
Foundation models are recent developments in artificial intelligence (AI). Models like GPT-4, BERT, DALL-E 3, CLIP, Sora, etc., are at the forefront of the AI revolution. While these models may seem diverse in their capabilities – from generating human-like text to producing stunning visual art – they share a common thread: They are all pioneering examples of foundation models.
These models are trained on vast amounts of unlabeled or self-supervised data to acquire a broad knowledge base and language understanding capabilities. They extract meaningful features and patterns from the training data and fine-tune them for specific tasks.
What are Foundation Models?
Foundation models are large-scale neural network architectures that undergo pre-training on vast amounts of unlabeled data through self-supervised learning. Self-supervised learning allows them to learn and extract relevant features and representations from the raw data without relying on labeled examples. The main goal of foundation models is to serve as a starting point or foundational building block for many AI tasks, like natural language processing, question answering, text generation, summarization, and even code generation.
With billions or even trillions of parameters, foundation models can effectively capture patterns and connections within the training data. While early models such as GPT-3 were text-focused. They take textual input and generate textual output. Recent models like CLIP, Stable Diffusion, and Gato are multimodal and can handle data types like images, audio files, and videos.
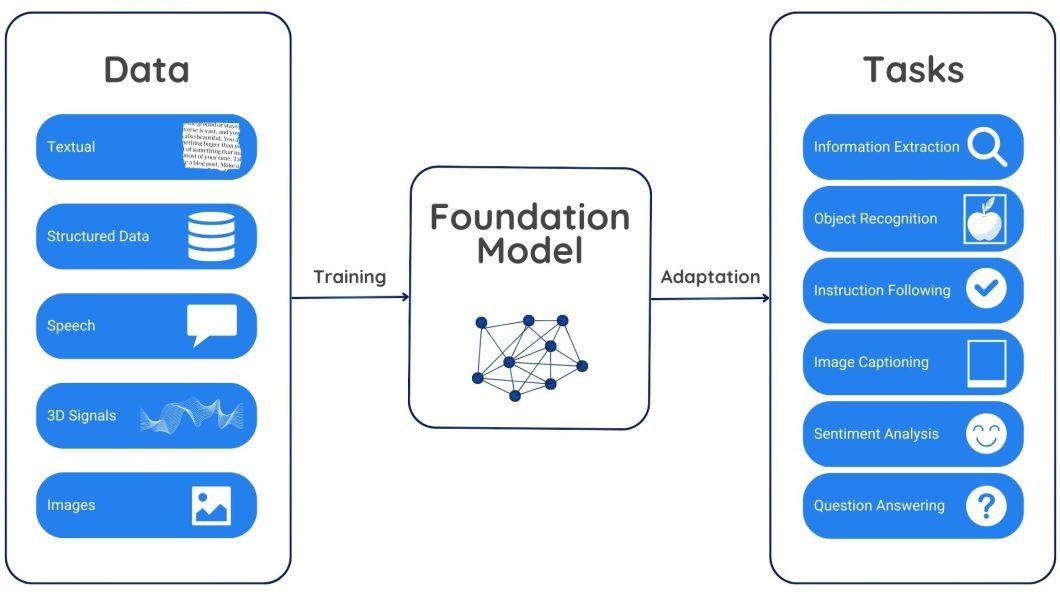
How Do Foundation Models Work?
Foundation models work on self-supervised learning, which allows them to learn meaningful representations from the input data without relying on explicit labels or annotations. They are pre-trained on huge datasets. During this stage, the model predicts missing parts, fixes corrupted data, or finds connections between different data types. This teaches the model inherent patterns and relationships within the data.
Pre-training equips the model with a strong understanding of the underlying data structure and meaning. This learned knowledge becomes a foundation for specific tasks performed by the model. By fine-tuning smaller, specific datasets, the model can be adapted for various tasks.
For example, a foundation model trained on textual data might understand word relationships, sentence formations, and diverse writing styles. This foundational understanding enables the model to perform tasks like generating text, translating content, and answering questions after fine-tuning.
