
One of the computer vision applications we are most excited about is the field of robotics. We are already seeing researchers and firms marrying computer vision, natural language processing, mechanics, and physics, thus changing how we interact with and are assisted by robot technology.
Computer Vision vs. Robotics Vision vs. Machine Vision
Before we get into all of the ways robotics is being used today, let’s quickly go over the technology making these real-world applications possible.
Computer Vision
A branch of artificial intelligence and machine learning, computer vision enables machines to interpret and act on visual data. Beyond simply “seeing,” it allows systems to recognize objects, people, and environments to best understand spatial relationships and context, much like human vision. Modern computer vision can process images and live video in real time to detect objects, using depth and motion to perceive distance, position, and change.
Robotic Vision
Robotic vision applies computer vision to robotics, allowing robots to perceive and interact with their surroundings. By turning visual data into actions, robots can navigate autonomously, identify objects, and adapt to complex environments, such as disaster zones or dynamic worksites.
Machine Vision
Machine vision uses similar technology but focuses on inspection, measurement, and process control in industrial settings. It guides operational decisions, such as detecting product defects or sorting materials on an assembly line, prioritizing precision and repeatability over autonomy.
In essence, computer vision provides the foundation, robotic vision brings perception to movement, and machine vision brings intelligence to precision. Together, they represent the core of next-generation physical AI systems.

Applications of Computer Vision in Robotics
Interpretation of visual feedback is essential for robots performing tasks. The power of sight is one of the elements powering industrial automation and the adoption of this new technology across different disciplines. We already have many examples in the robotics industry, including:
Space
Robots equipped with computer vision systems are increasingly playing a pivotal role in space operations. NASA’s Mars rovers, such as Perseverance, utilize computer vision to autonomously navigate the Martian terrain. These systems analyze the landscape to detect obstacles, analyze geological features, and select safe paths.
They also use these tools to collect data and images to send back to Earth. Robots with computer vision will be the pioneers of space exploration, where a human presence is not yet feasible.
Industrial
Industrial robots with vision capabilities are transforming production lines and factories. Robots can identify parts, figure out their positioning, and accurately place them. They do tasks like assembly and quality control.
For example, automotive manufacturers use vision-guided robots to install windshields and components. These robots operate with a high degree of accuracy, improving efficiency and reducing and reducing the risk of errors.

Food and beverage manufacturers increasingly use robotics for automated food classification and grading. A clear example is potato processing: after harvesting, potatoes must be rapidly sorted to remove those that don’t meet quality standards, such as green potatoes, which can be toxic to humans. Using vision-guided robotic systems, each potato is scanned in real time, and those that fail inspection are quickly diverted mid-air into a separate bin. The result is a highly efficient process that ensures only safe, high-quality potatoes are packaged and distributed for consumption.
Aerospace and Defense
Robotics provides capabilities for reconnaissance, surveillance, and search and rescue missions. Unmanned Aerial Vehicles (UAVs), or drones, use computer vision to navigate and identify targets or areas of interest. They use these capabilities to execute complex missions in hostile or inaccessible areas while minimizing the risk to personnel. We have seen this in the General Atomics’ Aeronautical MQ-9A “Reaper” and France’s Aarok.

Medical
Computer vision for healthcare can enhance the capabilities of robots to assist in or even autonomously perform precise surgical procedures. The da Vinci Surgical System uses computer vision to provide a detailed, 3D view of the surgical site. Not only does this aid surgeons in performing highly sensitive operations, but it can also help minimize invasiveness. Additionally, these robots can analyze medical images in real-time to guide instruments during surgery.
Warehousing and Distribution
In warehousing and distribution, businesses are always chasing more efficient inventory management and order fulfillment. Various types of robots equipped with computer vision can identify and pick items from shelves, sort packages, and prepare orders for shipment. Companies like Amazon and Ocado deploy these autonomous robots in fulfillment centers that handle vast inventories.
Agricultural
Computer vision in agriculture is applied to tasks like crop monitoring, harvesting, and weed control. These systems can identify ripe produce, detect and identify plant diseases, and target weeds with precision. Even after harvesting, these systems can help efficiently sort produce by weight, color, size, or other factors. This technology makes farming more efficient and is at the forefront of sustainable practices by reducing pesticides, for example.
