PaliGemma 2 is the next evolution in tunable vision-language models introduced by Google based on the success of PaliGemma, and the new capabilities of the Gemma 2 model. Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. PaliGemma 2 builds upon the performant Gemma 2 models, adding the power of vision and making it easier than ever to fine-tune and adapt to different scenarios.
PaliGemma 2 can see, understand, and interact with visual and language input. The Gemma family of models is growing larger and larger, with a huge selection of models to adapt and use. PaliGemma 2, in particular, is a powerful model with multiple sizes for different use cases. In this article, we will explore the potential of PaliGemma 2 by diving deep into its architecture, capabilities and limitations, performance, and a code guide for inferring the model.
Get a Demo
Discover why enterprises choose Viso Suite for scalable, secure, and adaptable AI vision infrastructure.
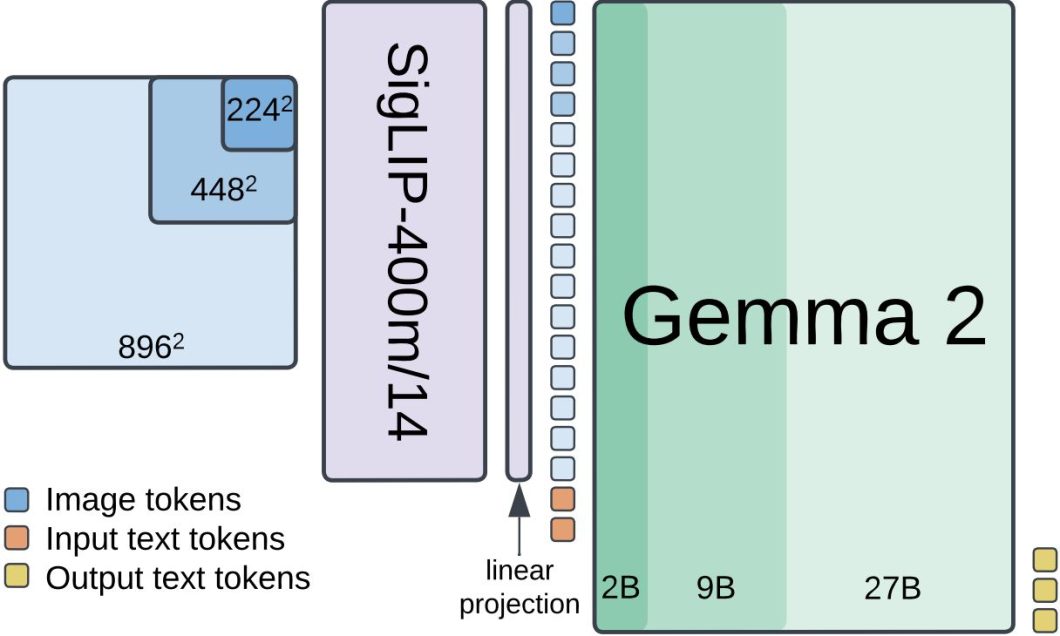
PaliGemma 2 represents a significant advancement in vision-language models (VLMs), built by combining the powerful open-source SigLIP vision encoder and the size variations of Gemma 2 language models. What makes this model family particularly interesting is its multi-resolution approach, offering models at three distinct resolutions and three distinct sizes. PaliGemma 2 is trained with 3 resolutions: 224px², 448px², and 896px². The Google researchers train the models in multiple stages to equip them with broad knowledge for transfer via fine-tuning.
The three different sizes come from the parameter variation of Gemma 2 language models, coming at 3B, 10B, and 28B parameters. This flexibility allows developers and researchers to optimize for their specific use cases, balancing between computational requirements and model performance. Now, let’s dive deeper into the architecture of this model.
Architecture
The whole Gemma family of models is based on the Transformers architecture. PaliGemma 2, for example, combines a Vision Transformer encoder and a Transformer decoder. The vision encoder utilizes SigLIP-400m/14, which processes images using a patch size of 14px². At 224px² resolution, this yields 256 image tokens, at 448px² it produces 1024 tokens, and at 896px² resolution, it generates 4096 tokens. These visual tokens then pass through a linear projection layer before being combined with input text tokens. The text decoder, initialized from the Gemma 2 models (2B, 9B, or 27B), processes this combined input to generate text outputs autoregressively.
