AlphaPose is a multi-person pose estimation model that uses computer vision and deep learning techniques to detect and predict human poses from images and videos in real time. It powers applications in various fields such as medicine, sports analytics, action recognition, motion capture, movement analysis, VR, and AR.
However, whole-body pose estimation is difficult and currently faces various challenges, such as:
- Small body parts: Accurately pinpointing body parts, especially for small people or those with occlusions (when something is blocking the view).
- Scales: Handling different scales (far away vs. close up) because body parts appear larger or smaller in the image.
- Real-Time: Must be fast enough to run in real-time for applications like video analysis.
Review of Pose Estimation
Before the start of deep learning, pose estimation relied on manual techniques, where humans did a lot of work. Approaches such as Support Vector Machines and Random Forests were used to detect key points in humans.
However, when deep learning became popular in the 2010s, DeepPose was introduced by researchers at Facebook in 2014. This was an inspirational model that utilized Convolutional Neural Networks (CNNs) to effectively detect human poses directly from images.
However, DeepPose was initially designed for single-person detection. This presented a challenge for multi-person detection and tracking in a video. Therefore, further advancement was made to build multi-person detection models.
AlphaPose is a fast, accurate, deep learning-based multi-person pose estimation model that utilizes two-stage pose estimation.
What is AlphaPose?

AlphaPose is an accurate, fast, open-source model that performs pose estimation using a two-stage approach.
- Human detection: It first uses an existing object detector to find people in the image.
- Pose estimation: For each person, AlphaPose predicts the location of key body parts (joints) using a novel technique called symmetric integral keypoint regression, which is more accurate than traditional methods, especially for small body parts like hands and faces.
Moreover, AlphaPose can also track people over time. It does this by considering both the pose itself and the unique features of people, which can then be used to identify and track them in a video.

AlphaPose Stages
Stage 1: Person Detection
- Input: AlphaPose takes an input image or a frame from a video.
- Person Detection: An object detection model such as YOLOv3 is used to detect the human body within the image and store the bounding box coordinates.
Stage 2: Pose Estimation
Each bounding box detected from stage 1 is used to estimate the pose, allowing for exclusive focusing on the person detected
- AlphaPose uses a pose estimation model that takes the cropped human images (bounding boxes) as input.
- The pose estimation model predicts the coordinates of key body joints (e.g., shoulders, elbows, wrists, hips, knees, ankles) within each bounding box by generating a heatmap of the key points.
The final output goes through preprocessing, where the detected key points are joined and a pose is created. This generated pose is then used in various applications such as activity recognition, gesture recognition, human-computer interaction, and more.
Heatmaps for Pose Estimation
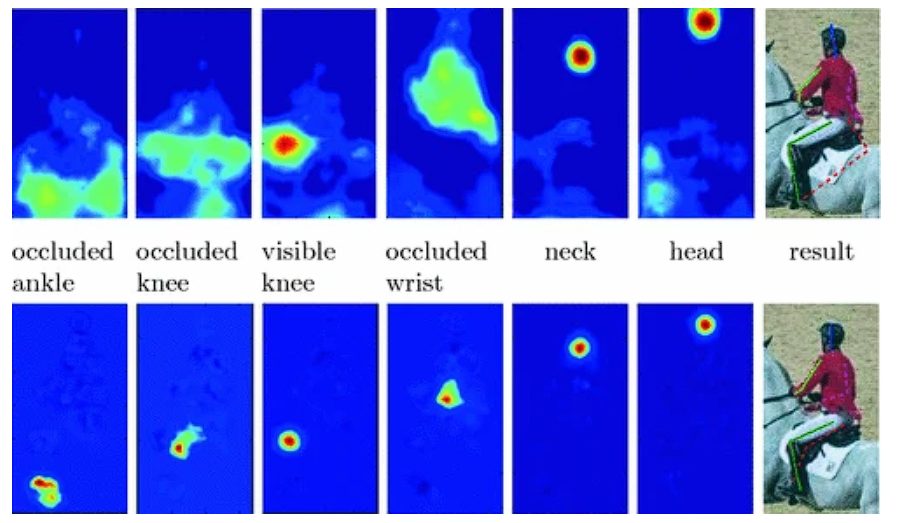
The most important task of pose estimation is finding key points in an image, in Alphapose this is performed by generating heatmaps. Heatmaps are used to represent the likelihood of each key point’s location in a spatial grid format.
The typical process goes like this:
- Heatmaps are generated during the pose estimation process to represent the probability distribution of keypoint locations. This is done using a Convolutional Neural Network like ResNet.