Environmental Monitoring and Conservation
Environmental monitoring and conservation efforts are also increasingly relying on computer vision. Aerial and terrestrial use cases with robotics include: tracking wildlife, monitoring forest health, and detecting illegal activities, such as poaching. One example is the RangerBot, an underwater vehicle that uses computer vision to monitor the health of coral reefs. It can identify invasive species that are detrimental to coral health and navigate complex underwater terrains.
Challenges of Computer Vision
Moravec’s paradox encapsulates the challenge of designing robots capable of human-like capabilities. It holds that there are tasks humans find challenging that are easy for computers and vice versa. In robotic vision, it means doing basic sensory and motor tasks that humans take for granted.
For example, identifying obstacles and navigating a crowded room is trivial for toddlers but incredibly challenging for a robot.
Integrating computer vision into robot systems presents a unique set of challenges. These not only stem from the technical and computational requirements but also from the complexities of real-world applications. There’s also a strong push to develop both fully autonomous capabilities as well as to collaborate with a human operator.
For applications, the ability to respond to environmental factors in real-time is key to its usefulness. This may stunt adoption in these fields until researchers can overcome these performance-based hurdles.
1. Real-World Variability and Complexity
The variability, dynamism, and complexity of real-world scenes pose significant challenges. For example, lighting conditions or the presence of novel objects. Complex backgrounds, occlusions, and poor lighting can also seriously impact the performance of computer vision systems.
Robots must be able to accurately recognize and interact with a multitude of objects in diverse environments. This requires advanced algorithms capable of generalizing from training data to new, unseen scenarios.
2. Limited Contextual Understanding
Current computer vision systems excel at identifying and tracking specific objects. However, they don’t always understand contextual information about their environments. We are still in pursuit of a higher-level understanding that encompasses semantic recognition, scene comprehension, and predictive reasoning. This area remains a significant focus of ongoing research and development.
3. Data and Computational Requirements
Generalizing models requires massive datasets for training, which aren’t always available or easy to collect. Processing this data also demands significant computational resources, especially for deep learning models. Balancing real-time processing with high accuracy and efficiency is especially challenging. This is especially true as many applications for these systems are in resource-constrained environments.
4. Integration and Coordination
