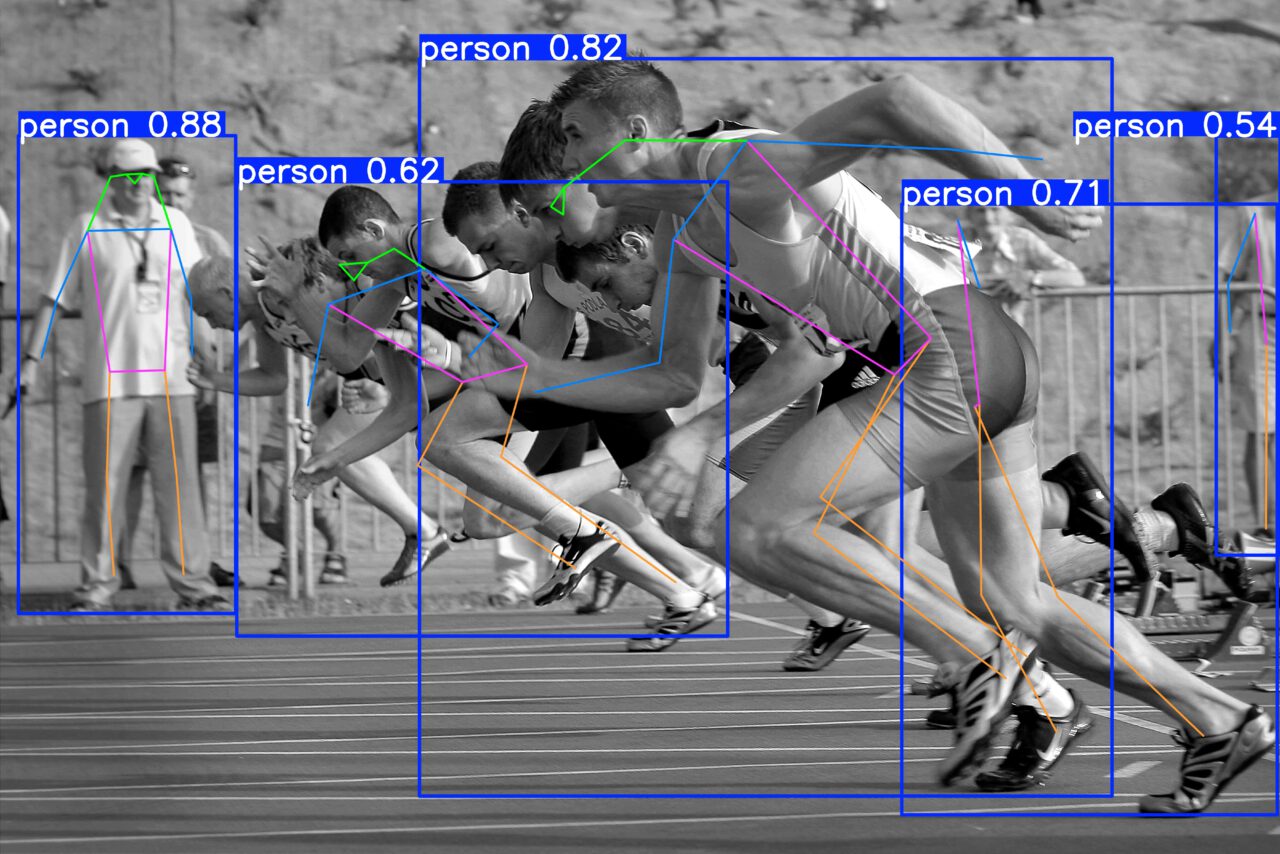
YOLO (You Only Look Once) is a state-of-the-art (SOTA) object-detection algorithm introduced as a research paper by J. Redmon et al. (2015). In real-time object identification, the YOLO11 architecture is an advancement over its predecessor, the Region-based Convolutional Neural Network (R-CNN).
At the end of 2024, Ultralytics released the latest iteration of YOLO: YOLO11. This is their third contribution to the YOLO series, following YOLOv5 and YOLOv8. This single-pass approach, using an entire image as input, uses a single neural network to predict bounding boxes and class probabilities. Building on previous versions and community improvements, YOLO11 offers improved accuracy, requiring fewer parameters.
In this article, we will elaborate on YOLO11 and dive into the numerous tasks possible with the computer vision model.
Get a Demo
AI vision that adapts to your enterprise, not the other way around. Request a demo of Viso Suite.
YOLO11 is the latest version of YOLO, an advanced real-time object detection. The YOLO family enters a new chapter with YOLO11, a more capable and adaptable model that pushes the boundaries of computer vision.
The model supports computer vision tasks like posture estimation and instance segmentation. The CV community that uses previous YOLO versions will appreciate YOLO11 because of its better efficiency and optimized architecture.