- The CNN model outputs a set of heatmaps, one for each key point (e.g., one for the left elbow, one for the right knee, etc.).
- Each heatmap is a 2D grid with the same dimensions as the input image (or a downsampled version of it). The intensity value at each position in a heatmap indicates the probability or confidence of the corresponding key point being at that location.
Training with Heatmaps
During the training phase, the network learns to predict accurate heatmaps based on the ground truth key points provided in the training data. The predicted heatmaps are compared with the ground truth heatmaps using a loss function.
Once the network is trained, the heatmaps it generates for a given input image can be used to detect key points.
Post-processing
During inference, the heatmap for each key point is analyzed to find the location with the highest intensity value. The location of the peak value represents the most likely location of the key point in the image.
Key Innovations in Alphapose
AlphaPose introduced various innovations in its published research paper. Techniques such as:
- Symmetric Integral Keypoint Regression (SIKR) for fast and fine localization
- Parametric Pose Non-Maximum-Suppression (P-NMS) for eliminating redundant human detections.
- Pose Aware Identity Embedding for jointly pose estimation and tracking.
- During training, the model uses a Part-Guided Proposal Generator (PGPG) for better proposal generation and multi-domain knowledge distillation to further improve the accuracy.
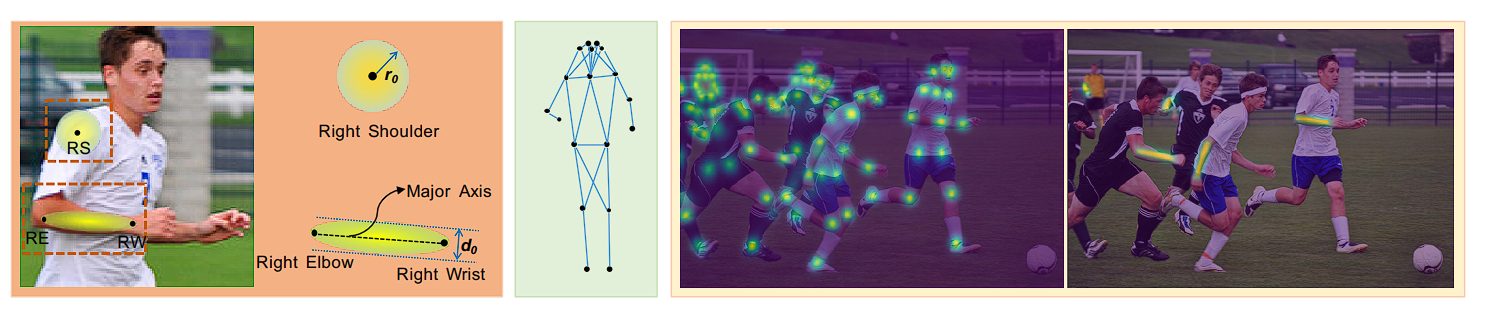
Symmetric Integral Keypoint Regression (SIKR)
Conventional soft-argmax (also known as integral regression) is differentiable and thus allows turning heatmap into a regression-based approach. However, this operation used for keypoint regression has an asymmetric gradient problem, this is where the absolute pixel position influences the gradient values. This causes translation invariance issues and affects the model’s accuracy.
Alphapose uses the Amplitude Symmetric Gradient (ASG) function. In this, the gradient distribution is centered at the predicted joint locations.
Size-dependent Keypoint Scoring Problem
In multi-person pose estimation, in the previous methods, the maximum value of the heatmap is taken as the joint confidence, which is size-dependent and not accurate.
Alphapose breaks down the process into two steps:
- First, it performs element-wise normalization using a sigmoid function to generate a confidence heatmap where the maximum value indicates joint confidence.
- Second, global normalization to produce a probability heatmap, which ensures predicted joint locations are within boundaries.
Multi-Domain Knowledge Distillation
Alphapose uses various data augmentation and dataset strategies to enhance the performance of the network (using additional datasets, e.g. 300Wface, FreiHand, and InterHand along with the annotated dataset to predict face and hand key points accurately).
Parametric Pose Non-Maximum Suppression (NMS) Problem with Redundant Pose Estimations
Pose estimation models primarily have two strategies: top-down and bottom-up.
Bottom-up (for example, OpenPose model) methods first detect various body parts such as hands and legs, whereas models like Alphapose use the top-down method, where it detects the human first and then estimates its pose. However, this method usually produces a lot of redundant pose estimations due to a low threshold set so that a maximum number of estimations are obtained for better recall.
