This comprehensive guide aims to help businesses navigate the costs of computer vision, one of the most powerful technologies of the century. We provide a high-level technology overview and strategies for saving costs and improving the cost-efficiency of computer vision applications.
Therefore, we will discuss the key drivers of computer vision costs and how to calculate or estimate the cost of AI vision technology. The goal of this guide is to help teams quantify and compare the pricing of different computer vision software alternatives and platforms.
Explore Viso Suite
Enterprise AI demands enterprise-grade solutions. See how Viso Suite enables large-scale computer vision operations.
Computer vision is a set of technologies to make computers see and understand visual images by applying algorithms. In recent years, machine learning, in particular deep learning, has seen great success due to high performance and accuracy in image recognition tasks.
The ability to automate human sight with computers opens up massive opportunities and use cases across every sector of the economy. For example, in security use cases, computer vision is used to analyze video footage in real-time to detect intrusion events faster and much more efficiently than human operators who need to permanently stare at walls of video monitors. In industrial manufacturing, machine vision systems apply AI vision inspection to detect product damage, count items, or detect events early that would cause costly business disruptions or accidents.
While computer vision is one of the most powerful AI technologies today, it has been a field of research since the 1960s. Early computer vision methods focused on pixel-based algorithms to analyze images and recognize patterns based on manually defined features.
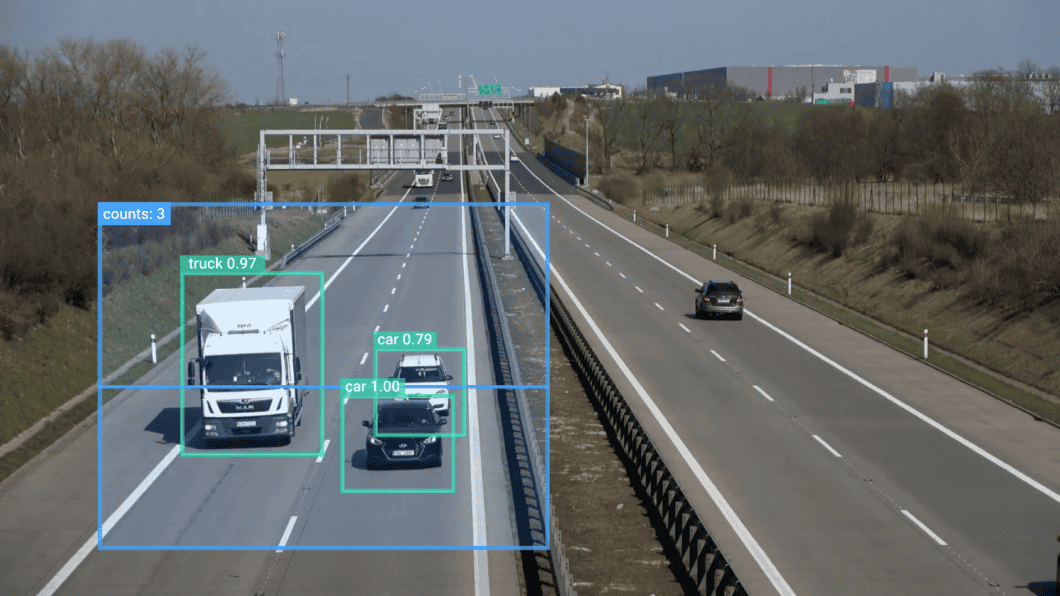
Years later, in the 2010s, deep learning showed great results in computer vision by applying multiple hidden layers as part of neural networks. Until today, deep learning provides the best detection results in computer vision challenges, with YOLOv7 achieving the best results.
Computer vision with the deep learning model YOLOv7 – built on Viso Suite
However, Artificial Intelligence is computationally complex and requires significant processing resources. The new Cloud technologies provided a way to find the enormous server capacities needed for AI model training and inferencing. With the Internet of Things (IoT), the data volume gathered by millions of sensors grows massively. With the unprecedented amount of data from live streaming and connected devices, advanced computing and AI are needed to make sense of this amount of data (AIoT).