Ultralytics CEO and founder Glenn Jocher claimed: “With YOLOv11, we set out to develop a model that offers both power and practicality for real-world applications. Because of its increased accuracy and efficiency, it’s a versatile instrument that is tailored to the particular problems that different sectors encounter.”
Crowd counting with YOLOv11
Supported Tasks
For developers and researchers alike, Ultralytics YOLOv11 is a ubiquitous tool due to its inventive architecture. CV community will use YOLOv11 to develop creative solutions and advanced models. It enables a variety of computer vision tasks, including:
Object Detection
Instance Segmentation
Pose Estimation
Oriented Detection
Classification
Some of the main enhancements include improved feature extraction, more accurate detail capture, higher accuracy with fewer parameters, and faster processing rates that greatly boost real-time performance.
An Overview of YOLO Models
Here is an overview of the YOLO family of models up until YOLOv11.
Release
Authors
Tasks
Paper
YOLO
2015
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi
Object Detection, Basic Classification
You Only Look Once: Unified, Real-Time Object Detection
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
Object Detection
YOLOv10: Real-Time End-to-End Object Detection
Key Advantages of YOLOv11
YOLOv11 is an improvement over YOLOv9 and YOLOv10, which were released in early 2024. It has better architectural designs, more effective feature extraction algorithms, and better training methods. The remarkable blend of YOLOv11’s speed, precision, and efficiency sets it apart, making it among the most powerful models by Ultralytics to date.
YOLOv11 possesses an improved design, which enables more precise detection of delicate details – even in difficult situations. It also has better feature extraction, i.e. it can extract multiple patterns and details from photos.
Concerning its predecessors, Ultralytics YOLOv11 offers several noteworthy improvements. Important advancements consist of:
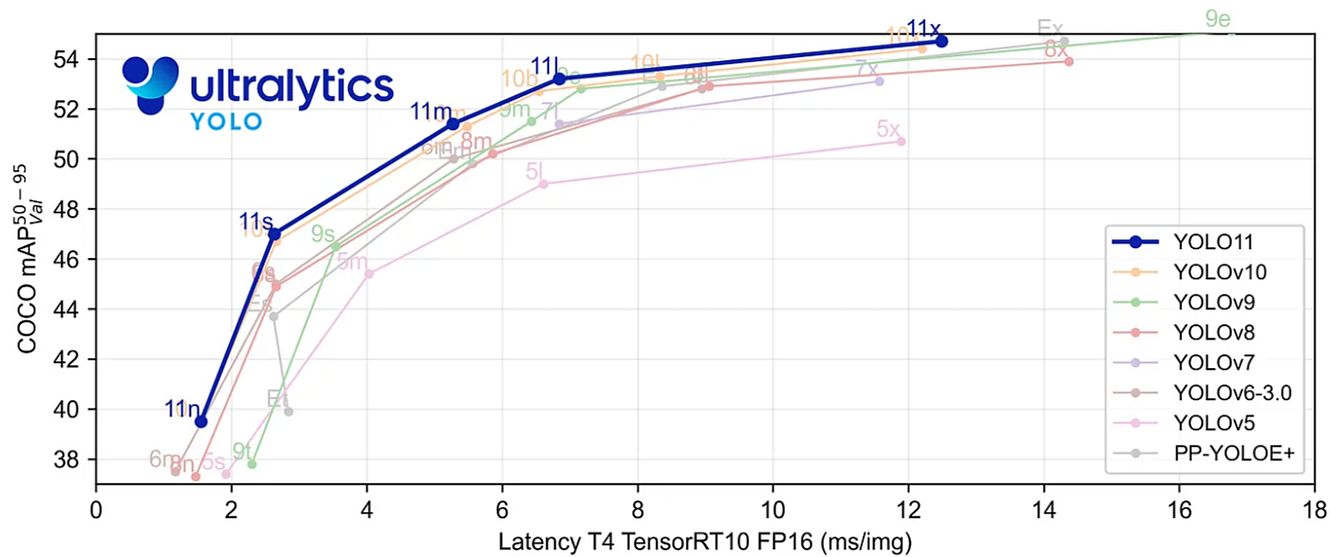
YOLOv11 model performance compared to its predecessors
Better accuracy with fewer parameters: YOLOv11m is more computationally efficient without sacrificing accuracy. It achieves a greater mean Average Precision (mAP) on the COCO dataset with 22% fewer parameters than YOLOv8m.
Wide variety of tasks supported: YOLOv11 is capable of performing a wide range of CV tasks, including pose estimation, object recognition, image classification, instance segmentation, and orientated object detection (OBB).
Improved speed and efficiency: Faster processing rates are achieved via improved architectural designs and training pipelines that strike a compromise between accuracy and performance.
Fewer parameters: fewer parameters make models faster without significantly affecting v11’s correctness.
Improved feature extraction: YOLOv11 has a better neck and backbone architecture to improve feature extraction capabilities, which leads to more accurate object detection.
Adaptability across contexts: YOLOv11 is adaptable to a wide range of contexts, such as cloud platforms, edge devices, and systems that are compatible with NVIDIA GPUs.
YOLOv11 – How to Use It?
As of October 10, 2024, Ultralytics has not published the YOLOv11 paper, nor its architecture diagram. However, there is enough documentation released on GitHub. The model is less resource-intensive and capable of handling complicated tasks. It is an excellent choice for challenging AI projects because it also enhances large-scale model performance.
The training process has improvements to the augmentation pipeline, which makes it simpler for YOLOv11 to adjust to various tasks – whether small projects or large-scale applications. Install the most recent version of the Ultralytics package to begin using YOLOv11:
pip install ultralytics>=8.3.0
You can use YOLOv11 for real-time object detection and other computer vision applications with just a few lines of code. Use this code to load a pre-trained YOLOv11 model and perform inference on a picture:
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Run inference on an image
results = model("path/to/image.jpg")
# Display results
results[0].show()
YOLOv11 for person detection on construction sites
Components of YOLOv11
YOLOv11 includes the following tools: oriented bounding box (-obb), pose estimation (-pose), instance segmentation (-seg), bounding box models (no suffix), and classification (-cls).
The following sizes are also available for the tools: nano (n), small (s), medium (m), large (l), and extra-large (x). The engineers can utilize Ultralytics Library models to:
Track objects and trace them along their paths.
Export files: the library is easily exportable in a variety of formats and uses.
Execute various scenarios: they can train their models using a range of items and picture types.
Furthermore, Ultralytics has released the YOLOv11 Enterprise Models, which will be available on October 31st. Though it will use larger proprietary custom datasets, teams can use it similarly to the open-source YOLOv11 models.
YOLOv11 offers unparalleled flexibility for a wide range of applications since it can be seamlessly integrated into multiple workflows. In addition, teams can optimize it for deployment across several settings, including edge devices and cloud platforms.
With the Ultralytics Python package and the Ultralytics HUB, engineers can already start using YOLOv11. It will bring them advanced CV possibilities and they’ll see how YOLO-11 can support diverse AI projects.
Performance Metrics and Supported Tasks
With its exceptional processing power, efficiency, and compatibility for cloud and edge device deployment, YOLOv11 offers flexibility in a variety of settings. Moreover, Yolo11 isn’t just an upgrade – rather, it’s a much more precise, effective, and adaptable model that can tackle diverse CV tasks.
Model
Size (pixels)
mAPval (50-95)
Speed CPU ONNX (ms)
Speed T4 TensorflowRT10 (ms)
params (M)
FLOPs (B)
YOLO11n
640
39.5
56.1 ± 0.8
1.5 ± 0.0
2.6
6.5
YOLO11s
640
47.0
90.0 ± 1.2
2.5 ± 0.0
9.4
21.5
YOLO11m
640
51.5
183.2 ± 2.0
4.7 ± 0.1
20.1
68.0
YOLO11l
640
53.4
238.6 ± 1.4
6.2 ± 0.1
25.3
86.9
YOLO11x
640
54.7
462.8 ± 6.7
11.3 ± 0.2
56.9
194.9
YOLOv11 performance on COCO Object Detection
It provides better feature extraction with more accurate detail capture, higher accuracy with fewer parameters, and faster processing rates (better real-time performance). Regarding accuracy and speed – YOLO-11 is superior to its predecessors:
Efficiency and speed: It is ideal for edge applications and resource-constrained contexts by having up to 22% fewer parameters than other models. Also, it enhances real time object detection by up to 2% faster.
Accuracy improvement: when it comes to object detection on COCO, YOLO-11 outperforms YOLOv8 by up to 2% in terms of mAP (mean Average Precision).
Surprisingly, YOLO11m uses 22% fewer parameters than YOLOv8m and obtains a higher mean Average Precision (mAP) score on the COCO dataset. Thus, it is computationally lighter without compromising performance.
Model
Size (pixels)
ACC top1
ACC top5
Speed CPU ONNX (ms)
Speed T4 TensorflowRT10 (ms)
params (M)
FLOPs (B) at 640
YOLO11n
224
70.0
89.4
5.0 ± 0.3
1.1 ± 0.0
1.6
3.3
YOLO11s
224
75.4
92.7
7.9± 0.2
1.3 ± 0.0
5.5
12.1
YOLO11m
224
77.3
93.9
17.2 ± 0.4
17.2 ± 0.0
10.4
39.3
YOLO11l
224
78.3
94.3
23.2 ± 0.3
2.8 ± 0.0
12.9
49.4
YOLO11x
224
79.5
94.9
41.4 ± 0.9
3.8 ± 0.0
28.4
110.4
Performance of YOLO11 on the ImageNet Dataset for Image Classification
This indicates that it executes more efficiently and produces more accurate outcomes. Furthermore, YOLOv11 offers better processing speeds than YOLOv10, with inference times that are about 2% faster. This makes it perfect for real-time applications.
YOLOv11 Applications
Teams can utilize flexible YOLO-11 models in a variety of computer vision applications, such as:
Object tracking: This feature, which is crucial for many real-time applications, tracks and monitors the movement of objects over a series of video frames.
Object detection: For use in surveillance, autonomous driving, and retail analytics, this technology locates and identifies things within pictures or video frames and draws bounding boxes around them.
Image classification: This technique classifies pictures into pre-established groups. It makes it perfect for uses like e-commerce product classification or animal observation.
Instance segmentation: This process requires pinpointing and pixel-by-pixel identification and separation of specific objects inside an image. Applications such as medical imaging and manufacturing defect uncovering can benefit from its use.
Pose estimation: in a wide range of medical applications, sports analytics, and fitness tracking. Pose estimation identifies important spots inside an image size, or video frame to track movements or poses.
Oriented object detection (OBB): This technology locates items with an orientation angle, making it possible to localize rotational objects more precisely. It is particularly useful for jobs involving robotics, warehouse automation, and aerial images.
Therefore, YOLO-11 is adaptable enough to be used in different CV applications: autonomous driving, surveillance, healthcare imaging, smart retail, and industrial use cases.
Model
Filenames
Task
Inference
Validation
Training
Export
YOLO11
yolo11n.pt
yolo11s.pt
yolo11m.pt
yolo11l.pt
yolo11x.pt
Detection
✅
✅
✅
✅
YOLO11-seg
yolo11n-seg.pt
yolo11s-seg.pt
yolo11m-seg.pt
yolo11l-seg.pt
yolo11x-seg.pt
Instance Segmentation
✅
✅
✅
✅
YOLO11-pose
yolo11n-pose.pt
yolo11s-pose.pt
yolo11m-pose.pt
yolo11l-pose.pt
yolo11x-pose.pt
Pose/Keypoints
✅
✅
✅
✅
YOLO11-obb
yolo11n-obb.pt
yolo11s-obb.pt
yolo11m-obb.pt
yolo11l-obb.pt
yolo11x-obb.pt
Oriented Detection
✅
✅
✅
✅
YOLO11-cls
yolo11n-cls.pt
yolo11s-cls.pt
yolo11m-cls.pt
yolo11l-cls.pt
yolo11x-cls.pt
Classification
✅
✅
✅
✅
Supported Tasks and Models with YOLOv11 versions
Implementing YOLOv11
Thanks to community contributions and broad applicability, the YOLO models are the industry standard in object detection. With this release of YOLOv11, we have seen that it has good processing power efficiency and is ideal for deployment on edge and cloud devices. It provides flexibility in a variety of settings and a more precise, effective, and adaptable approach to computer vision tasks. We are excited to see further developments in the world of open-source computer vision and the YOLO series!
To get started with YOLOv11 for open-source, research, and student projects, we suggest checking out the Ultralytics Github repository. To learn more about the legalities of implementing computer vision on enterprise applications, check out our guide to model licensing.
Get Started With Enterprise Computer Vision
Viso Suite is an End-to-End Computer Vision Infrastructure that provides all the tools required to train, build, deploy, and manage computer vision applications at scale. Our infrastructure is designed to expedite the time taken to deploy real-world applications, leveraging existing camera investments and running on the edge. It combines accuracy, reliability, and lower total cost of ownership, lending itself perfectly to multi-use case, multi-location deployments.
Viso Suite is fully compatible with all popular machine learning and computer vision models.
We work with large firms worldwide to develop and execute their AI applications. To start implementing state-of-the-art computer vision, get in touch with our team of experts for a personalized demo of Viso Suite.
FAQs
The main YOLO-11 advantages are: better accuracy, faster speed, fewer parameters, improved feature extraction, adaptability across different contexts, and support for various tasks.
By using YOLO-11, you can classify images, detect objects, segment images, estimate poses, and detect object orientation.
Users can train the YOLO-11 model for object detection by using Python or CLI commands. First, you must import the YOLO library in Python and then utilize the model.train() command.
Yes, because of its lightweight, efficient architecture and efficient processing method, YOLOv11 can be deployed on multiple platforms, including edge devices.