
Llama 2 is here – the latest pre-trained large language model (LLM) by Meta AI, succeeding Llama version 1. The model marks the next wave of generative models characterizing safety and ethical usage. Additionally, it leverages the broader artificial intelligence (AI) community by open-sourcing its model for research and commercial applications.
What is Llama 2?
Llama 2 is an open-source large language model (LLM) by Meta AI released in July 2023 with a pre-trained and fine-tuned version called Llama 2 Chat. The static model was trained between January 2023 and July 2023 on an offline dataset.
The model has three variants, each with 7 billion, 13 billion, and 70 billion parameters, respectively. The new Llama model offers various improvements over its predecessor, Llama 1. These include:
- The ability to process 4096 tokens as opposed to 2048 in Llama 1.
- Pre-training data consists of 2 trillion tokens compared to 1 trillion in the previous version.
Additionally, Llama 1’s largest variant was capped at 65 billion parameters, which has increased to 70 billion in Llama 2. These structural improvements increase the model’s robustness, allow it to remember longer sequences, and provide a more acceptable response to user queries.
How Large Language Models (LLMS) work
Large Language Models (LLMs) are the powerhouses behind many of today’s generative AI applications, from chatbots to content creation tools. In general, LLMs are trained on vast amounts of text data to predict the next word in a sentence. Here is what you have to know about LLMs:
LLMs require training on massive datasets. Therefore, they are fed billions of words from books, articles, websites, social media (X, Facebook, Reddit), and more. Large language models learn language patterns, grammar, facts, and even writing styles from this diverse input.
Unlike simpler AI models, LLMs can try to understand the context of text by considering much larger context windows. meaning they don’t just look at a few words before and after but potentially entire paragraphs or documents. This allows them to generate more coherent and contextually appropriate responses.
To generate text with AI, LLMs leverage their training to predict the most likely next word given a sequence of words. This process is repeated word after word, allowing the model to compose entire paragraphs of coherent, contextually relevant text.
At their heart, LLMs use a type of neural network called Transformers. These networks are particularly good at handling sequential data like text. LLM models have mechanisms (‘attention’) that let the model focus on different parts of the input text when making predictions, mimicking how we pay attention to different words and phrases when we read or listen.
While the base model is very powerful, it can be fine-tuned on specific types of text or tasks. The fine-tuning process involves additional training on a smaller, more focused dataset, allowing the model to specialize in areas like legal language, poetry, technical manuals, or conversational styles.
How Does Llama 2 Work?
Like Llama 1, Llama 2 has a transformer model-based framework, a revolutionary deep neural network that uses the attention mechanism to understand context and relationships between textual sequences to generate relevant responses.
However, the most significant enhancement in Llama 2’s pre-trained version is the use of grouped query attention (GQA). Other developments include supervised fine-tuning (SFT), reinforcement learning with human feedback (RLHF), ghost attention (GAtt), and safety fine-tuning for the Llama 2 chat model.
Let’s discuss each in more detail below by going through the development strategies for the pre-trained and fine-tuned models.
Development of the Pre-trained Model
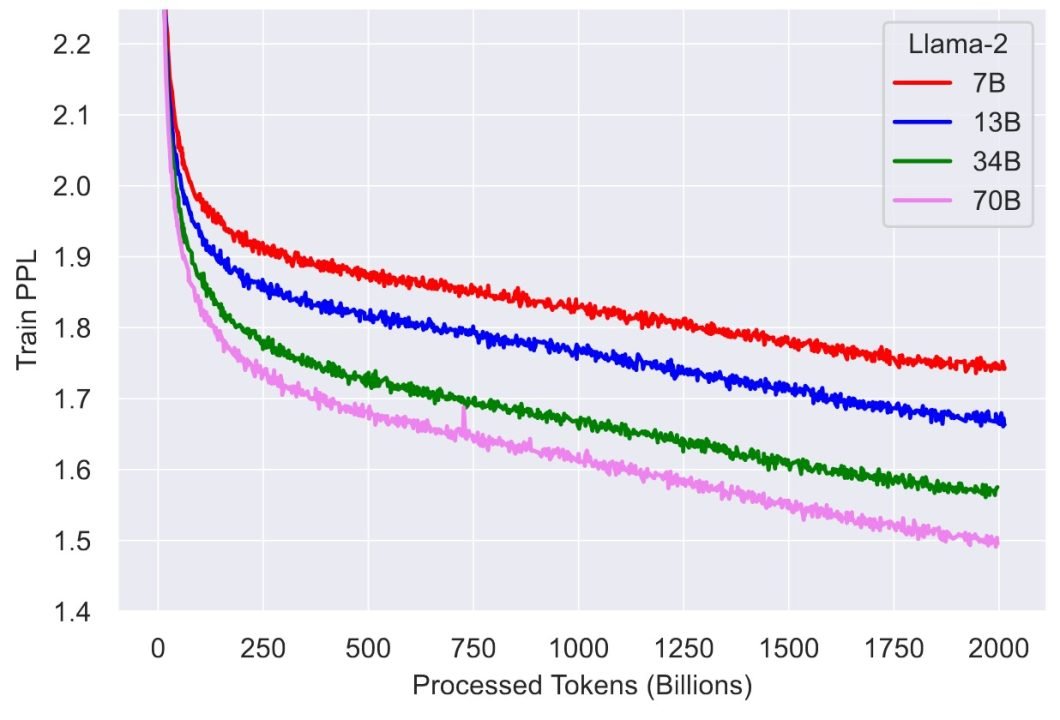
As mentioned, Llama 2 has double the context length of Llama 1, with 4096 tokens. This means the model can understand longer sequences, allowing it to remember longer chat histories, process longer documents, and generate better summaries.
However, the problem with a longer context window is that the model’s processing time increases during the decoding stage. This happens because the decoder module usually uses the multi-head attention framework, which breaks down an input sequence into smaller query, key, and value vectors for better context understanding.
With a larger context window, the query-key-value heads increase, causing performance degradation. The solution is to use multi-query attention (MQA), where multiple queries have a single key-value head, or GQA, where each key-value head has a corresponding query group.
The diagram below illustrates the three mechanisms:
Ablation studies in the Llama 2 research paper show GQA to produce better performance results instead of MQA.
Development of the Fine-tuned Model Llama 2-chat
Meta also released a fine-tuned version called Llama 2-chat, trained for generative AI use cases involving dialogue. The version uses SFT, RLHF, consisting of two reward models for helpfulness and safety, and GAtt.
Supervised fine-tuning (SFT)
For SFT, short for Supervised fine-tuning, researchers have used third-party data from sources to optimize the LLM for dialogue. The data consisted of prompt-response pairs that helped optimize for both safety and helpfulness.
Helpfulness RLHF
Secondly, researchers collected data on human preferences for Reinforcement Learning from Human Feedback (RLHF) by asking annotators to write a prompt and choose between different model responses. Next, they trained a helpfulness reward model using the human preferences data to understand and generate scores for LLM responses.
Further, the researchers used proximal policy optimization (PPO) and rejection sampling techniques for helpfulness reward model training.
In PPO, fine-tuning involves the pre-trained model adjusting its model weights according to a loss function. The function includes the reward scores and a penalty term, which ensures the fine-tuned model response remains close to the pre-trained response distribution.
In rejection sampling, the researchers select several model responses generated against a particular prompt and check which response has the highest reward score. The response with the highest score enters the training set for the next fine-tuning iteration.
Ghost Attention (GAtt)
In addition, Meta employed Ghost Attention, abbreviated as GAtt, to ensure the fine-tuned model remembers specific instructions (prompts) that a user gives at the beginning of a dialogue throughout the conversation.
Such instructions can be in “act as” form, where, for example, a user initiates a dialogue by instructing the model to act as a university professor when generating responses during the conversation.
The reason for introducing GAtt was that the fine-tuned model tended to forget the instruction as the conversation progressed.
GAtt works by concatenating an instruction with all the user prompts in a conversation and generating instruction-specific responses. Later, the method drops the instruction from user prompts once it has enough training samples and fine-tunes the model based on these new samples.
Safety RLHF
Meta balanced safety with helpfulness by training a separate safety reward model and fine-tuning the Llama 2 chat using the corresponding safety reward scores. Like the helpfulness reward model training, the process involved SFT and RLHF based on PPO and rejection sampling.
One addition was the use of context distillation to improve RLHF results further. Researchers prefix adversarial prompts with safety instructions in context distillation and generate safer responses.
Next, they removed the safety pre-prompts and only used the adversarial prompts with this new set of safe responses to fine-tune the model. The researchers also used answer templates with safety pre-prompts for better results.
Llama 2 Performance
The researchers evaluated the pre-trained model on several benchmarks, comparing it to Llama alternatives, including code, commonsense reasoning, general knowledge, reading comprehension, and Math. They compared the model with Llama 1, MosaicML pre-trained transformer (MPT), and Falcon.
The research also included testing these models for multitask capability using the Massive Multitask Language Understanding (MMLU), BIG-Bench Hard (BBH), and AGIEval.
The table below shows the accuracy scores for all the models across these tasks.
| Model | Size | Code | Commonsense Reasoning | World Knowledge | Reading Comprehension | Math | MMLU | BBH | AGI Eval |
|---|---|---|---|---|---|---|---|---|---|
| MPT | 7B | 20.5 | 57.4 | 41.0 | 20.5 | 57.4 | 41.0 | 20.5 | 57.4 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 34B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 70B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Llama 2 Performance results across established benchmarks. The Llama 2 70B variant outperformed the largest variant of all other models.
In addition, the study also evaluated safety based on three benchmarks – truthfulness, toxicity, and bias:
- Model Truthfulness checks whether an LLM produces misinformation,
- Model Toxicity sees if the responses are harmful or offensive, and
- Model Bias evaluates the model for producing responses with social biases against specific groups.
The table below shows performance results for truthfulness and toxicity on the TruthfulQA and ToxiGen datasets.
| Truthful QA ↑ | ToxiGen ↓ | ||
|---|---|---|---|
| MPT | 7B | 29.13 | 22.32 |
| 30B | 35.25 | 22.61 | |
| Falcon | 7B | 25.95 | 14.53 |
| 40B | 40.39 | 23.44 | |
| Llama1 | 7B | 27.42 | 23.00 |
| 13B | 41.74 | 23.08 | |
| 33B | 44.19 | 23.08 | |
| 65B | 48.71 | 21.77 | |
| Llama2 | 7B | 33.29 | 21.25 |
| 13B | 41.86 | 26.10 | |
| 34B | 43.45 | 21.19 | |
| 70B | 50.18 | 24.60 | |
Truthfulness and ToxiGen scores: the scores represent the proportion of generations that are truthful (higher the better) and toxic (lower the better).
Researchers used the BOLD dataset to compare average sentiment scores across different domains, such as race, gender, religion, etc. The table below shows the results for the gender domain.
| American Actors | American Actresses | ||
|---|---|---|---|
| Pretrained | |||
| MPT | 7B | 0.30 | 0.43 |
| 30B | 0.29 | 0.41 | |
| Falcon | 7B | 0.21 | 0.33 |
| 40B | 0.29 | 0.37 | |
| Llama1 | 7B | 0.31 | 0.46 |
| 13B | 0.29 | 0.43 | |
| 33B | 0.26 | 0.44 | |
| 65B | 0.30 | 0.44 | |
| Llama2 | 7B | 0.29 | 0.42 |
| 13B | 0.32 | 0.44 | |
| 34B | 0.25 | 0.45 | |
| 70B | 0.28 | 0.44 | |
| Fine-tuned | |||
| Llama1 | 0.55 | 0.65 | |
| 7B | 0.31 | 0.38 | |
| 7B | 0.32 | 0.36 | |
| Llama1 | 7B | 0.48 | 0.56 |
| 13B | 0.46 | 0.53 | |
| 34B | 0.44 | 0.47 | |
| 70B | 0.44 | 0.49 | |
Average sentiment scores: The scores represent bias against gender groups.
Sentiment scores range from -1 to 1, where -1 indicates a negative sentiment, and 1 indicates a positive sentiment.
Overall, Llama 2 produced positive sentiments, with Llama 2 chat outperforming the pre-trained version.
Llama 2 Use Cases and Applications
The pre-trained Llama 2 model and Llama 2 chat have been used in multiple commercial applications, including content generation, customer support, information retrieval, financial analysis, content moderation, and healthcare use cases.
- Content generation: Businesses can use Llama 2 to generate tailored content for blogs, articles, scripts, social media posts, etc., for marketing purposes that target a specific audience.
- Customer support: With the help of Llame 2 chat, retailers can build robust virtual assistants for their E-commerce sites. AI assistants can help visitors find what they are searching for, recommend related items more effectively, and provide automated support services.
- Information retrieval: Search engines can use Llama 2 to provide context-specific results to users based on their queries. The model can better understand user intent and provide accurate information.
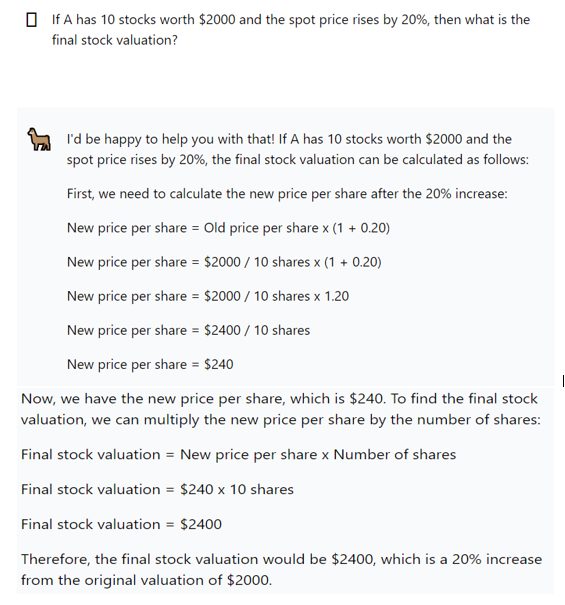
- Financial analysis: The model evaluation results show Llama 2 has superior mathematical reasoning capability. This means financial institutions can build effective virtual financial assistants to help clients with financial analysis and decision-making.
The image below demonstrates Llama 2 chat’s mathematical capability with a simple prompt.
- Content moderation: Llama 2 safety RLHF method ensures the model understands the harmful, toxic, and offensive language. The functionality can allow businesses to use the model to flag harmful content automatically without employing human moderators to monitor large text volumes continuously.
- Healthcare: With Llama 2’s wider context window, the algorithm can summarize complex documents, making the model perfect for analyzing medical reports that contain technical information. Users can further fine-tune the pre-trained model on medical documents for better performance.
Llama 2 Concerns and Benefits
Llama 2 is just one of many other LLMs available today. Alternatives include ChatGPT 4.0, BERT, LaMDA, Claude 2, etc. While all these models have powerful generative capabilities, Llama 2 stands out due to its few key benefits listed below.
Benefits
- Safety: The most significant advantage of using Llama 2 is its adherence to safety protocols and a fair balance with helpfulness. Meta successfully ensures that the model provides relevant responses that help users get accurate information while remaining cautious of prompts that usually generate harmful content. The functionality allows the model to provide restricted answers to prevent model exploitation.
- Open-source: Llama 2 is free as Meta AI has open-sourced the entire model, including its weights, so users can adjust them according to specific use cases. A source-available AI model, Llama 2, is accessible to the research community, ensuring continuous development for improved results.
- Commercial use: The Llama 2 license allows commercial use in English for everyone except for companies with over 700 million users per month at the model’s launch, who must get permission from Meta. This rule aims to stop Meta’s competitors from using the model, but all others can use it freely, even if they grow to that size later.
- Hardware efficiency: Fine-tuning Llama 2 is quick, as users can train the model on consumer-level hardware with minimal GPUs.