The model undergoes a three-stage training process. Stage 0 corresponds to the unimodal pretraining of individual components. In Stage 1, the pre-trained SigLIP and Gemma 2 checkpoints are combined and jointly trained on a multimodal task mixture of 1 billion examples at 224px² resolution. Stage 2 continues training with 50 million examples at 448px² resolution, followed by 10 million examples at 896px². Lastly, stage 3 fine-tunes the checkpoints from stage 1 or 2 (depending on the resolution) to the target task.
Tasks benefiting from higher resolution are given more weight in stage 2. The output sequence length is increased for tasks like OCR for long text sequences. The model applies logits soft-capping to attention and output logits during Stages 1 and 2, using the Adam optimizer with learning rates adjusted based on model size. The training data mixture includes diverse tasks: captioning, grounded captioning, OCR, machine-generated visual question answering, object detection, and instance segmentation.
Capabilities and limitations
PaliGemma 2 as a vision-language model (VLM) has both visual and textual processing capabilities. The model excels in tasks requiring detailed visual analysis, from basic image captioning to complex visual question answering, or even segmentation and OCR. It demonstrates state-of-the-art performance in specialized domains like molecular structure recognition, optical music score recognition, and long-form image captioning. A key strength of PaliGemma 2 is its scalability and flexibility.
The different model sizes and resolutions allow for optimization and transfer learning based on specific needs. For example, the 896px² resolution significantly improves performance on tasks requiring fine detail recognition, such as text detection and document analysis. Similarly, larger model sizes (10B, 28B) show notable improvements in tasks requiring advanced language understanding and world knowledge.
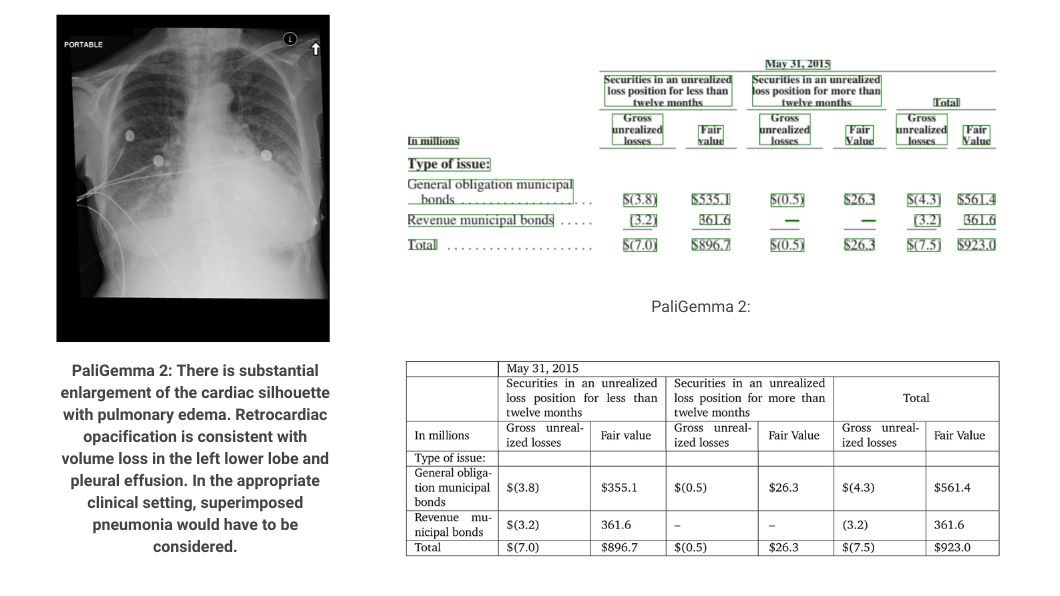
PaliGemma 2 analyzing X-ray images and tables. Source.
However, PaliGemma 2 does face certain limitations. The model’s performance shows varying degrees of improvement with increased size. While scaling from 3B to 10B parameters typically yields substantial gains, the jump to 28B often results in more modest improvements. Additionally, higher resolutions and larger model sizes come with significant computational costs. The training cost per example increases substantially with resolution. Here are a few other things to consider about PaliGemma 2 limitations.
PaliGemma 2 was designed first and foremost to serve as a general pre-trained model for fine-tuning specialized tasks. Hence, its “out of the box” or “zero-shot” performance might lag behind models designed specifically for general-purpose use.