Similarly, if we train a foundation model on diverse image datasets, the model can learn to recognize objects, their parts, and their underlying relationships. This trained knowledge can enable the foundation model to perform various computer vision tasks after fine-tuning. For example, we can fine-tune a model to detect specific objects in images (like cars, traffic signals, and medical anomalies in X-ray reports), classify images (like landscapes, and indoor or outdoor scenes), or even generate new images based on textual descriptions.
Use Cases of Foundation Models
Foundation models excel in natural language processing, computer vision, and various other artificial intelligence tasks. Each applies foundation models in different ways to handle complex tasks.
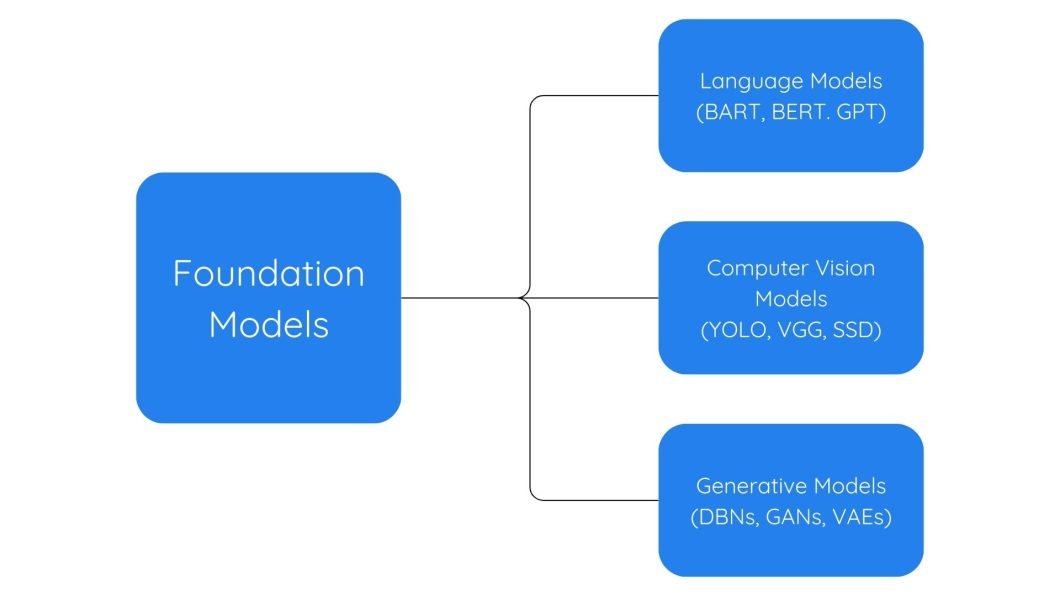
Let’s discuss some of them in detail:
Natural Language Processing
Natural Language Processing (NLP) lets computers understand and process human language. It encompasses speech recognition, text-to-speech conversion, language translation, sentiment analysis in text, content summarization, and prompt-based question-answering tasks.
Traditional NLP methods heavily rely on models trained on labeled datasets. These models often struggled to adapt to new areas or tasks and were limited by the availability of high-quality labeled data.
Meanwhile, the emergence of large language models LLMS, or foundation models, has transformed this field by enabling the creation of more robust and adaptable language models. These powerful models can handle many NLP tasks with just a little fine-tuning on smaller datasets. Examples include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), Claude, etc.
Computer Vision
Computer vision is a specialized area of artificial intelligence that focuses on processing and understanding visual data. It builds algorithms to identify objects, analyze scenes, and track motion.
Foundation models are pushing the boundaries of computer vision. One significant progress facilitated by these models is the emergence of multimodal vision language models like CLIP, DALL-E, Sora, etc. These models combine computer vision and language processing to understand images and text together. They can describe images (captioning), answer questions about them (visual question answering), and even generate new images or videos.
Likewise, computer vision models such as ResNet (Residual Network) and VGG (Visual Geometry Group) have gained widespread adoption for operations like image classification, object detection, and semantic segmentation. These models are pre-trained on extensive datasets of labeled images and can be fine-tuned for specific computer vision assignments.