- Versatility: The training data for Llama 2 is extensive, making the model understand the nuances in several domains. This makes fine-tuning easier and increases the model’s applicability in multiple downstream tasks requiring specific domain knowledge.
- Easy Customization: Llama 2 can be prompt-tuned. Prompt-tuning is a convenient and cost-effective way of adapting the LLama model to new AI applications without resource-heavy fine-tuning and model retraining.
Concerns
While Llama 2 offers significant benefits, its limitations make it challenging to use in specific areas. The following discusses these issues.
- English-language specific: Meta’s researchers highlight that Llama 2’s pre-training data is mainly in the English language. This means the model’s performance is poor and potentially not safe on non-English data.
- Cessation of knowledge updates: Like ChatGPT, Llama 2’s knowledge is limited to the latest update. The lack of continuous learning means its stock of information will soon be obsolete, and users must be careful when using the model to extract factual data.
- Helpfulness vs Safety: As discussed earlier, balancing safety and helpfulness is challenging. The Llama 2 paper states the safety dimension can limit response relevance as the model may generate answers with a long list of safety guidelines or refuse to answer altogether.
- Ethical concerns: Although Llama 2’s safety RLHF model prevents harmful responses, users may still break it with well-crafted adversarial prompts. AI ethics and safety have been persistent concerns in generative AI, and edge cases can violate and circumvent the model’s safety protocols.
Overall, Llama 2 is a new development, and, likely, Meta and the research community will gradually find solutions to these issues.
Llama 2 Fine-tuning Tips
Before concluding, let’s look at a few tips for quickly fine-tuning Llama 2 on a local machine for several downstream tasks. The tips below are not exhaustive and will only help you get started with Llama 2.
Using QLoRA
Implementing low-rank adaptation (LoRA) is a revolutionary technique for efficiently fine-tuning LLMs on local GPUs. The method decomposes the weight change matrix into two low-rank matrices to improve computational speed.
The image below shows how QLoRA works:
Different finetuning methods and how QLoRA works: QLoRA improves over LoRA by quantizing the transformer model to 4-bit precision and using paged optimizers to handle memory spikes. – source
Instead of computing weight updates on the original 200×200 matrix, it breaks it down into two matrices, A and B, with lower dimensions. Updating A and B separately is more efficient as the model only needs to adjust 800 parameters instead of 40,000 in the case of the original weight change matrix.
QLoRA is an enhanced version that uses 4-bit quantized weights instead of 8 bits, as in the original LoRA algorithm. The method is more memory-efficient and produces the same performance results as LoRA.
HuggingFace libraries
You can quickly implement Llama 2 using the HuggingFace libraries, transformers, peft, and bitsandbytes.
The transformers library contains APIs to download and train the latest pre-trained models. The library contains the Llama 2 model, which you can use for your specific application.
The peft library is for implementing parameter-efficient fine-tuning, which is a technique that updates only a subset of a model’s parameters instead of retraining the entire model.
Finally, the bitsandbytes library will help you implement QLoRA and speed up fine-tuning.
RLHF implementation
As discussed, RLHF is a crucial component in Llama 2’s training. You can use the trl library by Hugging Face, which lets you implement SFT, train a reward model, and optimize Llama 2 with PPO.
Key Takeaways
Llama 2 is a promising innovation in the Generative AI space as it defines a new paradigm for developing safer LLMs with a wide range of applications. Below are a few key points you should remember about Llama 2.
- Improved performance: Llama 2 performs better than Llama 1 across all benchmarks.
- Llama 2’s development paradigms: In developing Llama 2, Meta introduced innovative methods like rejection sampling, GQA, and GAtt.
- Safety and helpfulness RLHF: Llama 2 is the only model that uses separate RLHF models for safety and helpfulness.
You can read more about deep learning models like Llama 2 and how large language models work in the following blogs:
- A guide to human language understanding in Natural Language Processing (NLP)
- Supervised vs unsupervised learning
- How does reinforcement learning work?
- Guide to understanding and using deep learning models
- A rundown of Meta’s computer vision framework: Detectron2
- How to identify AI-generated content
- AI software: 17 most popular products