PaliGemma 2 is not a multi-turn chatbot. It is designed for a single round of image and text input.
Natural language is inherently complex. VLMs in general might struggle to grasp subtle nuances, sarcasm, or figurative language.
PaliGemma 2 performance and benchmarks
The PaliGemma 2 performance is impressive compared to much larger VLMs. The Google researchers upgraded PaliGemma to PaliGemma 2 by replacing its language model component with the more recent and more capable language models from the Gemma 2 family. PaliGemma 2 showcased significant improvements upon its predecessor according to benchmark evaluations across various tasks and domains. When comparing models of the same size (3B parameters) PaliGemma 2 consistently outperforms the original PaliGemma by an average of 0.65 at 224px² and 0.85 points at 448px².
PaliGemma 2’s real strength lies in its larger variants. By leveraging the more capable Gemma 2 language models (10B and 28B parameters), PaliGemma 2 achieves substantial improvements over both its predecessor and other state-of-the-art models. These improvements are particularly noticeable in tasks requiring advanced language understanding or fine-grained visual analysis. Let’s dive deeper into the performance across different domains and examine how model size and resolution affect various tasks.
Standard vision-language tasks
The researchers evaluated PaliGemma 2 on over 30 academic benchmarks covering a broad range of vision-language tasks. These benchmarks include visual question answering (VQA), image captioning, referring expression tasks, and more. Looking at performance patterns, tasks generally fall into three categories based on how they benefit from model improvements.
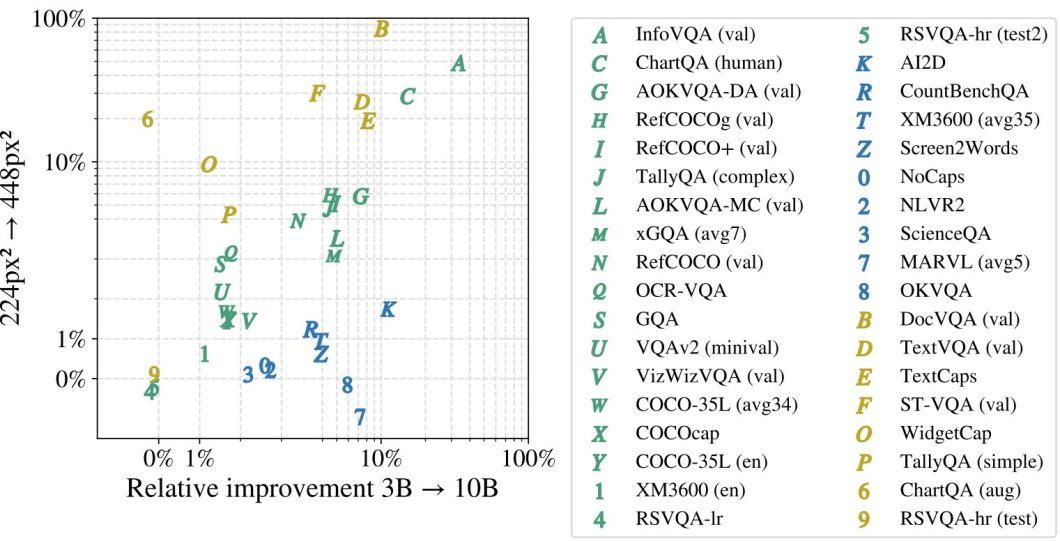
PaliGemma 2 relative improvements of metrics after transfer, when choosing a pre-trained checkpoint with a larger LM, or with a higher resolution. Source.
The tasks in the above graph are grouped into tasks sensitive to both model size and resolution (Green), sensitive to model size (Blue), and sensitive to resolution (Yellow). Tasks that benefit equally from increased resolution and larger model sizes include InfoVQA, ChartQA, and AOKVQA. These tasks typically require both fine-grained visual understanding and strong language capabilities. For example, AOKVQA-DA improved by 10.2% when moving from the 3B to 10B model, and showed similar gains with increased resolution. Some tasks are more sensitive to resolution increases.