To counter the redundant poses, Pose NMS is used, which defines pose similarity using a distance metric considering both key point matching and spatial distance. An iterative optimization approach based on a set of criteria is used to eliminate redundant poses.
Pose-Guided Attention Mechanism
To recognize the same individual across different images or video frames for pose tracking, person re-identification (re-ID) is required. This is performed by extracting unique features from each detected person in a bounding box. However, these bounding boxes include background clutter or parts of other people, which makes it difficult for re-identification.
To address this issue, the Pose-Guided Attention (PGA) mechanism is introduced in AlphaPose, to force the feature extraction of the human body of interest, and ignore the impact of the background.
In this method, a pose estimator generates heatmaps for key points of each detected person. These key points represent significant joints or parts of the human body (e.g., shoulders, elbows, knees).
- The generated keypoint heatmaps are then transformed into an attention map through a simple convolutional layer. This attention map has the same dimensions as the re-ID feature map.
- The attention map is applied to the re-ID feature map, producing a weighted re-ID feature map.
- Finally, the identity embedding (a 128-dimensional vector that uniquely represents the individual) is encoded by a fully connected layer.
Overview of the Working of AlphaPose
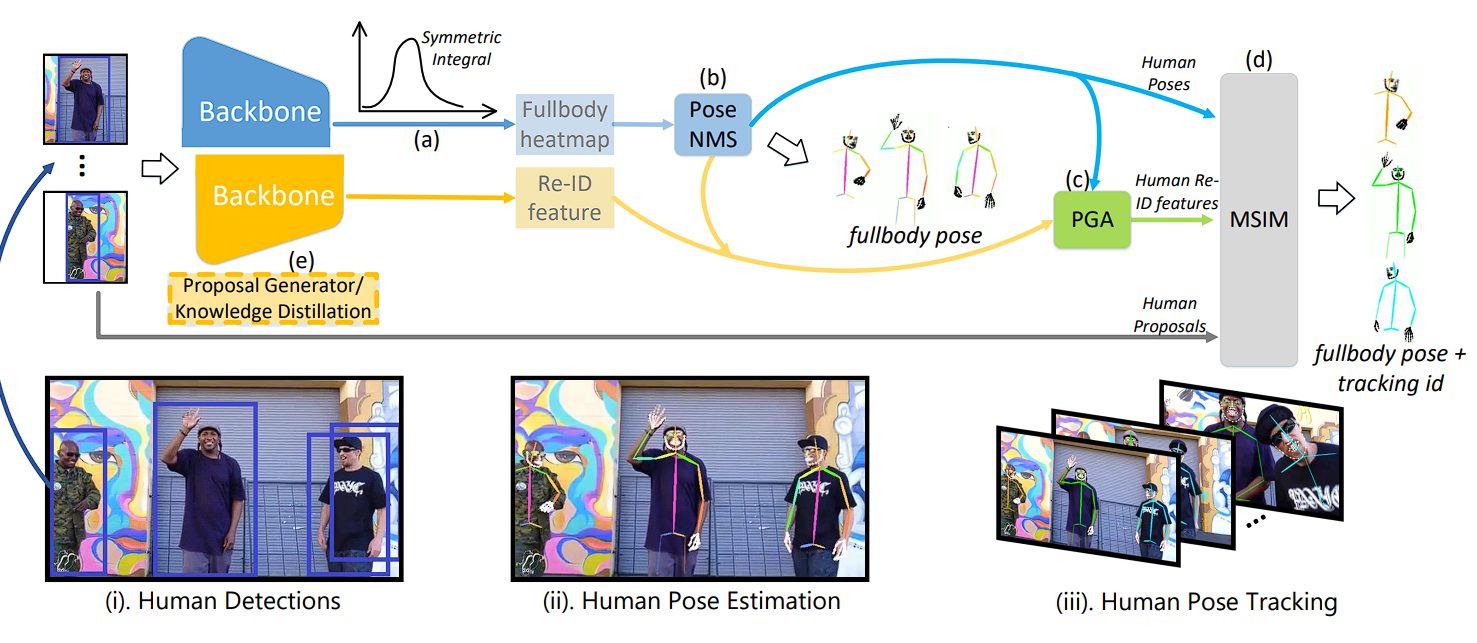
We have discussed several new techniques that AlphaPose utilizes, and combining all the techniques above, AlphaPose works as follows:
- Human Detection: The model takes an input image and uses object detectors such as YOLOv3 or EfficientNet to detect humans within the image.