Generative AI
What are the foundation models in Generative AI? Unlike computer vision tasks that focus on interpreting visual data, generative AI models are designed to produce entirely new content. This encompasses creating text that resembles human writing, crafting high-quality images, audio/video generation, coding, and generating other structured data formats.
The advent of foundation models has revolutionized the training and development of generative AI systems. These large-scale models are pre-trained on vast amounts of data. They learn to capture intrinsic patterns, relationships, and representations within data applied to many downstream tasks, including new content generation.
Applications of Foundation Models in Pre-trained Language Models
GPT (Generative Pre-trained Transformer)
GPT is a large language model from open-source OpenAI. It is a transformer-based neural network architecture that is pre-trained on a massive amount of text data using an unsupervised learning technique called self-attention.
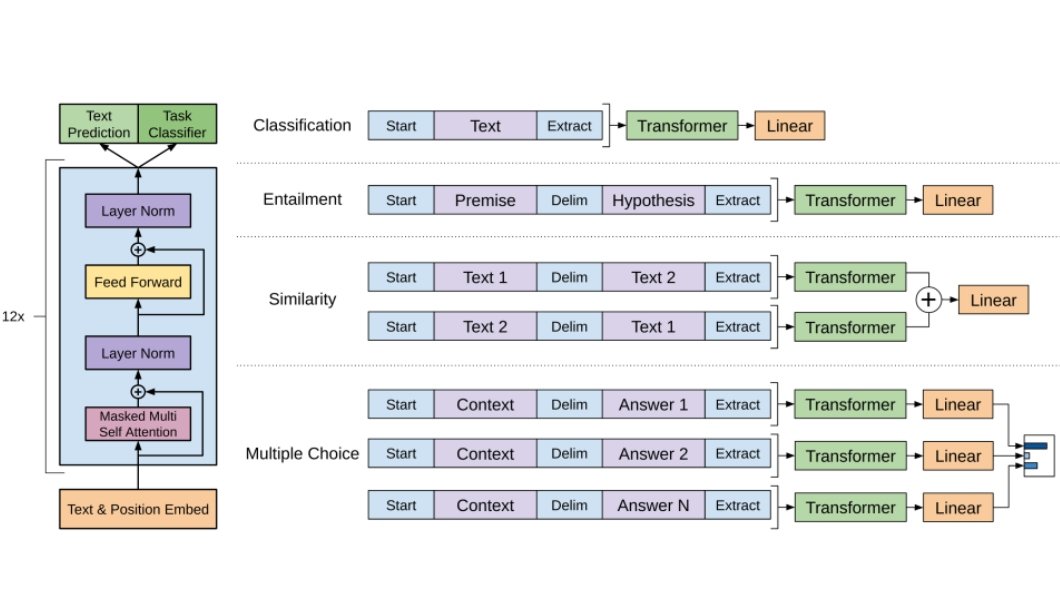
Pre-training: GPT undergoes pre-training using an extensive collection of text data sourced from the internet, like books, research journals, articles, and web content.
It utilizes a technique called “generative pre-training” to predict the next word in a sequence. This involves masking words in the input text with special tokens and training the model to predict these masked words within their contextual framework.
Architecture: GPT utilizes transformer architecture with self-attention mechanisms. The architecture consists of multiple encoder and decoder layers, each composed of self-attention and feed-forward neural networks.
In the encoding process, the transformer encoder takes the input sequence (text) and produces a contextualized representation for each token (word or subword) in the sequence. Subsequently, in the decoding phase, the output sequence is generated “token by token” by considering parts of both the input sequence and previously generated tokens.
Inference (Generation): GPT receives a prompt (a text sequence) as input. The model leverages its learned knowledge and language comprehension to predict the next token (word or subword) that is most likely to come after the prompted input. The generated token is then fed back into the model, and the process continues iteratively until certain criteria are met (e.g., it reaches a certain length).
Fine-tuning: After pre-training, GPT models can be fine-tuned to specific tasks, such as text generation, summarization, or question answering. Fine-tuning adjusts the model’s parameters for these tasks while retaining its pre-trained knowledge.