While Cloud Computer Vision APIs are an easy way to make resources available, sending all data to the Cloud and processing it there is not very efficient and comes with drawbacks. Hence, the Cloud requires a constant internet connection, expensive communication costs, latency, privacy, and bottleneck risks – all impact costing and scalability.
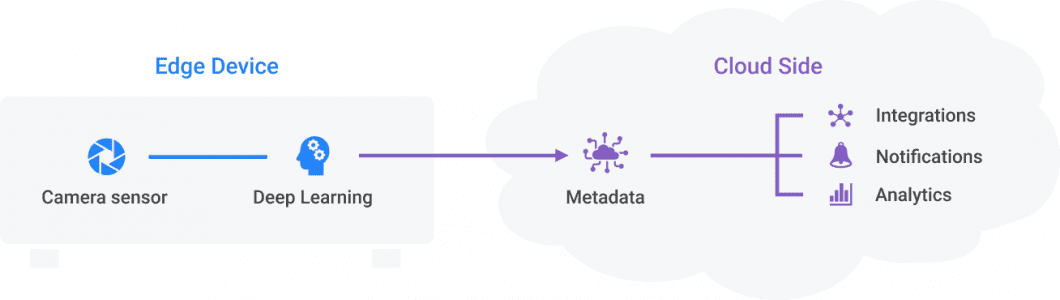
Therefore, the concept of Edge AI was introduced, which leverages Edge Computing. This shifts AI tasks from the Cloud to the network edge, closer to where data is generated. In practice, cameras are connected to an edge device, and a machine learning model runs on-device to process images or videos in real time. The main challenges are managing both hardware and AI software and the resource constraints of the edge device.
The concept of Edge AI with decentralized processing of visual data
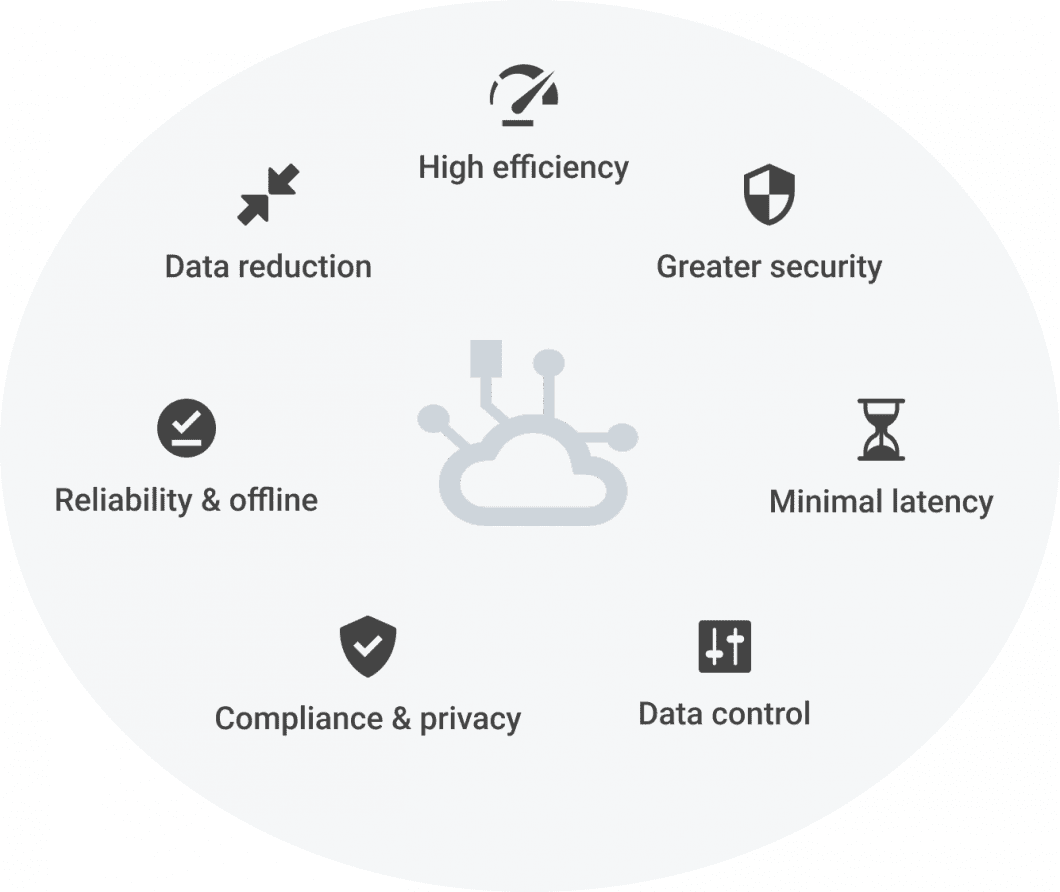
Edge AI, or Intelligent Edge, plays an important role in applying computer vision and deploying it as real-world applications. The decentralized approach is much more efficient, allows real-time performance, allows privacy-preserving image analysis without sending or storing image data, and can still run in offline situations. Popular examples include connected vehicles or smart factories.
