In many Artificial Intelligence (AI) applications such as Natural Language Processing (NLP) and Computer Vision (CV), there is a need for a unified pre-training framework (e.g. Florence-2) that will function autonomously. The current datasets for specialized applications still need human labeling, which limits the development of foundational models for complex CV-related tasks.
Microsoft researchers created the Florence-2 model (2023) that is capable of handling many computer vision tasks. It successfully solves the lack of a unified model architecture and weak training data.
Review of Foundation Models
In a nutshell, foundation models are pre-trained on some universal tasks (often in self-supervised mode). Otherwise, it is impossible to find a lot of labeled data for fully supervised learning. They can be easily adapted to various new tasks (with or without fine-tuning/additional training), within context learning.
Researchers introduced the term ‘foundation’ because they are the foundations for many other problems/challenges. There are advantages to this process (it is easy to build something new) and disadvantages (many will suffer from a bad foundation).
These models are not fundamental for AI since they are not a basis for understanding or building intelligence or consciousness. To apply foundation models in CV tasks, Microsoft researchers divided the range of tasks into three groups:
- Space (scene classification, object detection)
- Time (statics, dynamics)
- Modality (RGB, depth)
Then they defined the foundation model for CV as a pre-trained model and adapters for solving all problems in this Space-Time-Modality with the ability to transfer the zero learning type.
They presented their work as a new paradigm for building a vision foundation model and called it Florence-2 (the birthplace of the Renaissance). They consider it an ecosystem of 4 large areas:
- Data gathering
- Model pre-training
- Task adaptations
- Training infrastructure
For more information, check out our article on foundation models.
What is Florence-2?
Xiao et al. (Microsoft, 2023) developed the Florence-2 in line with NLP aims of flexible model development with a common base. Florence-2 combines a multi-sequence learning paradigm and common vision language modeling for a variety of computer vision tasks.
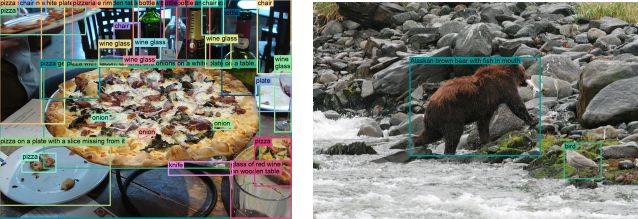
Florence-2 redefines performance standards with its exceptional zero-shot and fine-tuning capabilities. It performs tasks like captioning, expression interpretation, visual or phrase grounding, and object detection. Furthermore, Florence-2 surpasses current specialized models and sets new benchmarks using publicly available human-annotated data.
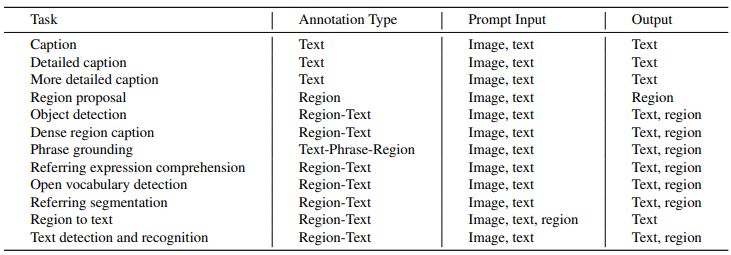
Florence-2 uses a multi-sequence architecture to solve various vision-language tasks. Every task is handled as a transit problem in which the model is given both an image and text input as the prompt, which are task-specific. It then generates text as the appropriate output, or answer.
Tasks can contain geographical or text-based data, and the model adjusts its processing according to the task’s requirements. Researchers included location tokens in the tokenizer’s vocabulary list for tasks specific to a given region. These tokens provide multiple formats, including box, quad, and polygon representations.

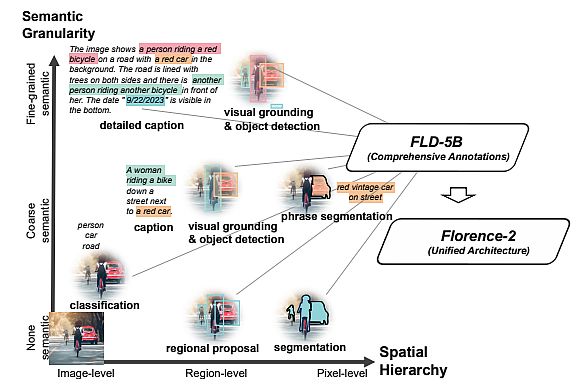
- Understanding images and language descriptions that capture high-level semantics and facilitate a thorough comprehension of visuals. Exemplar tasks include image classification, captioning, and visual question answering.
- Region recognition tasks, enabling object recognition and entity localization within images. They capture relationships between objects and their spatial context. For instance, object detection, image segmentation, and referring expression are such tasks.