Newer versions like GPT-3 and GPT-4, trained on even larger datasets. They are showcasing remarkable abilities in generating coherent and contextually relevant text for diverse applications.
BERT (Bidirectional Encoder Representations from Transformers)
Google created BERT, a machine learning model for tasks related to natural language processing. This is how BERT undergoes the training and fine-tuning process.
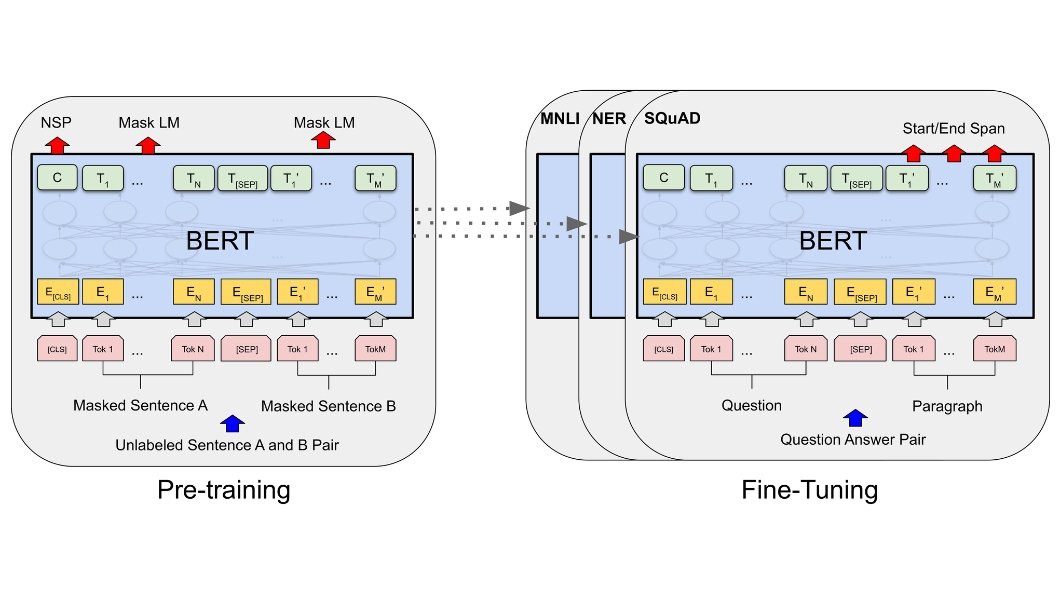
BERT undergoes training on an amount of unlabelled text data by performing two main tasks: masked language modeling and next sentence prediction.
- Masked Language Modelling: During masked language modeling, certain tokens in the input sequence are randomly replaced with a [MASK] token, and the model learns to predict the original values of these masked tokens based on the surrounding context.
- Next Sentence Prediction: In sentence prediction, the model is taught to determine if two given sentences follow each other in sequence or not.
Unlike GPT models, BERT is bidirectional. It considers both preceding and succeeding contexts simultaneously during training.
Fine Tuning:
After pre-training, BERT adapts to specific tasks (classification, question answering, etc.) with labeled data. We add task-specific layers on top of the pre-trained model and fine-tune the entire model for the target task.
Various versions of BERT, such as RoBERTa, DistilBERT, and ALBERT, enhanced the BERT models’ performance, efficiency, and applicability to different scenarios.
Applications of Foundation Models in Computer Vision Tasks
ResNet
Residual Network (ResNet) is not directly utilized as a foundation model. Rathe,r it serves as a Convolutional Neural Network (CNN) architecture known for its excellence in tasks related to computer vision, such as image recognition.