Integrating computer vision with other robotic systems—such as navigation, manipulation, and decision-making systems—requires seamless coordination. To accurately interpret visual data, make decisions, and execute responses, these systems must work together flawlessly. These challenges arise from both hardware and software integration.
5. Safety and Ethical Considerations
As robots become more autonomous and integrated into daily life, ensuring safe human interactions becomes critical. Computer vision systems follow robust safety measures to prevent accidents. Just think of autonomous vehicles and medical robots. Ethical considerations, including privacy concerns, algorithm bias, and fair competition, are also hurdles to ensuring the responsible use of this tech.
Breakthroughs in Robotics CV Models
Ask most experts, and they will probably say that we are still a few years out from computer vision in robotics’ “ChatGPT moment.” However, 2023 has been full of encouraging signs that we’re on the right track.
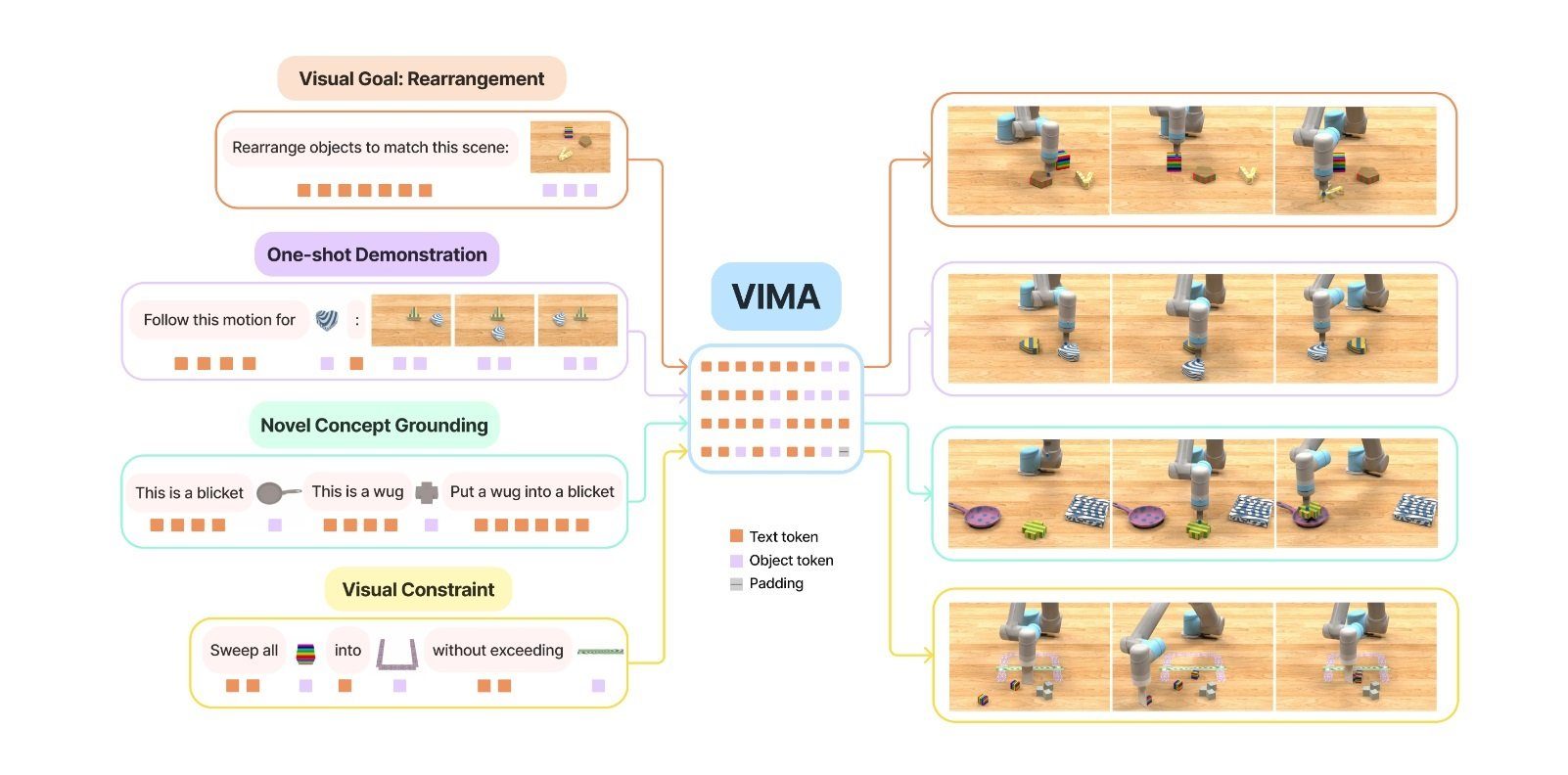
The integration of multimodal Large Language Models (LLMs) with robots is monumental in spearheading this field. It enables robots to process complex instructions and interact with the physical world. Research institutes and companies have been involved in notable projects, including NVIDIA’s VIMA, PreAct, and RvT, Google’s PaLM-E, and DeepMind’s RoboCat.
Berkeley, Stanford, and CMU are also collaborating on another promising project named Octo. These systems allow robot arms to serve as physical input/output devices capable of complex interactions.
High-Level Reasoning vs. Low-Level Control
We’ve also made great progress bridging the cognitive gap between high-level reasoning and low-level control. NVIDIA’s Eureka and Google’s Code as Policies use natural language processing (NLP) to translate human instructions to robot code to execute tasks.
Hardware advancements are equally critical. Tesla’s Optimus and Figure’s 1X latest robust models showcase a leap forward in the versatility of robotic platforms. These developments are possible largely thanks to advancements in synthetic data and simulation, crucial for training robots.
NVIDIA Isaac, for example, simulates environments 1000x faster than in real-time. It’s capable of scalable, photorealistic data generation that includes accurate annotations for training.
The Open X-Embodiment (RT-X) dataset is tackling the challenge of data scarcity, aiming to be the ImageNet for robotics. Though not yet diverse enough, it’s a significant stride towards creating rich, nuanced datasets critical for training sophisticated models.
Additionally, simulators like MimicGen (NVIDIA) amplify the value of real-world data. Some generate expansive datasets that reduce reliance on costly human demonstrations.
Looking Ahead
As technology continues to progress, we can expect more useful applications of robots using computer vision to replicate the human visual system. With edge AI and sensors, we’re excited to see even more use cases for how we can work with robots.
To learn about the future we envision for computer vision and robotics, please give our recently released Visual General Intelligence (VGI) whitepaper a read.