AI vision is a highly disruptive emerging technology with great potential for competitive advantages. Most computer vision applications are highly specific and seek to solve high-value business problems, increase efficiency, or generate new revenues.
In the early stages and to get started with computer vision, companies often relate to ready-made turnkey computer vision products. This usually changes when computer vision becomes a strategic issue, and the technology is expected to deliver high value mid and long term. From this point in time, most businesses conclude that they need to build their computer vision systems.
Firstly, most computer vision systems need to be specific and customized toward the business case to deliver maximum value and optimize the costs. Companies need to fully integrate AI vision into existing infrastructure (cameras, network, software systems) and avoid technology lock-ins. Also, most businesses will need multiple and different applications. Using different turnkey products causes overlaps and the risk of isolated technology silos.
As computer vision provides a strategic advantage, a company needs full control of the application design and data model. Most applications involve sensitive image data (IP, private information). With constantly changing regulations and advancing technology, the agility to modify and update AI vision applications is critical for long-term success.
In short, the more value a computer vision application provides, the more a company needs to fully control and build its computer vision technology. That’s why you see companies across industries hire machine learning and computer vision engineers.
The True Cost
Since computer vision is an emerging technology, there are no agreed-upon conventions for how to measure the costs of AI vision. In computer vision research literature, low-cost computer vision refers to a wide range of what is considered expensive (from a GPU to a data center).
It isn’t easy to compare the cost of different computer vision platforms because of the high variability in terms of functionality. If a software product does not provide infrastructure or requires additional products, we must also assess those costs. Missing features and additional integrations can lead to unexpected expenses. Especially security and privacy capabilities are expensive yet critical for success.
The architectural design and infrastructure greatly determine the total costs of an AI application. For example, there is a vast difference between analyzing a few images per minute in a web application and always-on computer vision systems that process one or multiple video streams in real time. Therefore, it is crucial to differentiate between a simple prototype and a sophisticated business application.
Is Computer Vision Expensive?
Computer vision involves image processing, a very resource-intensive and complex task. Usually, it is not the cameras but the powerful processors and complex software that drive the costs of image recognition. As an emerging AI technology, those highly knowledgeable about computer vision are hard to find. Therefore, highly paid engineers with production experience, AI consultants, and solution architects. Even a small team can quickly cost over a million USD per year.
The entire goal of computer vision is efficiency; it is about achieving the maximum performance required for an application at minimal cost. If the costs of computer vision are too high, there is no business case. The lower the technological costs are, the more business applications become economically viable.
Why Costs Kill Computer Vision Projects
While testing and prototyping, pricing and cost-efficiency are often not the main concern. This leads to inefficient and expensive setups that would never scale, either because the components or infrastructure are too expensive or because assumptions on developer costs and maintenance are too optimistic.