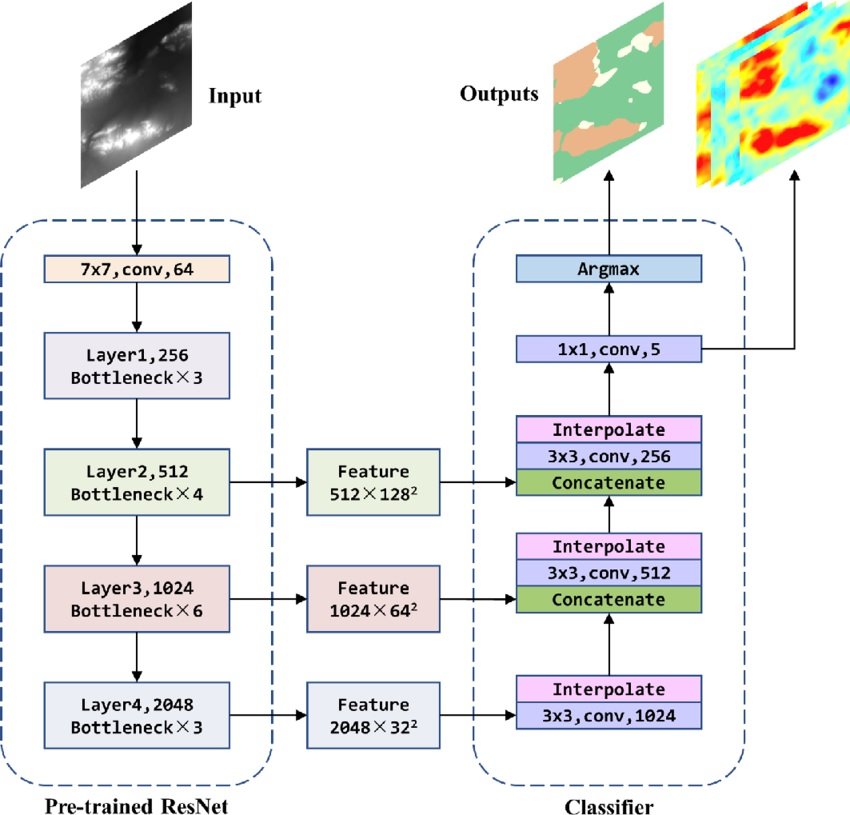
- Pre-training for Feature Extraction: ResNet models that are pre-trained on image datasets such as ImageNet can serve as a solid foundation for various computer vision assignments. These pre-trained models may acquire robust image representations and feature extraction capabilities.
- Provide Base for Training CV Foundation Models: The pre-trained weights of a ResNet can act as an initial point for training a foundational model. This foundational model can then be fine-tuned for purposes like object detection, image segmentation, or image captioning. By harnessing the trained features from ResNet, the foundational model can efficiently learn these new tasks.
VGG
Very Geometry Group (VGG) is not itself a foundation model. Rather, it is a pre-trained convolutional neural network (CNN) architecture extracting low- and mid-level visual features from images during the self-supervised pretraining phase.
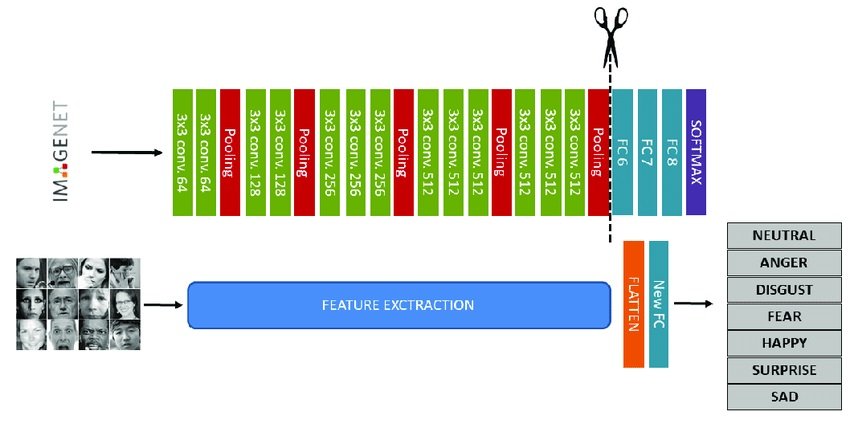
- The early layers of VGG are effective at recognizing and extracting fundamental image features like edges and shapes. These features are then passed on to other layers to learn more complex representations through transformers or contrastive learning modules. Once pre-trained, these extracted features feed into a larger foundation model focused on a specific task, like an object detection foundation model or image segmentation.
