
This article covers everything you need to know about image classification tasks in machine learning – identifying what an image represents. Today, the use of convolutional neural networks (CNN) is the state-of-the-art method for image classification.
We will cover the following table of contents:
- What Is Image Classification?
- How Does Image Classification Work?
- Image Classification Using Machine Learning
- CNN Image Classification (Deep Learning)
- Example Applications of Image Classification
Let’s get into it!
Why is Image Classification important?
We live in the era of data. With the Internet of Things (IoT) and Artificial Intelligence (AI) becoming ubiquitous technologies, as a society, we generate enormous data volumes. Differing in form, data could be speech, text, image, or a mix of any of these. In the form of photos or videos, images make up a significant share of global data creation.
AIoT, the combination of AI and IoT, enables highly scalable systems to leverage machine learning for distributed data analysis.

AI for Understanding Image Data
Since the vast amount of image data we obtain from cameras and sensors is unstructured, we depend on advanced techniques such as machine learning algorithms to analyze the images efficiently. Image classification problems are probably the most important part of digital image analysis. It uses AI-based deep learning models to analyze images with results that, for specific types of classification tasks, already surpass human-level accuracy (for example, in face recognition).

Since AI is computationally very intensive and involves the transmission of huge amounts of potentially sensitive visual information, processing image data points in the cloud comes with severe limitations. Therefore, there is a big emerging trend called Edge AI that aims to move machine learning (ML) tasks from the cloud to the edge. This allows moving ML computing close to the source of data, specifically to edge devices connected to cameras.
Performing machine learning for image recognition at the edge makes it possible to overcome the limitations of the cloud in terms of privacy, real-time performance, efficacy, robustness, and more. Hence, the use of Edge AI for computer vision makes it possible to scale image recognition applications in real-world scenarios.
Image Classification is the Basis of Computer Vision
The field of computer vision includes a set of main problems, such as image classification, localization, image segmentation, and object detection. Among those, we consider image classification to be the fundamental problem. It forms the basis for other computer vision problems.
Image classification applications are used in many areas. These include medical imaging, object identification in satellite images, traffic control systems, brake light detection, machine vision, and more. To find more real-world applications of image classification, check out our extensive list of AI vision applications.

What is Image Classification?
Image classification categorizes and assigns class labels to groups of pixels or vectors within an image, dependent on particular rules. The categorization law can be applied through one or multiple spectral or textural characterizations.
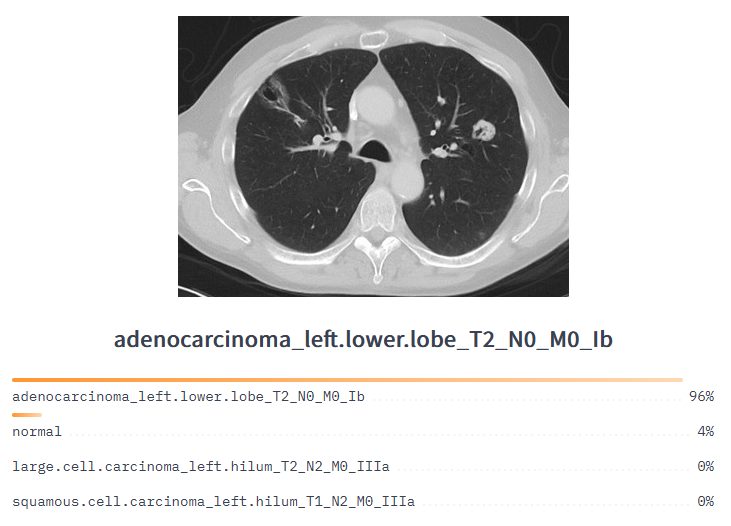
Image classification techniques are mainly divided into two categories: Supervised and unsupervised image classification techniques.
Unsupervised Classification
An unsupervised classification technique is a fully automated method that does not leverage training data. This means machine learning algorithms are used to analyze and cluster unlabeled datasets by discovering hidden patterns or data groups without the need for human intervention.