- Granular visual-semantic tasks require a granular understanding of both text and image. They involve locating the image regions that correspond to the text phrases, such as objects, attributes, or relations.
Florence-2 Architecture and Data Engine
Being a universal representation model, Florence-2 can solve different CV tasks with a single set of weights and a unified representation architecture. As the figure below shows, Florence-2 applies a multi-sequence learning algorithm, unifying all tasks under a common CV modeling goal.
The single model takes images coupled with task prompts as instructions and generates the desired labels in text form. It uses a vision encoder to convert images into visual token information. To generate the response, the tokens are paired with text information and processed by a transformer-based encoder or decoder.
Microsoft researchers formulated each task as a translation problem: given an input image and a task-specific prompt, they created the proper output response. Depending on the task, the prompt and response can be either text or region.
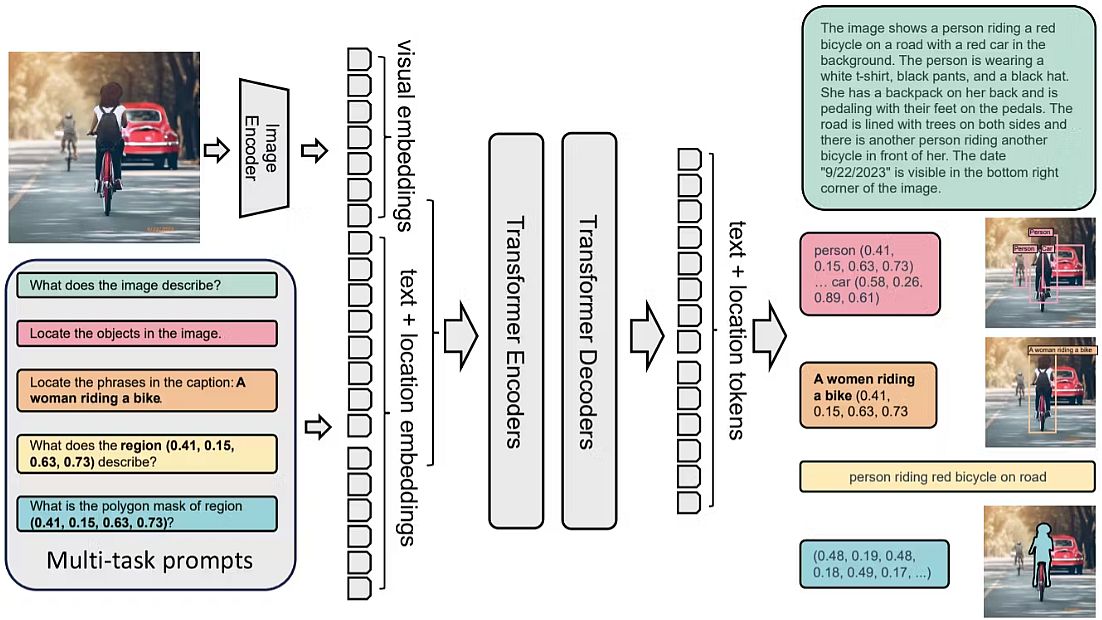
- Text: When the prompt or answer is plain text without special formatting, they maintained it in their final multi-sequence format.
- Region: For region-specific tasks, they added location tokens to the tokens’ vocabulary list, representing numerical coordinates. They created 1000 bins and represented regions using formats suitable for the task requirements.
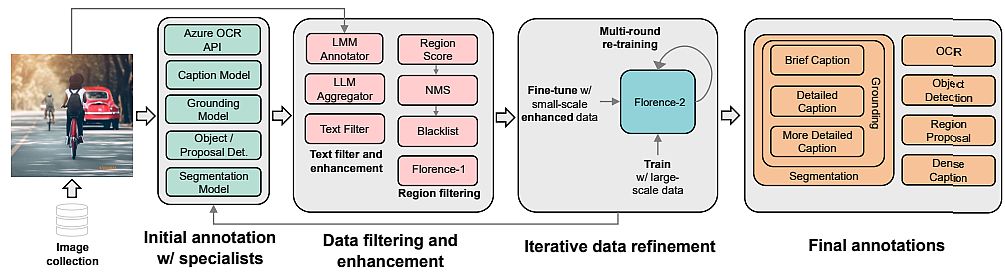
Data Engine in Florence-2
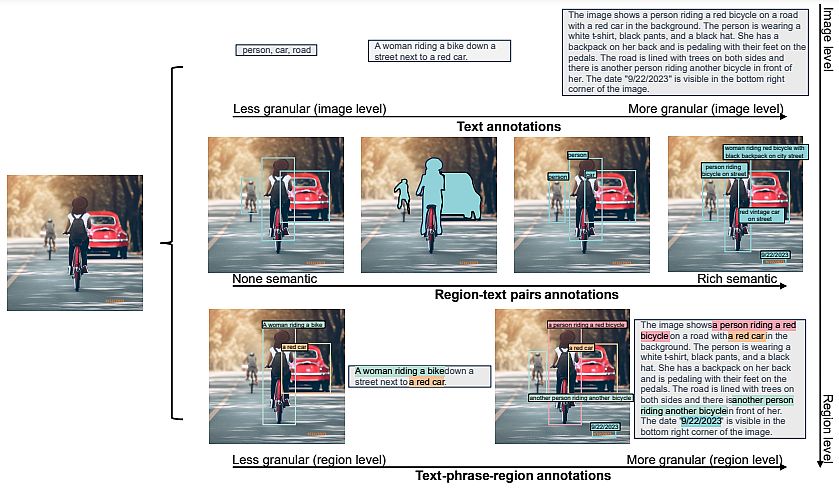
To train their Florence-2 architecture, researchers applied a unified, large-volume, multitask dataset containing different image data aspects. Because of the lack of such data, they have developed a new multitask image dataset.