- The VGG backbone provides a strong starting point for building a foundation model. When fine-tuning, the weight of the VGG backbone can either remain fixed or receive adjustments along with the rest of the model for downstream tasks. This saves time and computing resources compared to training an entirely new model from scratch.
Image Captioning
Image captioning is a computer vision task that aims to generate natural language descriptions for given images. We have seen significant advancements in this area due to foundation models. Such foundation models learn to align visual and textual representations through self-supervised objectives like masked language modeling and contrastive learning.
During pre-training, the model takes an image as input and generates a relevant caption by extracting its visual features.
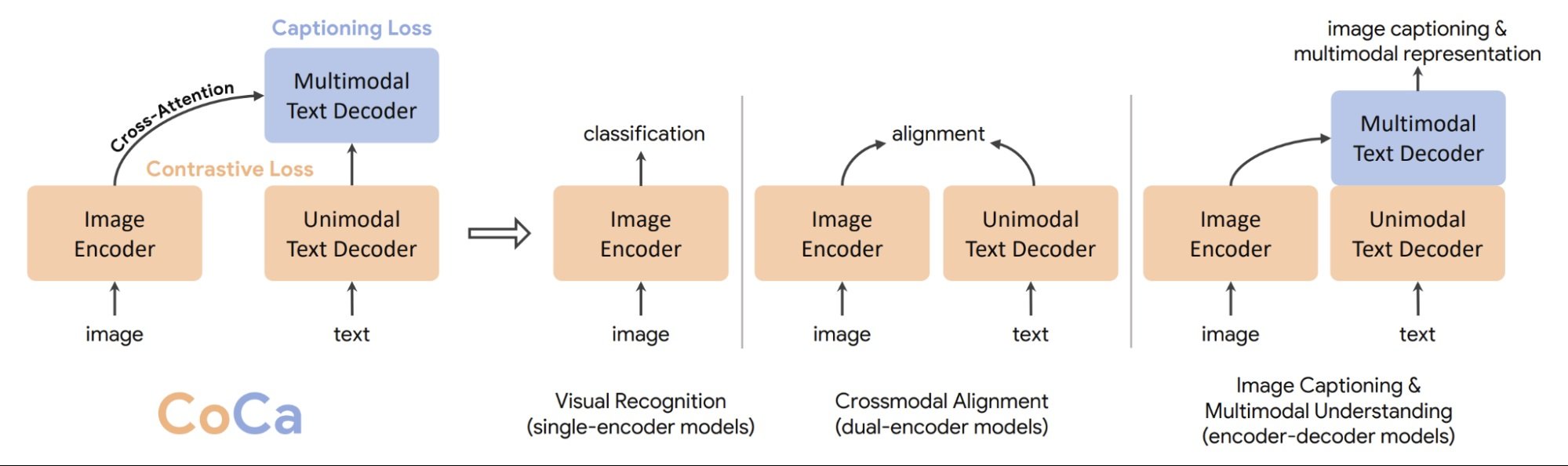
One recent example is the CoCa (Contrastive Captioners) model, an advanced foundation model, specifically designed for image-text tasks. Coca learns from the similarities and differences between captions describing the same image. This allows CoCa to perform various tasks like generating captions for new images and answering questions about the content of an image.
Visual Question Answering (VQA)
Visual Question Answering (VQA) involves AI systems answering natural language questions about image content. Foundational models have advanced in this field through self-supervised pre-training on large image-text datasets. These models align visual and textual representations with masked region modeling and contrastive learning tasks. During the answering process, the model analyzes both the image and question, focusing on relevant visual aspects and utilizing its understanding of different modes of information.
Notable examples include ViLT, METER, and VinVL. Through diverse data pre-training, these foundational models establish a strong visual linguistic foundation for accurate question answering across various domains with minimal fine-tuning required.
Applications of Foundation Models in Multimodal Learning
CLIP (Contrastive Language-Image Pre-Training)
CLIP excels at bridging the gap between text and images. It’s a foundation model for multimodal tasks like image captioning and retrieval. CLIP adapts for various tasks involving both modalities, such as generating new images, answering questions about visuals, and retrieving information based on image-text pairs.
Here’s how CLIP works:
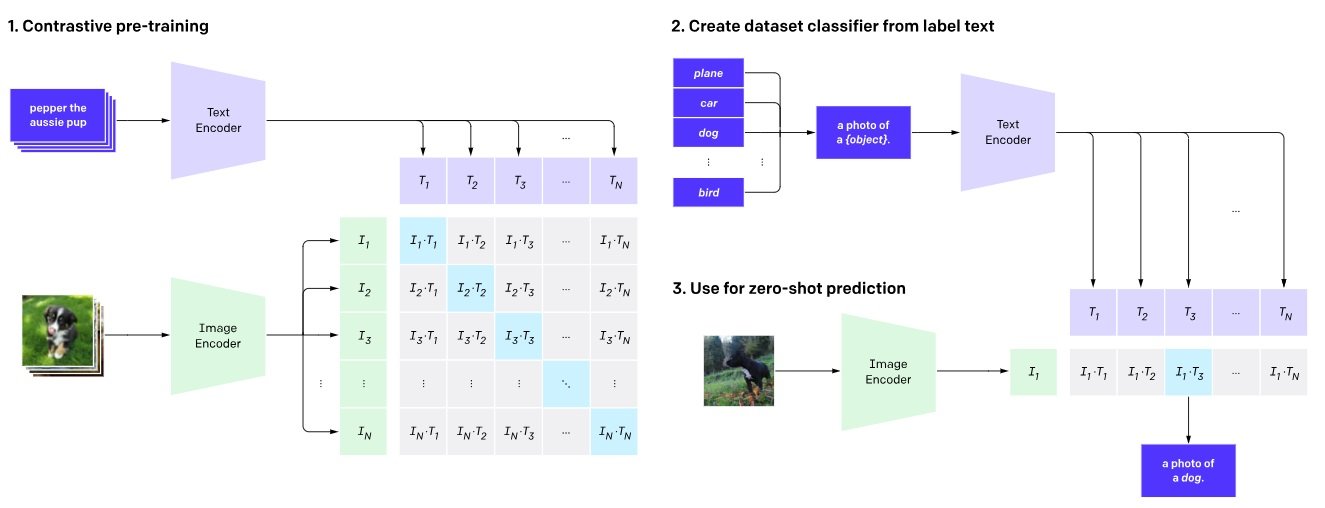
Contrastive Learning: CLIP brings similar image-text pairs closer and pushes dissimilar ones apart, once the vector embeddings are mapped.
- It boosts the similarity score between correctly paired image embeddings and their corresponding textual descriptions.
- Reduce the similarity score between an image and any incorrect textual description.
Check our comprehensive article on CLIP for a more detailed understanding of its pre-training and fine-tuning processes.
Emerging Trends And Future Advancements In Foundation Model Research
Foundation model research is pushing boundaries in artificial intelligence in two key areas:
- Scaling
- Interpretability.
Researchers are continuously working on creating larger models to capture intricate data relationships. Moreover, there is a growing emphasis on understanding how these models arrive at decisions to enhance trust and dependability in their results.
This dual focus promises even more powerful AI tools in the future.
Implementing Real-World Computer Vision
Foundation models serve as the cornerstone of the next generation of intelligence systems. They offer scalable, adaptable, and versatile frameworks for building advanced AI applications. By harnessing the power of deep learning and large-scale data, these models will reshape how we interact with technology.
Here are some recommended reads to gain more insights about the topic:
- Learn about OpenAI Sora – The Newest Foundation Model
- A Revolutionary Approach in AI Language Models – Llama 2
- An Ultimate Guide to Understanding and Using AI Models
- Learn about the 12 Top Computer Vision Models
- The Step-by-Step Process of Building a Machine Learning Model