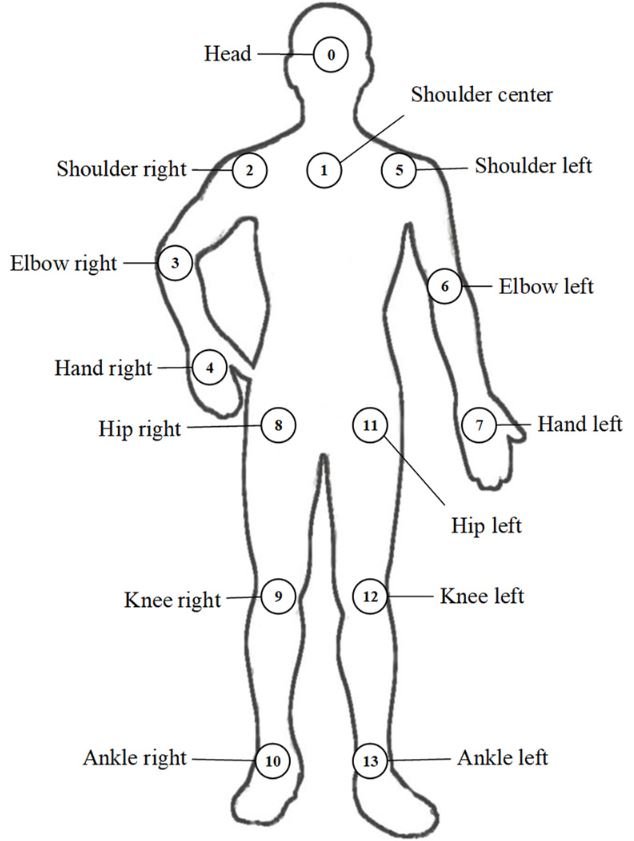
The OpenPose library initially pulls out features from a picture using the first few layers. You then input the extracted features into two parallel divisions of convolutional network layers. The first division predicts 18 confidence maps, each denoting a specific part of the human pose skeleton. The next branch predicts another 38 Part Affinity Fields (PAFs), denoting the level of association between parts.
The model uses later stages to clean the predictions made by the branches. With the help of confidence maps, pairs of parts make up bipartite graphs. Through PAF values, we prune weaker links in the bipartite graphs. Applying the given steps, the model estimates and allocates human pose skeletons to every person in the picture.
Pipeline Overview
The OpenPose Pipeline consists of multiple tasks:
- a) Acquisition of the entire image as input (image or video frame)
- b) Two-branch CNNs jointly predict confidence maps for body part detection
- c) Estimate the Part Affinity Fields (PAF) for parts association
- d) Set of bipartite matchings to associate body part candidates
- e) Assemble them into full-body poses for all people in the image
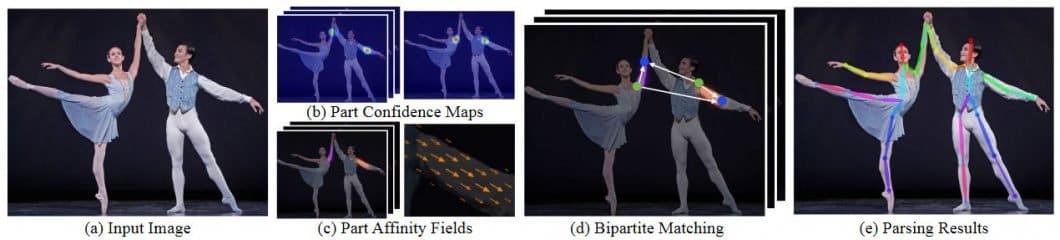
OpenPose vs. Alpha-Pose vs. Mask R-CNN
OpenPose is one of the most well-renowned bottom-up approaches for real-time multi-person body pose estimation. One of the reasons is because of their well-written GitHub implementation. Just like the other bottom-up approaches, Open Pose initially detects parts from every person in the image. These are key points, trailed by allocating those key points to specific individuals.
OpenPose vs. Alpha-Pose
RMPE or Alpha-Pose is a well-known, top-down technique of pose estimation. The creators suggest the precision of the person detector influences top-down methods. This is because we perform pose estimation on the area where the person is present. This is why errors in localization and replicate bounding box predictions can result in sub-optimal algorithm performance.
To solve this issue, the creators introduced a Symmetric Spatial Transformer Network (SSTN). This pulls out a high-quality person region from an incorrect bounding box. A Single Person Pose Estimator (SPPE) estimates the human pose skeleton in this extracted area. A Spatial De-Transformer Network (SDTN) remaps the human pose back to the initial image coordinate system.
Moreover, the authors also introduced a parametric pose Non-Maximum Suppression (NMS) method. This handles the problem of irrelevant pose deductions.
Additionally, a Pose Guided Proposals Generator can multiply training samples to help better train the SPPE and SSTN networks. Most importantly, Alpha-Pose is extensible to any blend of a person detection algorithm and an SPPE.
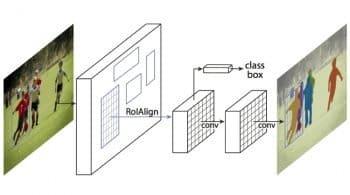
OpenPose vs. Mask R-CNN
Last but not least, Mask RCNN is a popular architecture for performing semantic and instance segmentation. It anticipates the bounding box locations and an object semantic segmentation mask (image segmentation). The architecture of Mask RCNN is extensible for human pose estimation.
It first extracts feature maps from a picture through a Convolutional Neural Network (CNN). A Region Proposal Network (RPN) uses these feature maps to get bounding box candidates for the presence of entities. The bounding box candidates select a region from the feature map. Bounding box candidate sizes can vary, so the RoIAlign layer decreases extracted feature sizes so that they become uniform.
Now, the extracted features pass into the parallel branches of CNNs. This is for the ultimate prediction of the bounding boxes and the segmentation masks. The object detection algorithm can determine the region of individuals. By merging one’s location information and set of key points, we obtain the human pose skeleton for every individual.
This technique is very similar to the top-down method. However, you conduct the person detection step along with the part detection step. Put simply, the keypoint detection phase and the person detection phase are independent of each other.
The Bottom Line for OpenPose
Real-time multi-person pose estimation is an important element in enabling machines to understand humans and their interactions. OpenPose is a popular detection library for pose estimation, capable of real-time multi-person pose analysis.
The lightweight variant makes OpenPose useful in Edge AI and deployment for on-device Edge ML Inference.
To develop, deploy, maintain, and scale pose estimation applications effectively, you need a wide range of tools. The Viso Suite infrastructure provides all those capabilities in one full-scale solution. Get in touch and request a demo for your organization.
What’s Next for OpenPose?
Moving ahead, OpenPose represents a significant advancement in artificial intelligence and computer vision. This development also paves the way for future research and applications to transform how we engage with technology.
Read more about related articles.