Document and text-focused tasks like DocVQA and TextVQA showed dramatic improvements with higher resolutions – DocVQA’s performance jumped by 33.7 points when moving from 224px² to 448px². This makes intuitive sense as these tasks require reading fine text details. Other tasks benefit primarily from larger language models. Tasks involving multilingual processing (like XM3600) or advanced reasoning (like AI2D and NLVR2) showed greater improvements from model size increases than resolution increases. An interesting finding is that while scaling from 3B to 10B parameters typically yields substantial gains, the jump to 28B often results in more modest improvements. This suggests a potential “sweet spot” in the model size/performance trade-off for many applications.
Specialized domain performance
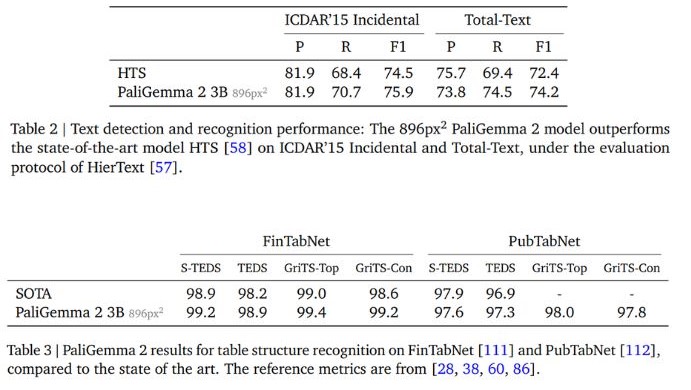
PaliGemma 2 showcased great versatility in specialized domains, often matching or exceeding the performance of purpose-built models. For example, PaliGemma 2 3B at 896px² resolution outperforms the state-of-the-art HTS model on the ICDAR’15 and Total-Text benchmarks in text detection and recognition. The model achieves this performance without implementing task-specific architecture components common in OCR research.
PaliGemma 2 performance on table and text detection benchmarks. Source.
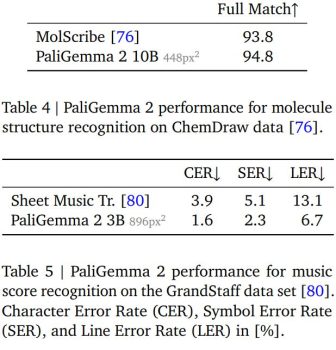
PaliGemma 2 also sets a new state-of-the-art benchmark for table structure recognition. When tested on the FinTabNet and PubTabNet datasets, the model achieves great accuracy in cell text content and structural analysis. Beyond document processing, PaliGemma 2 shows strong performance in scientific domains. In molecular structure recognition, the 10B parameter model at 448px² resolution achieves a 94.8% exact match rate on ChemDraw data, exceeding the specialized MolScribe system. Additionally, in optical music score recognition, PaliGemma 2 reduces error rates across multiple metrics compared to previous methods.
PaliGemma 2 on molecule structure recognition and music score recognition benchmarks. Source.
These results are impressive as they demonstrate PaliGemma 2’s ability to handle highly specialized tasks without requiring domain-specific architectural modifications. Lastly, the model presents state-of-the-art performance for long captioning after fine-tuning it on the DOCCI (Descriptions of Connected and Contrasting Images). Outperforming models like LLaVA-1.5 and MiniGPT-4 in factual inaccuracies, which are measured using Non-Entailment Sentences (NES).
Real-world applications
PaliGemma 2 is a versatile model with impressive performances on over 30 benchmarks, however, its true value lies in practical applications. PaliGemma 2 is made to be tunable, this ease of fine-tuning the model makes it suitable for many real-world applications across different industries. Following are some key applications where PaliGemma 2 shows significant potential.
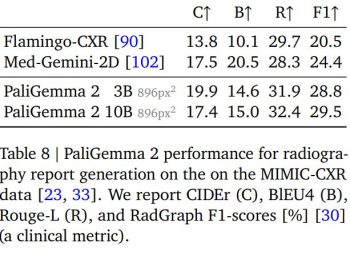
A prime example is in medical imaging, where the model has been tested on the MIMIC-CXR dataset for automatic chest X-ray report generation. The model achieves a RadGraph F1-score of 29.5% (10B model at 896px²), surpassing previous state-of-the-art systems like Med-Gemini-2D.
Additionally, for practical deployment, PaliGemma 2 offers flexible options for CPU inference. The researchers tested CPU-only inference using different architectures and found viable performance even without accelerators. The model’s ability to run efficiently on different hardware configurations and its strong performance across diverse tasks make it suitable for real-world implementations.