If business leaders focus solely on the excitingAI vision part – algorithms and deep learning models – we see that teams neglect or underestimate the difficulty of deployment, monitoring, and maintaining a system. And many computer vision applications never make it to production. This is because the shift from optimal assumptions in the lab to the real-world setting is where it gets challenging – and expensive.
Infrastructure Cost of Cloud vs. Edge
One of the most significant cost factors of computer vision is the infrastructure technology for running AI inference and scaling AI vision applications. We’ve discussed the two main concepts above – Cloud and Edge AI – while Edge AI combines Cloud with distributed on-device computing. In the following, we will walk through the benefits and challenges of the two infrastructure types.
Cost of Cloud API Computer Vision
Cloud-based methods use APIs to send individual images to a remote server in the Cloud and process the data there. Computer vision APIs are a fast and easy way to develop software with computer vision capabilities. However, the software itself does not execute AI vision tasks. Popular Computer Vision APIs include AWS Rekognition, Azure Cognitive Services, and Google Cloud AI Vision.
Cloud-based computer vision uploads each image or camera frame to a cloud server and then applies the deep learning model using the GPU resources of the data center. Then the metadata (results, e.g., detected classes) is sent with the API response. The data-offloading, despite hashing and no permanent storage, is often a red flag for companies that don’t allow sending or storing video data containing Intellectual Property (IP) or private information in the Cloud for legal reasons. The centralized cloud approach comes with unavoidable latency and communication costs and the risk of bottlenecks that lead to cost spikes. This requires constant internet connectivity for the system to run.
The cost of cloud-based computer vision is often difficult to estimate because of complex and dynamic pricing models. APIs often have a free budget for low-volume testing and small prototypes. However, costs can go up rapidly, and poorly designed applications may lead to huge usage spikes.
Some APIs charge per unit, per detection, per label, per frame, or have other limits such as frames per second (FPS). Most computer vision applications require a combination of different AI vision tasks. For example, facial recognition requires (1) face detection in combination with (2) classification to match the face with a database. Or number plate recognition (1) detects the vehicle, (2) locates the number plate, and (3) reads the plate (OCR). This means that more accurate or efficient application designs double or multiply the API costs of an application.
Computer vision APIs are useful for applications that involve low bandwidth and web-based image analysis. Cloud-based AI vision is challenging to scale and apply for AI video analysis in real-world applications. Its use is very limited for mission-critical and business applications.
Cost of Edge AI Computer Vision
Edge AI methods leverage Edge Computing to run machine learning on physical computers or servers connected to a network. The data from cameras is processed immediately, without the need to store or send video data. Edge systems can run despite internet connection interruptions without losing data (edge-side buffer). The decentralized approach is highly scalable; edge endpoints can be added or stopped without affecting the other endpoints.
The cost of edge-based computer vision is primarily driven by hardware costs. However, those one-time costs of edge hardware are usually significantly lower compared to equivalent cloud costs and are easier to calculate. Technically, any computer or embedded server can be an edge device. We can run the applications on standard CPU or GPU processors or specialized AI accelerators (VPU, TPU, etc.), easily connectable using conventional interfaces (PCIe, USB, etc.).
The big challenges of Edge AI are (1) the limited hardware resources per device and (2) the software to manage hardware efficiently. Edge Computing and IoT communication make Edge AI much more challenging to implement and maintain than web applications.
The Main Cost Drivers
Balancing Accuracy and Speed
Computer vision technology advances rapidly, and newer techniques and deep learning models likely outperform older ones. However, computer vision algorithms have different goals in mind, and it is vital to choose an algorithm suitable for specific tasks.
Certain deep neural networks are optimized for high accuracy by combining multiple processing steps (e.g., R-CNN, ResNet). Meanwhile, other deep learning models are useful for high inference speed requirements and, therefore, more lightweight (e.g., SSD, YOLO algorithms).
In simple words, complex models tend to be heavier and require more computing resources. This requires a stronger GPU or CPU. Heavy models are also large (tens of GB storage) and usually not suitable for mobile deployment. With the importance of deep learning on mobile devices, there are great advances in making models lightweight (see TensorFlow Lite or OpenPose Lite).