With the help of a suitable algorithm, the particular characterizations of an image are recognized systematically during the image processing stage. AI pattern recognition and image clustering are two of the most common image classification methods used here. Two popular algorithms used for unsupervised image classification are ‘K-means’ and ‘ISODATA.’
- K-means is an unsupervised classification algorithm that groups objects into k groups based on their characteristics. It is also called “clusterization.” K-means clustering is one of the simplest and very popular unsupervised machine learning algorithms.
- ISODATA stands for “Iterative Self-Organizing Data Analysis Technique.” It is an unsupervised method used for image classification. The ISODATA approach includes iterative methods that use Euclidean distance as the similarity measure to cluster data elements into different classes. While the k-means assumes that the number of clusters is known a priori (in advance), the ISODATA algorithm allows for a different number of clusters.
Supervised Classification
Supervised image classification methods use previously classified reference samples (the ground truth) to train the classifier and subsequently classify new, unknown data.
Therefore, the supervised classification technique is the process of visually choosing samples of training data within the image and allocating them to pre-chosen categories, including vegetation, roads, water resources, and buildings. This is done to create statistical measures to be applied to the overall image.
Image Classification Methods
Two of the most common methods to classify the overall image through training datasets are ‘maximum likelihood’ and ‘minimum distance.’ For instance, ‘maximum likelihood’ classification uses the statistical traits of the data where the standard deviation and mean values of each textural and spectral indices of the picture are analyzed first.
Later, the likelihood of each pixel to separate classes is calculated using a normal distribution for the pixels in each class. Moreover, a few classical statistics and probabilistic relationships are also used. Eventually, the pixels are marked to a class of features that show the highest likelihood.
How Does Image Classification Work?
A computer analyzes an image in the form of pixels. It does it by considering the image as an array of matrices, with the size of the matrix dependent on the image resolution. Put simply, image classification in a computer’s view is the analysis of this statistical data using algorithms. In digital image processing, image classification is done by automatically grouping pixels into specified categories, so-called “classes.”
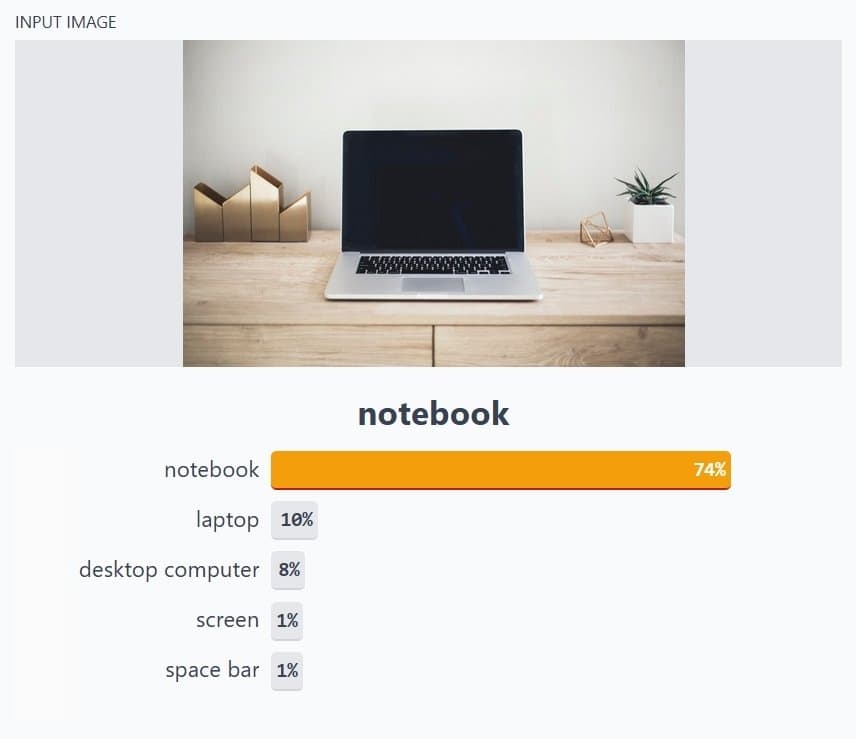
The algorithms segregate the image into a series of its most prominent features, lowering the workload on the final classifier. These characteristics give the classifier an idea of what the image represents and what class it might be classified into. The characteristic extraction process is the most important step in categorizing an image. The rest of the steps in the process depend on this extraction process.