Getting started with PaliGemma 2: Hands-on guide
PaliGemma and PaliGemma 2 have been widely accessible and easy to use, and fine-tuned since their introduction. The Implementation of PaliGemma 2 is available through the Hugging Face Transformers library, with just a few lines of Python code. In this section, we will explore how to properly prompt and infer PaliGemma 2 using a Kaggle notebook environment. We will be using the Transformers inference implementation because it allows for simpler code. The Kaggle notebook will provide us with the needed computational resources and Python libraries to run the model.
Proper prompting is crucial for getting the best results from PaliGemma 2. The model was trained with specific prompt formats for different tasks, and following these formats will help in getting the optimal performance. Unlike chat-based models, PaliGemma 2 is designed for single-turn interactions where the input format significantly impacts the quality of outputs. Before diving into the inference implementation, let’s first explore these prompting best practices to help you get the most out of the model.
Prompting guide
PaliGemma 2 has specific prompt keywords to use when trying to perform specific tasks. So, to fully utilize PaliGemma 2’s capabilities, it’s essential to understand the different model types and their corresponding prompting strategies. PaliGemma 2 comes in three categories.
Base Models: Pre-trained models that take empty prompts and are recommended for fine-tuning specific tasks.
Fine-tuned (FT) Models: Specialized models trained for specific tasks that only support syntax for their target task.
Mix Models: Versatile models that support all task keywords and prompting strategies.
Example from fine-tuned PaliGemma 2 Demo on HuggingFace. Source.
For our implementation, we will utilize the base model type for ease of implementation and raw performance. However, here are the key prompting formats supported by Mix models.
answer en where is the cow standing?\n Answers questions about image content
answer {lang} {question}\nQuestion answering about the image contents
question {lang} {answer}\nQuestion generation for a given answer
Object detection:
detect {object} ; {object}\n Returns bounding boxes for a list of specified objects
segment {object}\n Creates segmentation masks for specified objects
Important: When working with PaliGemma 2, the image data must always be provided before the text prompt. This order is crucial for generating usable responses.
Set up PaliGemma 2 with transformers
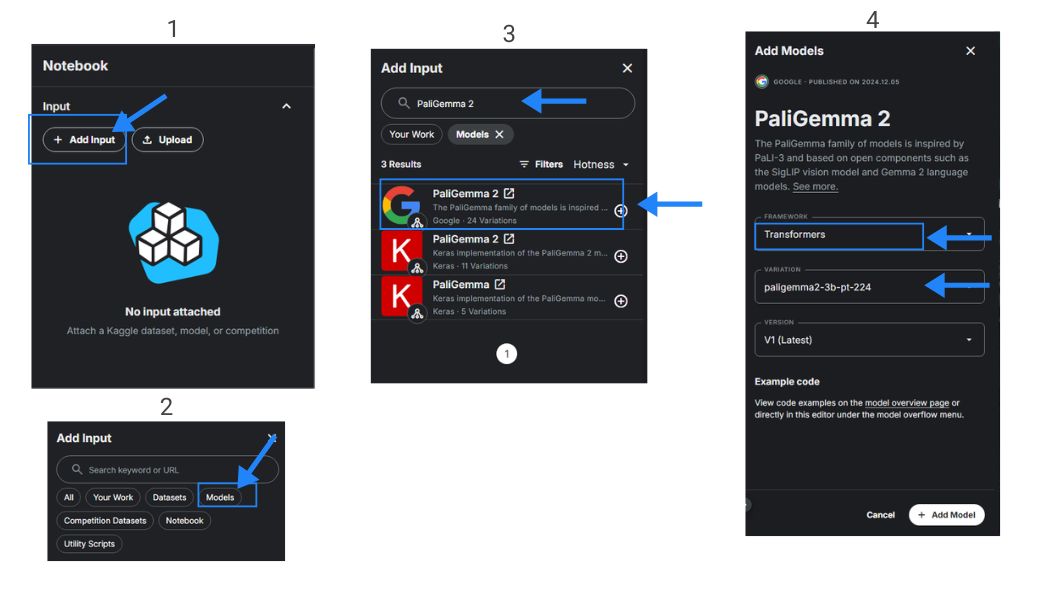
To get started on inferring PaliGemma 2, open up a Kaggle notebook and use an accelerator. Next, make sure to go to the PaliGemma 2 model card here, and accept the agreement to use the model.
Uploading PaliGemma 2 Utilizing the Transformers Framework.
To use the model within the notebook, on the right panel, choose to add input, then choose models, and search for PaliGemma 2. In this guide, we will be using the Transformers framework and the 3B parameter variant. Make sure you have accepted the terms and restart the notebook. Now, let’s import and install the needed libraries.
pip install --upgrade transformers
This will install the transformers library with the latest version, which is needed for this implementation.
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
from transformers import BitsAndBytesConfig
import torch
Those lines of code simply import the needed libraries from transformers, the Pillow library for image processing, as well as Pytorch.
Inference PaliGemma 2 base model
Now, we are ready to load the model into the code with a few simple lines.
model_id = "/kaggle/input/paligemma-2/transformers/paligemma2-3b-pt-224/1"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
model = model.to("cuda")
processor = AutoProcessor.from_pretrained(model_id)
This code loads the PaliGemma 2 3B parameter model and a 224×224 image size. The code first defines the model path (copied from the right panel), initializes the model, moves it to the GPU(cuda), and defines the processor. Lastly, we will need to define the prompt and load our image.
The code above defines the prompt with the proper formatting for the pre-trained base model. We define the image path and load it using the Pillow library. Now, let’s process the image and give it to the model.
What this does is it utilizes the pre-defined processor from Transformers to process the prompt and image, and moves them into the GPU with the model. Then the output is generated simply by using model.generate() the generate method takes in the input as a parameter and the maximum output tokens. Now, let’s display the output.
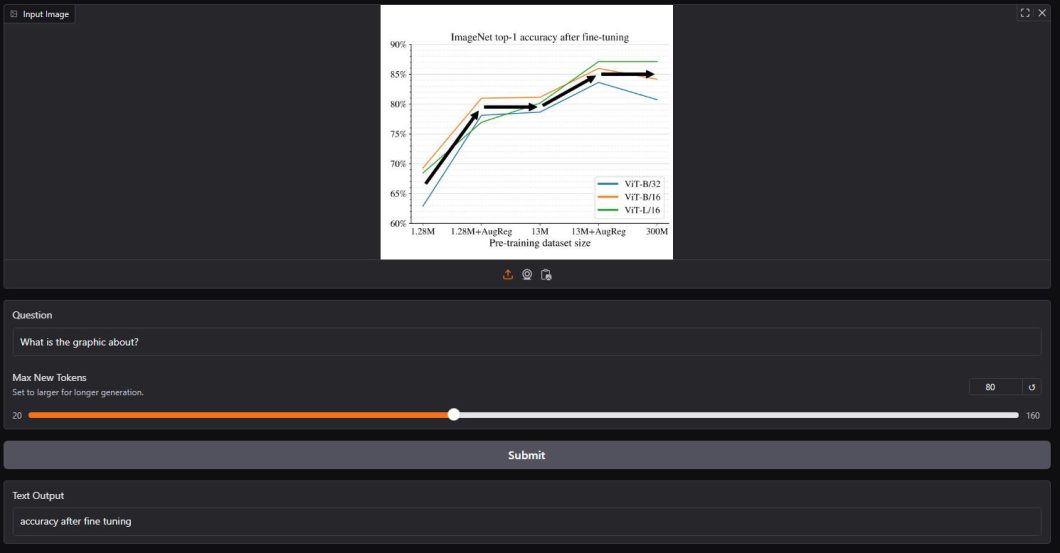
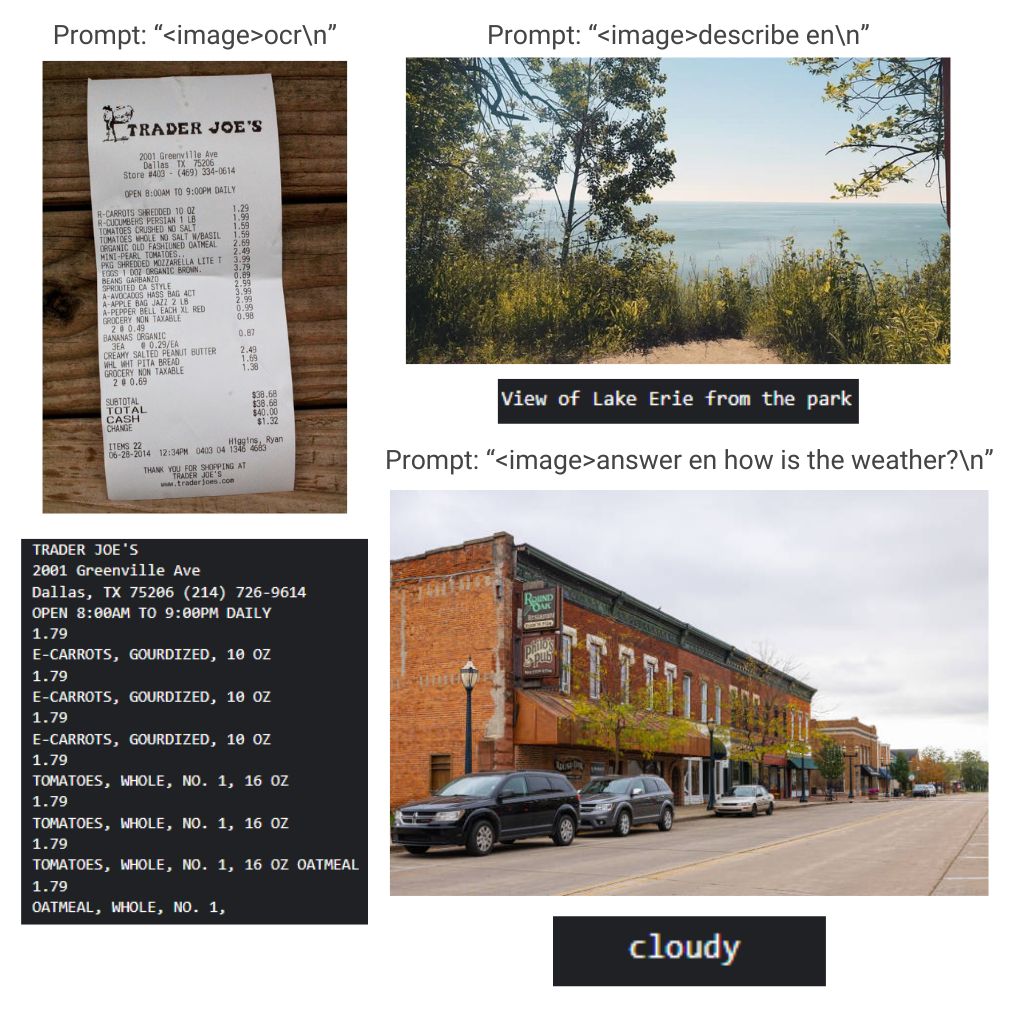
This code processes the output to display normally. Here is a look at the few results I tried from available datasets.
Testing PaliGemma 2 base model on a variety of tasks.
The future of vision-language models: PaliGemma 2 and beyond
PaliGemma 2 represents a significant step forward in making vision-language models more accessible and versatile for real-world applications. Through its various model sizes and resolutions, it offers developers and researchers the flexibility to balance performance with computational requirements. The model’s ability to handle tasks ranging from simple image captioning to complex molecular structure recognition demonstrates its potential as a foundational model for various industries.
What makes PaliGemma 2 particularly noteworthy is its design philosophy focusing on ease of use and adaptability. This accessibility, paired with its strong performance across diverse tasks, positions it as a valuable tool for both research and practical applications.
Looking ahead, PaliGemma 2’s architecture and training approach could influence the development of future vision-language models. Its success in combining a powerful vision encoder with varying sizes of language models suggests a promising direction for scaling and optimizing multimodal AI systems. As the field continues to evolve, PaliGemma 2’s emphasis on transfer learning and fine-tuning capabilities will likely remain crucial for advancing the practical applications of vision-language models across industries.
FAQs
To run PaliGemma 2, you need a GPU with sufficient VRAM (the amount depends on the model size). For the 3B parameter model, a standard GPU with 8GB VRAM is sufficient.
The choice depends on your specific needs. Fewer parameters mean faster but lower-quality performance. More parameters mean slower more resource-intensive, but higher quality results.
Yes, PaliGemma 2 is designed to be fine-tuned. The process requires a dataset relevant to the use case. Google provides comprehensive documentation for fine-tuning with Keras.