Keypoint estimation of human pose with OpenPose
AI model optimization shrinks the model size and increases resource efficiency, therefore significantly lowering the total costs.
Computer Vision Application Design
In computer vision applications, the algorithm is only one part of the entire system. For example, in an application to count people in a video stream, a camera provides the video input at 25 frames per second (FPS). The computer vision application fetches and feeds those images into a deep-learning model. The AI model processes the images using the available computing resources (GPU, CPU, VPU processors).
More powerful processing hardware allows processing more frames per second, usually in a range between 1-30 FPS. This is the rate at which information is generated (e.g., the people count per interval) that can be visualized in a dashboard or BI tool (Grafana, Power BI, Tableau, etc.).
Depending on the use case, achieving more frames per second is not always beneficial. This may indicate an inefficient application design and cost-saving potential. All system components must be well-balanced to achieve the required performance at minimal resource input (measured at FPS/Watt, or FPS/$).
The goal of an efficient computer vision application design is to achieve similar application results with lower-cost hardware. Another way to save costs is to process multiple camera streams with fewer computing resources per stream.
How To Lower the Costs of Computer Vision
Since the cost of computer vision is based on a mix of factors, it is an optimization problem with bottlenecks that could multiply the overall costs. The following strategies provide general steps you can take to make computer vision systems more cost-efficient.
Run computer vision at the edge. For scalable, low-latency, or mission-critical systems and business applications, it is much more cost-efficient to run deep learning on edge devices (Edge AI) compared to operating Cloud APIs.
Use a next-generation deep learning model. It’s important to use an up-to-date machine learning framework because optimizing a legacy framework would be highly inefficient. For example, there are big leaps in real-time object detection performance, the YOLOv3 and YOLOR algorithms achieved dramatically faster AI inferencing times at comparable accuracy (from 333ms to 29ms per frame). Use an agile development platform that allows replacing the AI model and framework of applications over time.
Update application design and logic. There are unlimited ways to solve a computer vision problem, and optimizing the application design will greatly increase the application performance and allow running on lower-cost hardware. Powerful tools include intelligent if-then logic, loops, multi-threading, buffering, edge load balancing, etc.
Use image pre-processing. We see ML engineers directly loading camera files into a deep learning model. Here, image pre-processing methods must optimize and standardize all images before entering a deep learning model. This includes lighting, cropping, rotating, sharpening, etc. As a result, the same model achieves significantly better accuracy and/or faster inference speed.
Use a cross-platform solution. Avoid depending on one specific ML platform or hardware manufacturer. The ability to use and exchange cross-platform hardware and software is critical to avoid sunk costs in the long term.
Use drag-and-drop software interfaces. Accelerate application delivery by dramatically reducing the amount of manual coding. Visual programming makes building, deploying, and updating much faster, reduces risk, and facilitates the collaboration of IT and business teams.
Focus on security and privacy. Security or privacy issues can lead to enormous costs. And implementing security is one of the most difficult and expensive aspects of enterprise AI vision. Ensure to run computer vision on hardened and monitored infrastructure, and encrypt all data and communication. Edge AI allows running private computer vision but also requires secure endpoint management, hardening, and monitoring.
Computer vision is very complex and requires the integration of different Machine Learning Platforms, Cloud, Edge Computing, IoT Communication, and image processing. The problem is the vast amount of fragmented tools and platforms that need to be integrated and updated. Using standard programming methods, teams often end up with hard-to-maintain spaghetti code. With complexity increasing over time, the applications become brittle and difficult to maintain and secure.
This is why we have built a computer vision platform to rapidly build, deploy, and maintain applications in one interface.
Save development costs with a model-driven architecture to build computer vision with building blocks in a visual editor.
Build highly cost-efficient AI vision systems that scale to hundreds of locations and cameras.
Powerful, built-in security and privacy capabilities, enterprise-grade access management, and endpoint monitoring.