Image classification, particularly supervised classification, is also reliant hugely on the data fed to the algorithm. A well-optimized classification dataset works great in comparison to a bad dataset with data imbalance based on class and poor quality of images and image annotations.

Image Classification Using Machine Learning
Image recognition with machine learning leverages the potential of algorithms to learn hidden knowledge from a dataset of organized and unorganized samples (Supervised Learning). The most popular machine learning technique is deep learning, where a lot of hidden layers are used in a model.
Recent Advances in Image Classification
With the advent of deep learning, in combination with robust AI hardware and GPUs, outstanding performance can be achieved on image binary classification tasks. Hence, deep learning brought great success in the entire field of image recognition, face recognition, and image classification algorithms to achieve above-human-level performance and real-time object detection.
Additionally, there’s been a huge jump in algorithm inference performance over the last few years.
- For example, in 2017, the Mask R-CNN algorithm was the fastest real-time object detector on the MS COCO benchmark, with an inference time of 330 ms per frame.
- In comparison, the YOLOR algorithm released in 2021 achieves inference times of 12 ms on the same benchmark, thereby overtaking the popular YOLOv3 and YOLOv4 deep learning algorithms.
- The releases of YOLOv7 (2022), YOLOv8 (2023), and YOLOv9 (2024) marked a new state-of-the-art that surpasses all previously known models, including YOLOR, in terms of speed and accuracy.
- With the Segment Anything Model (SAM), Meta AI released a new top performer for image instance segmentation. The SAM produces high-quality object masks from input prompts.

Advantages of Deep Learning vs. Traditional Image Processing
In comparison to the conventional computer vision approach in early image processing around two decades ago, deep learning requires only the knowledge of the engineering of a machine learning tool. It doesn’t need expertise in particular machine vision areas to create handcrafted features.
In any case, deep learning requires manual data labeling to interpret good and bad samples. This is image annotation. Supervised learning is the process of gaining knowledge or extracting insights from data labeled by humans.
The process of creating such labeled data to train AI models needs tedious human work, for instance, to annotate regular traffic situations in autonomous driving. However, nowadays, we have large datasets with millions of high-resolution labeled data of thousands of categories, such as ImageNet, LabelMe, Google OID, or MS COCO.

CNN Image Classification
Image classification is the task of categorizing images into one or multiple predefined classes. Although the task of categorizing an image is instinctive and habitual to humans, it is much more challenging for an automated system to recognize and classify images.
The Success of Neural Networks
Among deep neural networks (DNN), the convolutional neural network (CNN) has demonstrated excellent results in computer vision tasks, especially in image classification. Convolutional Neural Networks (CNNs) are a special type of multi-layer neural network inspired by the mechanism of human optical and neural systems.
In 2012, a large deep convolutional neural network called AlexNet showed excellent performance on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). This marked the start of the broad use and development of convolutional neural network models (CNN) such as VGGNet, GoogleNet, ResNet, DenseNet, and many more.
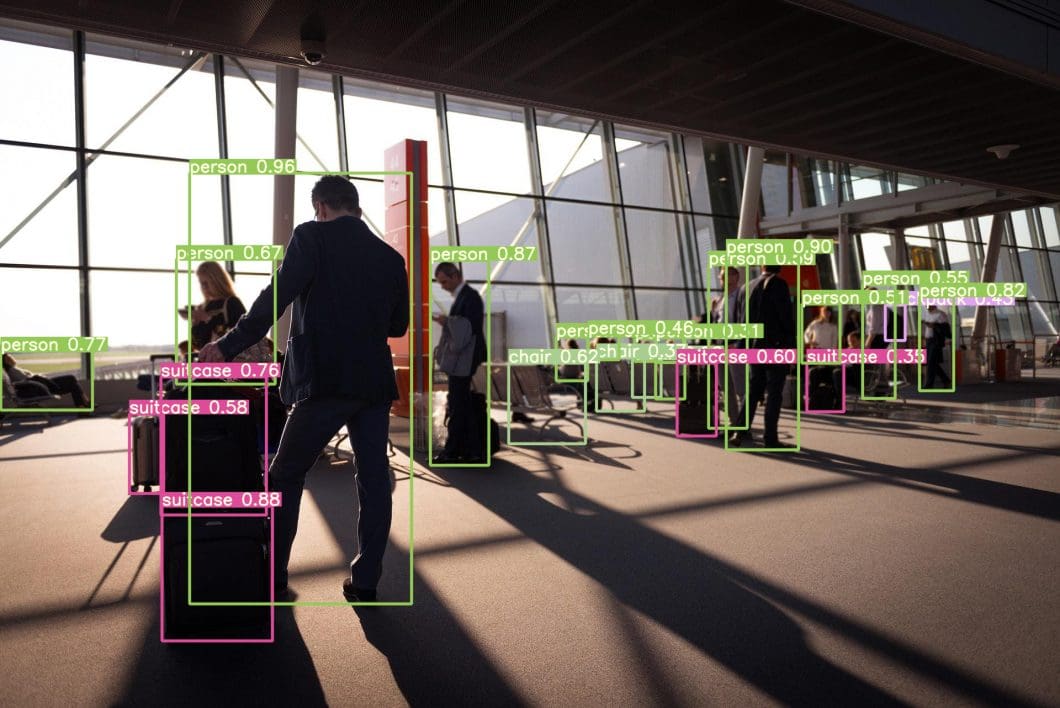
Convolutional Neural Network (CNN)
A CNN is a framework developed using machine learning concepts. CNNs can learn and train from data on their own without the need for human intervention.
There is only some pre-processing needed when using CNNs. They develop and adapt their image filters, which have to be carefully coded for most algorithms and models. CNN frameworks have a set of layers that perform particular functions to enable CNN to perform these functions.
CNN Architecture
The basic unit of a CNN framework is a neuron. The concept of neurons is based on human neurons, where synapses occur due to neuron activation. These are statistical functions that calculate the weighted average of inputs and apply an activation function to the result generated. Layers are a cluster of neurons, with each layer having a particular function.
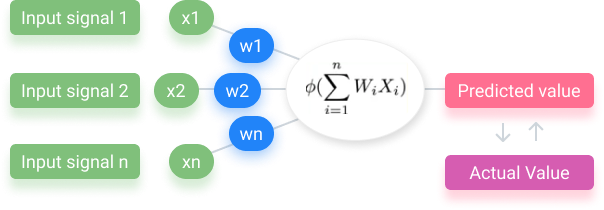
CNN Layers
A CNN system may have somewhere between 3 to 150 or even more layers: The “deep” of Deep neural networks refers to the number of layers. One layer’s output acts as another layer’s input. Deep multi-layer neural networks include ResNet50 (50 layers) or ResNet101 (101 layers).
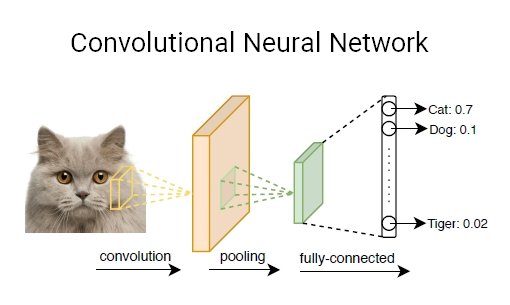
CNN layers can be of four main types: Convolution Layer, ReLU Layer, Pooling Layer, and Fully-Connected Layer.
- Convolution Layer: A convolution is the simple application of a filter to an input that results in an activation. The convolution layer has a set of trainable filters that have a small receptive range but can be used to the full depth of data provided. Convolution layers are the major building blocks used in convolutional neural networks.
- ReLU Layer: ReLU layers, or Rectified Linear Unit layers, are activation functions for lowering overfitting and building CNN accuracy and effectiveness. Models that have these layers are easier to train and produce more accurate results.
- Pooling Layer: This layer collects the result of all neurons in the layer preceding it and processes this data. The primary task of a pooling layer is to lower the number of considered factors and give streamlined output.
- Fully-Connected Layer: This layer is the final output layer for CNN models that flattens the input data received from layers before it and gives the result.
Applications of Image Classification
Some years ago, security applications arose as the primary use cases of image classification. But today, applications of image classification are becoming important across a wide range of industries, use cases are popular in health care, industrial manufacturing, smart cities, insurance, and even space exploration.
One reason for the surge of applications is the ever-growing amount of visual data available and the rapid advances in computing technology. Image classification is a method of extracting value from this data. Used as a strategic asset, visual data has equity as the cost of storing and managing it is exceeded by the value realized through applications throughout the business.
There are many applications for image classification; popular use cases include:
- Application #1: Automated inspection and quality control
- Application #2: Object recognition in driverless cars
- Application #3: Detection of cancer cells in pathology slides
- Application #4: Face recognition in security
- Application #5: Traffic monitoring and congestion detection
- Application #6: Retail customer segmentation
- Application #7: Land use mapping
Image Classification Example Use Cases
Automated inspection and quality control: Image classification can automatically inspect products on an assembly line. Automated systems can identify and remove those that do not meet quality standards.

Object recognition in driverless cars: Driverless cars need to be able to identify multiple objects on the road to navigate safely. Image classification is useful for this purpose.
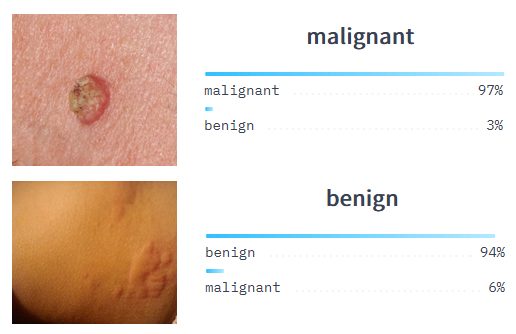
Classification of skin cancer with AI vision: Dermatologists examine thousands of skin conditions looking for malignant tumor cells. We can automate this time-consuming task using image classification.
Face recognition in security: When looking at uses of computer vision in airports, image classification can automatically identify people from security footage, for example, to perform face recognition.
Traffic monitoring and congestion detection: Image classification can automatically count the number of vehicles on a road, and detect traffic jams.
Retail customer segmentation: Image classification can automatically segment retail customers into different groups based on their behavior, such as those who are likely to buy a product.
Land use mapping: Image classification can automatically map land use, for example, to identify areas of forest or farmland. There, it can also monitor environmental change, for example, to detect deforestation or urbanization, or for yield estimation in agriculture use cases.
The Bottom Line
Researchers understand that leveraging AI, particularly CNNs, is a revolutionary step forward in image classification. Since CNNs are self-training models, their effectiveness only increases as they are fed more data in the form of annotated images (labeled data).
With that in mind, you will want to image classification with CNNs if your company depends on image classification and analysis.
What’s Next for Image Classification?
Today, convolutional neural networks (CNNs) mark the current state of the art in AI vision. Recent research has shown promising results for the use of Vision Transformers (ViT) for computer vision tasks. Read our article about Vision Transformers (ViT) in Image Recognition.
Check out our related blog articles about related computer vision tasks, AI deep learning models, and image recognition algorithms.