Technical Challenges in the Model Development
There are difficulties with image descriptions because different images end up under one description, and in FLD-900M for 350 M descriptions, there is more than one image.
This affects the level of the training procedure. In standard descriptive learning, it is assumed that each image-text pair has a unique description, and all other descriptions are considered negative examples.
The researchers used unified image-text contrastive learning (UniCL, 2022). This Contrastive Learning is unified in the sense that, in a common image-description-label space, it combines two learning paradigms:
- Discriminative (mapping an image to a label, supervised learning) and
- Pre-training in an image-text (mapping a description to a unique label, contrastive learning).
The architecture has an image encoder and a text encoder. The feature vectors from the encoders’ outputs are normalized and fed into a bidirectional objective function. Additionally, one component is responsible for supervised image-to-text contrastive loss, and the second is in the opposite direction for supervised text-to-image contrastive loss.
The models themselves are a standard 12-layer text transformer for text (256 M parameters) and a hierarchical Vision Transformer for images. It is a special modification of the Swin Transformer with convolutional embeddings like CvT, (635 M parameters).
In total, the model has 893 M parameters. They trained for 10 days on 512 machines A100-40Gb. After pre-training, they trained Florence-2 with multiple types of adapters.
Experiments and Results
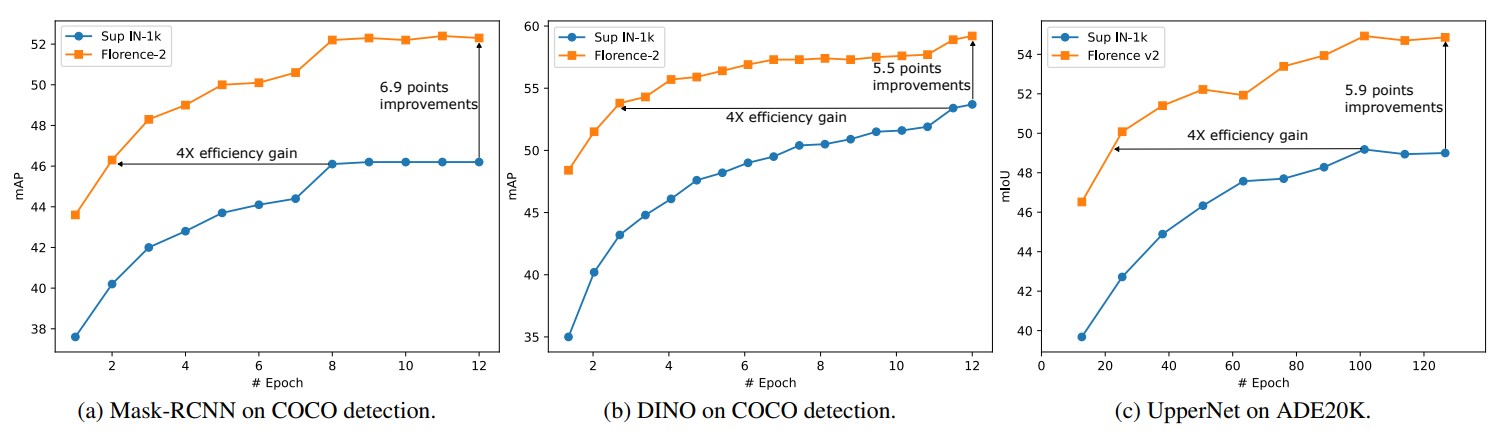
Researchers trained Florence-2 on finer-grained representations through detection. To do this, they added the dynamic head adapter, which is a specialized attention mechanism for the head that does detection. They did recognition with the tensor features, by level, position, and channel.
They trained on the FLOD-9M dataset (Florence Object detection Dataset), into which several existing ones were merged, including COCO, LVIS, and OpenImages. Moreover, they generated pseudo-bounding boxes. In total, there were 8.9M images, 25190 object categories, and 33.4M bounding boxes.
This was trained on image-text matching (ITM) loss and the classic Roberto MLM loss. Then they also fine-tuned it for the VQA task and another adapter for video recognition, where they took the CoSwin image encoder and replaced 2D layers with 3D ones, convolutions, merge operators, etc.
During initialization, they duplicated the pre-trained weights from 2D into new ones. There was some additional training here where fine-tuning for the task was immediately done.
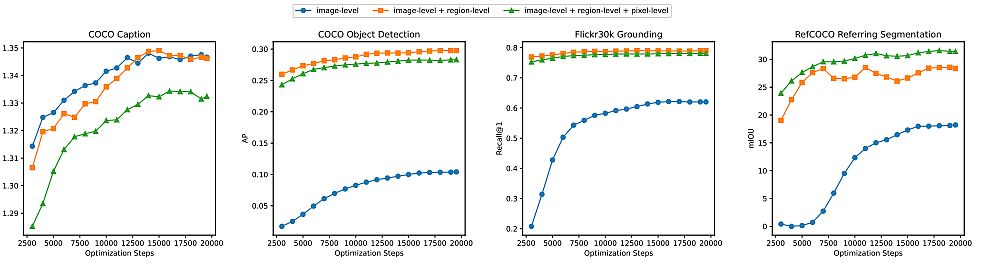
In fine-tuning Florence-2 under ImageNet, it is slightly worse than SoTA, but also three times smaller. For a few shots of cross-domain classification, it beat the benchmark leader, although the latter used ensemble and other tricks.
For image-text retrieval in zero-shot, it matches or surpasses previous results, and in fine-tuning, it beats with a significantly smaller number of epochs. It beats in object detection, VQA, and video action recognition too.
Applications of Florence-2 in Various Industries
Combined text-region-image annotation can be beneficial in multiple industries, and here we enlist its possible applications:
Medical Imaging
Medical practitioners use imaging with MRI, X-rays, and CT scans to detect anatomical features and anomalies. Then they apply text-image annotation to classify and annotate medical images. This aids in the more precise and effective diagnosis and treatment of patients.
Florence-2, with its text-image annotation, can recognize patterns and locate fractures, tumors, abscesses, and a variety of other conditions. Combined annotation has the potential to reduce patient wait times, free up costly scanner slots, and enhance the accuracy of diagnoses.
Transport
Text-image annotation is crucial in the development of traffic and transport systems. With the help of Florence-2 annotation, autonomous cars can recognize and interpret their surroundings, enabling them to make correct decisions.

Annotation helps to distinguish different types of roads, such as city streets and highways, and to identify items (pedestrians, traffic signals, and other cars). Determining object borders, locations, and orientations, as well as tagging vehicles, people, traffic signs, and road markings, are crucial tasks.
Agriculture
Precision agriculture is a relatively new field that combines traditional farming methods with technology to increase production, profitability, and sustainability. It utilizes robotics, drones, GPS sensors, and autonomous vehicles to speed up entirely manual farming operations.
Text-image annotation is used in many tasks, including improving soil conditions, forecasting agricultural yields, and assessing plant health. Florence-2 can play a significant role in these processes by enabling CV algorithms to recognize particular indicators like human farmers.
Security and Surveillance
Text-image annotation utilizes 2D/3D bounding boxes to identify individuals or objects from the crowd. Florence-2 precisely labels the people or items by drawing a box around them. By observing human behaviors and putting them in distinct boundary boxes, it can detect crimes.

The cameras, together with labeled training datasets, can recognize faces. Cameras identify people in addition to vehicle types, colors, weapons, tools, and other accessories, which Florence-2 will annotate.
What’s Next for Florence-2?
Florence-2 sets the stage for the development of computer vision models in the future. It shows an enormous potential for multitask learning and the integration of textual and visual information, making it an innovative CV model. Therefore, it provides a productive solution for a wide range of applications without needing much fine-tuning.
The model is capable of handling tasks ranging from granular semantic adjustments to image understanding. By showcasing the efficiency of multiple sequence learning, Florence-2’s architecture raises the standard for complete representation learning.
Florence-2’s performances provide opportunities for researchers to go farther into the fields of multi-task learning and cross-modal recognition as we follow the rapidly changing AI landscape.
Read about other CV models here:
- Large Language Models: Technical Overview
- Large Action Models: Beyond Language, Into Action
- Xception Model: Analyzing Depthwise Separable Convolutions