- Pose Estimation and Tracking:
- For each detected human, the image is cropped and resized.
- The cropped image is then processed through pose estimation and tracking networks to obtain the full-body human pose and re-identification (Re-ID) features.
- Keypoint Localization:
- The models utilize symmetric integral regression for precise keypoint localization.
- Redundant Pose Elimination:
- Pose Non-Maximum Suppression (NMS) is employed to remove redundant poses.
- Pose-Guided Alignment (PGA):
- The PGA module is applied to the predicted human Re-ID features to obtain pose-aligned Re-ID features.
- Multi-Stage Identity Matching (MSIM):
- MSIM uses human poses, Re-ID features, and detected bounding boxes to produce the final tracking identity.
Comparison with Other Models
AlphaPose is one of several advanced models designed for multi-person pose estimation. Here are some other models similar to AlphaPose:
OpenPose
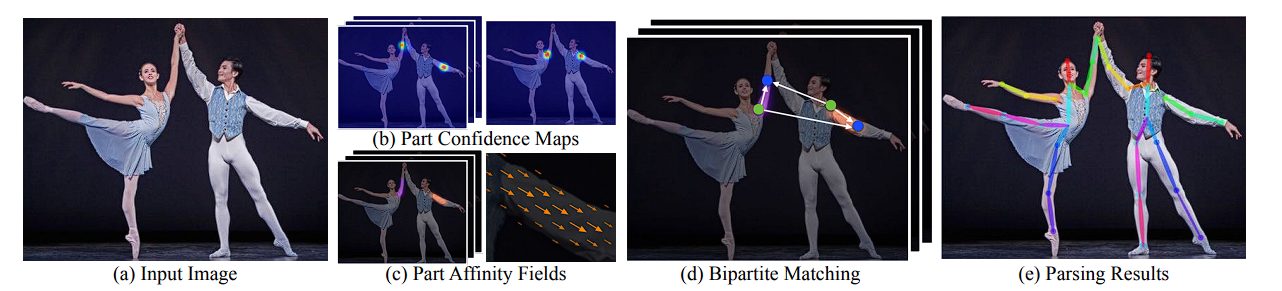
OpenPose is one of the most popular models that uses the bottom-up approach for pose estimation. It combines the detection and pose estimation stages into a single network.
OpenPose employs a different approach compared to AlphaPose. It integrates both the detection and pose estimation stages in a single network, whereas AlphaPose typically uses a two-stage approach with separate models for detection (e.g., Faster R-CNN or YOLO) and pose estimation. It does this by first detecting the body parts and then associating them with full-body poses using Part Affinity Fields (PAFs).
Moreover, OpenPose outputs both keypoint coordinates and confidence scores directly, whereas AlphaPose outputs heatmaps as an intermediate representation for key points.
PoseNet
PoseNet is a lightweight pose estimation model that uses a single-stage process, designed for real-time applications on mobile and embedded devices (can run on the browser using tensforflow.js), in contrast to Alphapose which is highly optimized for accuracy and robustness but requires higher computation.
HRNet (High-Resolution Network)

HRNet is another model for human pose estimation that focuses on preserving high-resolution details throughout the network as it uses a different architectural approach compared to AlphaPose’s design. HRNet maintains high-resolution representations throughout the network using parallel high-to-low-resolution subnetworks. This leads to high accuracy.
DeepLabCut
Alphapose utilizes a two-stage approach with separate detection and pose estimation models, whereas DeepLabCut uses a customizable deep neural network based on ResNet. One of the major advantages of this model is its transfer learning capabilities.
Moreover, another key difference is that DeepLabCut directly outputs keypoint coordinates instead of generating heatmaps.
A Recap of AlphaPose
In this blog, we looked at AlphaPose, which is a fast, accurate, and robust model for multiperson pose estimation and tracking. Alphapose uses a two-step process: first detecting human bounding boxes using models like Faster R-CNN or YOLO, then predicting key points within these boxes using specialized pose estimation networks.
Pose estimation models work by predicting the position of key points (such as joints) in humans. Alphapose does this by generating heat maps.
We also looked at various other models (such as PoseNet, and OpenPose) and compared them with AlphaPose. However, AlphaPose strikes a balance between speed and accuracy, with its innovative techniques such as Symmetric Integral Keypoint Regression (SIKR), Parametric Pose Non-Maximum-Suppression (P-NMS), and Pose Aware Identity Embedding for joint pose estimation and tracking.
To dive deeper into the world of computer vision, we suggest checking out our blogs on the following topics: