It’s only a matter of time until Computer Vision and Deep Learning will surpass human vision. In some areas, such as in the medical field, this has already happened: artificial intelligence (AI) can detect breast cancer with higher accuracy than humans.
However, implementing computer vision to easily solve business challenges is not as straightforward as it may seem. In this article, we will be looking into two grave reasons why Computer Vision projects fail – and how to overcome these challenges.
The Value of Computer Vision
Computers can analyze video streams in real time, turn them into variables, and apply logic workflows to solve complex visual problems.
Based on AI, a computer can solve visual problems such as counting objects or recognizing a visual shape (Object Detection) at much higher precision and speed than humans. Also, a computer can quickly and autonomously repeat such a task as many times as needed. This is the basis of a wide range of real-world computer vision applications across multiple industries.
There are many situations where a computer can complete a visual task better than humans, with higher consistency and precision. The advantages are pretty much the same as with the automation of any manual task.
Hence, it’s not surprising that many businesses in offline industries could potentially make use of computers that increase the quality of their product or service and/or save costs in their operations. However, some big pitfalls come with the real-world use of Computer Vision and visual AI in general.
Problem One: The Objects are Not Visible
As simple as it sounds, AI vision is not magic and cannot overcome physics. A problem that deals with things that are not visible cannot be solved using Computer Vision. A computer’s ability to “see” can only be as good as the image quality of the underlying camera images and videos, or even video streams.
Some time ago, I worked on a remote monitoring project where dogs were counted using machine learning algorithms. Unfortunately, because some of the dogs’ fur was of the same color as the floor, they were “invisible” to the camera and the AI.
The solution to such situations is fairly simple; either the camera angle or the scene needs to change to ensure the objects are visible. In some cases where this is not possible, sophisticated workflows can be set up to count objects over time. This makes sense if either the scene or the objects change and become visible over time.

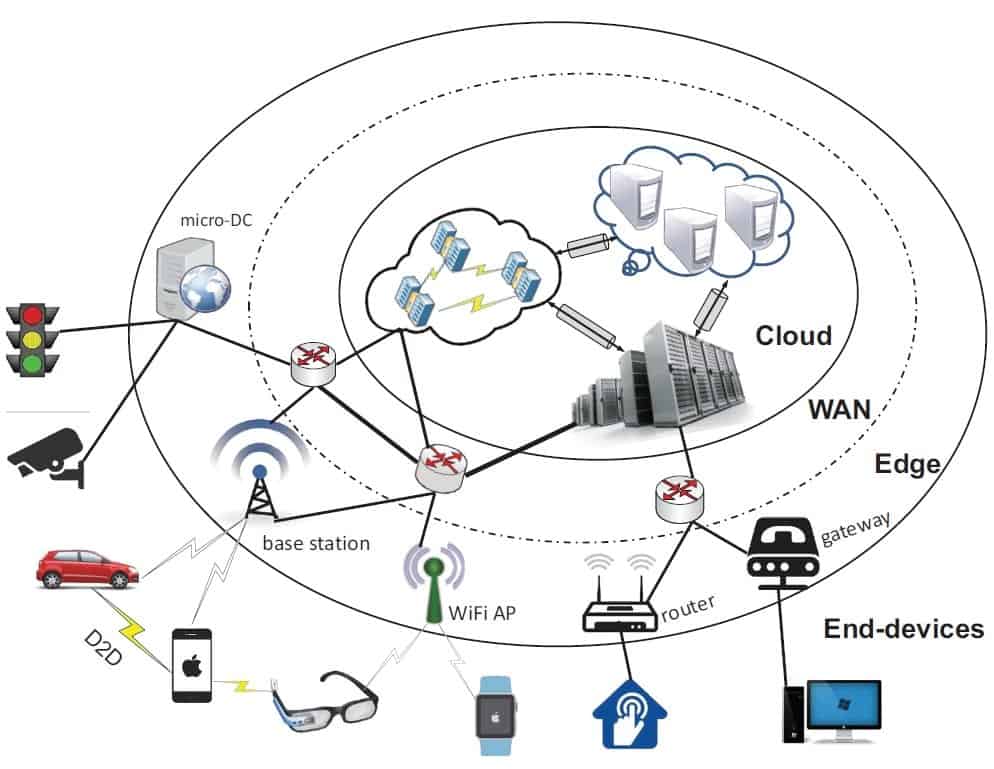
Problem Two: Cloud Computing is Not Enough
For many AI vision applications, the traditional cloud computing model is not suitable. Cloud-driven computer vision systems need a constant internet connection, require communication time leading to latency issues, and often come with privacy concerns related to data offloading. Therefore, machine learning algorithms are deployed to the edge device (Edge AI), where the data is generated in a resource-constrained environment (power usage, computing hardware).
With AI moving from the cloud to the edge, the main challenge is no longer finding an algorithm to do something but achieving an efficient setup, especially since numerous Computer Vision Libraries and Deep Learning Frameworks have recently been open-sourced.
The accuracy and latency of Computer Vision tasks depend on the availability of computational resources. Therefore, more accurate computer vision models (for example, Mask R-CNN) tend to consume significantly more resources.
Especially in high-scale AI vision solutions, this matters greatly. Achieving similar results with lower-grade hardware means cost savings that quickly go to the millions. Unfortunately, many visual AI solutions are not viable in production because they rely on a very “heavy” ( computationally intensive) model that requires expensive hardware such as GPUs. Thus, the economic benefit achieved would not make up for the costs that come with such a setup.
The Landscape is Improving
But I have good news for you! As computing costs drastically decline year by year, computers not only get more powerful but also cheaper. Hence, machine learning models considered to be “heavy” can be used more broadly, and switching the hardware to use modern AI accelerators can result in great performance gains.
If waiting or exchanging the AI hardware is not an option, there is much you can do. Many visual problems can be solved by drastically reducing the Frames per Second (FPS). If you, for example, count static objects, much higher precision can be achieved by processing only 1 frame or less per second. As surprising as it may seem, the perceived quality of the application could be much higher.

Avoid Common Pitfalls and Improve Computer Vision Projects With Viso Suite
Viso Suite infrastructure offers an end-to-end, fully customizable solution for the success of computer vision applications. With advanced capabilities and a visual interface, the development, deployment, and management of computer vision applications means that organizations can achieve project goals efficiently and effectively.
If you want to learn more about the basics of Computer Vision, we recommend you read the following articles:
- What is Computer Vision? Learn what Computer Vision is (not technical).
- Explore a list of popular Computer Vision applications today.
- Learn about the 5 most popular Deep Learning Frameworks.
- Read about self-supervised learning of machines.
- Understand how to evaluate model performance
- Three Types of Deep Neural Networks (MLP, CNN, RNN)
- A deep dive into Convolutional Neural Networks (CNN)