
Introduction to Spatio-Temporal Action Recognition
Many use the terms Spatio-Temporal Action Recognition, localization, and detection interchangeably. However, there is a subtle difference in exactly what they focus on.
Spatio-temporal action recognition identifies both the type of action that occurs and when it happens. Localization comprises the recognition as well as pinpointing its spatial location within each frame over time. Detection focuses on when an action starts and ends and how long it lasts in a video.
Let’s take an example of a video clip featuring a running man. Recognition involves identifying that “running” is taking place and whether it occurs for the whole clip or not. Localization may involve adding a bounding box over the running person in each video frame. Detection would go a step further by providing the exact timestamps of when the action of running occurs.
However, the overlap is significant enough that these three operations require virtually the same conceptual and technological framework. Therefore, for this article, we will occasionally refer to them as essentially the same.

There is a broad spectrum of applications across various industries with these capabilities. For example, surveillance, traffic monitoring, healthcare, and even sports or performance analysis.
However, using spatio-temporal action recognition effectively requires solving challenges regarding computational efficiency and accuracy under less-than-ideal conditions. For example, a video clip with poor lighting, complex backgrounds, or occlusions.
Training Spatio-Temporal Action Recognition Systems
There are limitless possible combinations of environments, actions, and formats for video content. Considering this, any action recognition system must be capable of a high degree of generalization. And when it comes to technologies based on deep learning, that means vast and varied data sets to train on.
Fortunately, there are various established databases from which we can choose. Google’s DeepMind researchers developed the Kinetics library, leveraging its YouTube platform. The latest version is Kinetics 700-2020, which contains over 700 human action classes from up to 650,000 video clips.
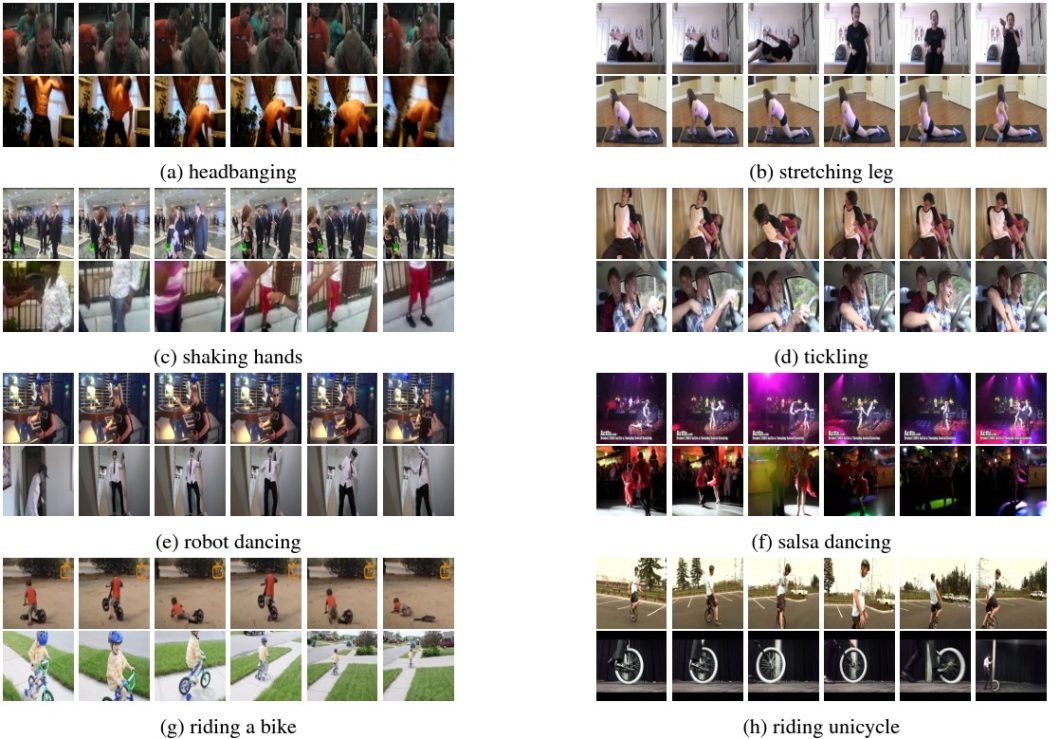
The Atomic Visual Actions (AVA) dataset is another resource developed by Google. However, it also provides annotations for both spatial and temporal locations of actions within its video clips. Thus, it allows for a more detailed study of human behavior by providing precise frames with labeled actions.
Recently, Google combined its Kinetics and AVA Datasets into the AVA-Kinetics dataset. It combines both the AVA and Kinetics 700-202 datasets, with all records annotated using the AVA method. With very few exceptions, AVA-Kinetics outperforms both individual models in training accuracy.
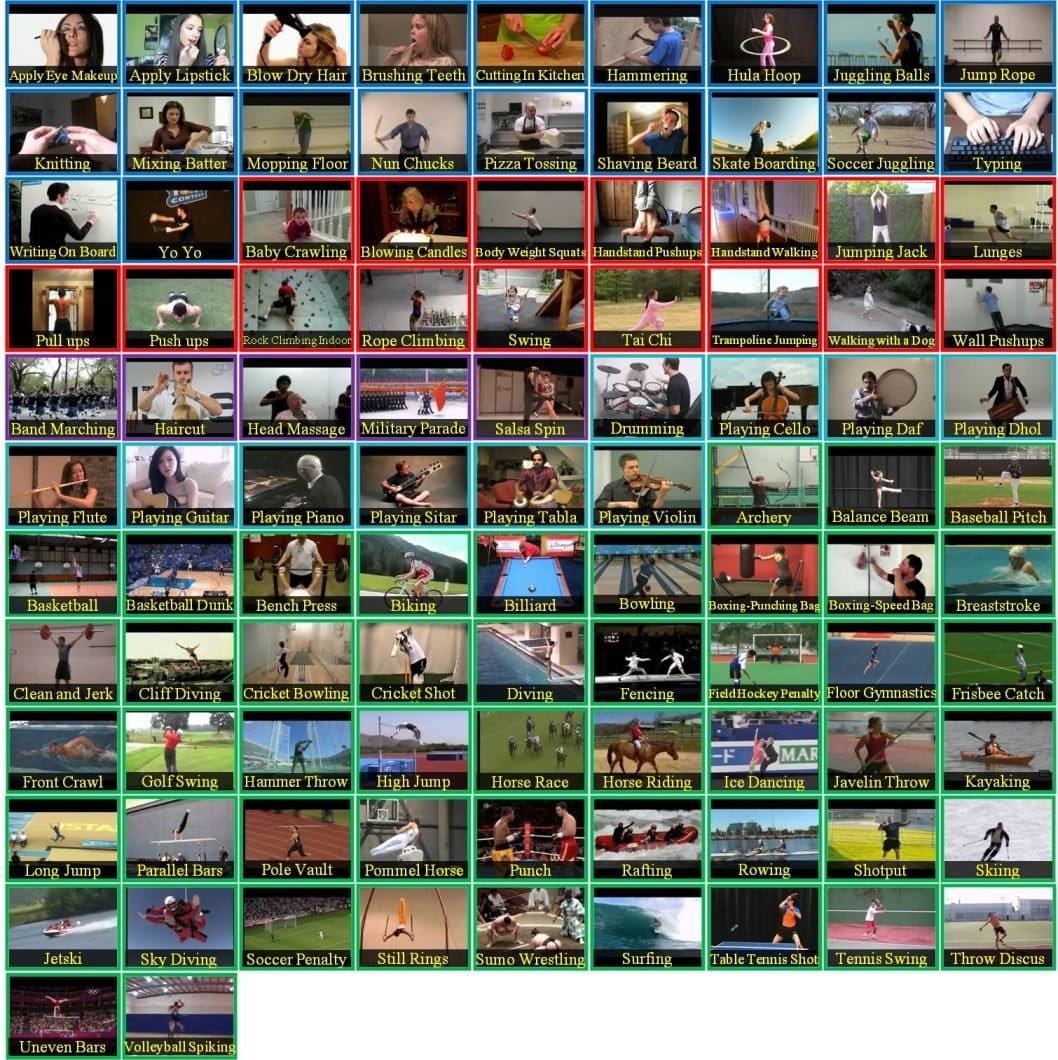
Another comprehensive source is UCF101, curated by the University of Central Florida. This dataset consists of 13320 videos with 101 action categories, grouped into 25 groups and divided into 5 types. The 5 types are Human-Object Interaction, Body-Motion Only, Human-Human Interaction, Playing Musical Instruments, and Sports.
The action categories are diverse and specific, ranging from “apply eye makeup” to “billiards shot” to “boxing speed bag”.
Labeling the actions in videos is not one-dimensional, making it somewhat complicated. Even the simplest applications require multi-frame annotations or those of both action class and temporal data.
Manual human annotation is highly accurate but too time-consuming and labor-intensive. Automatic annotation using AI and computer vision technologies is more efficient but requires computational resources, training datasets, and initial supervision.
There are existing tools for this, such as CVAT (Computer Vision Annotation Tool) and VATIC (Video Annotation Tool from Irvine, California). They offer semi-automated annotation, generating initial labels using pre-trained models that humans then refine.
Active learning is another approach where models are iteratively trained on small subsets of data. These models then predict annotations on unlabeled data. However, once again, they may require approval from a human annotator to ensure accuracy.
Spatio-Temporal Action Recognition With Deep Learning
As is often the case in computer vision, deep learning frameworks are driving important advancements in the field. In particular, researchers are working with the following deep learning models to enhance spatio-temporal action recognition systems:
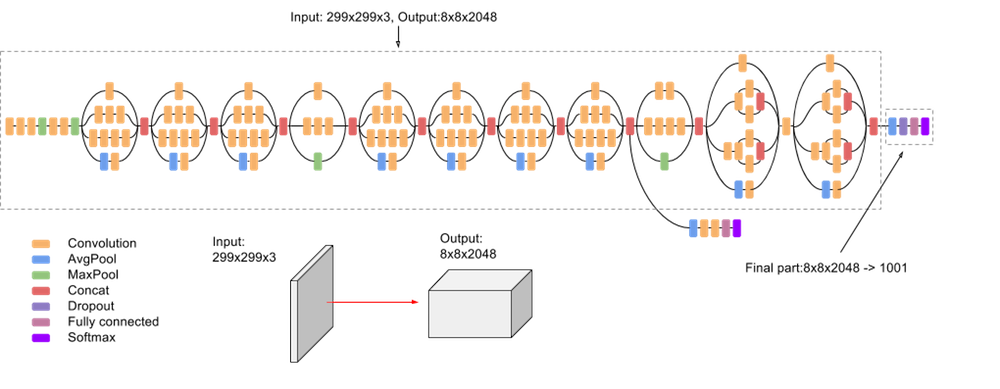
Model Architectures and Algorithms
Due to technological limitations, initial research focused separately on spatial and temporal features.
The predecessors of spatial-temporal systems today were made for stationary visuals. One particularly challenging field was that of identifying handwritten features. For example, Histograms of Oriented Gradients (HOG) and Histograms of Optical Flow (HOF).
By integrating these with support vector machines (SVMs), researchers could develop more sophisticated capabilities.
3D CNNs lead to some significant advancements in the field. By using them, these systems were able to treat video clips as volumes, allowing models to learn spatial and temporal features at the same time.
Over time, more work has been done to integrate spatial and temporal features more seamlessly. Researchers and developers are making progress by deploying technologies, such as:
- I3D (Inflated 3D CNN): Another DeepMind initiative, I3D is an extension of 2D CNN architectures used for image recognition tasks. Inflating filters and pooling kernels into 3D space allows for capturing both visual and motion-related information.
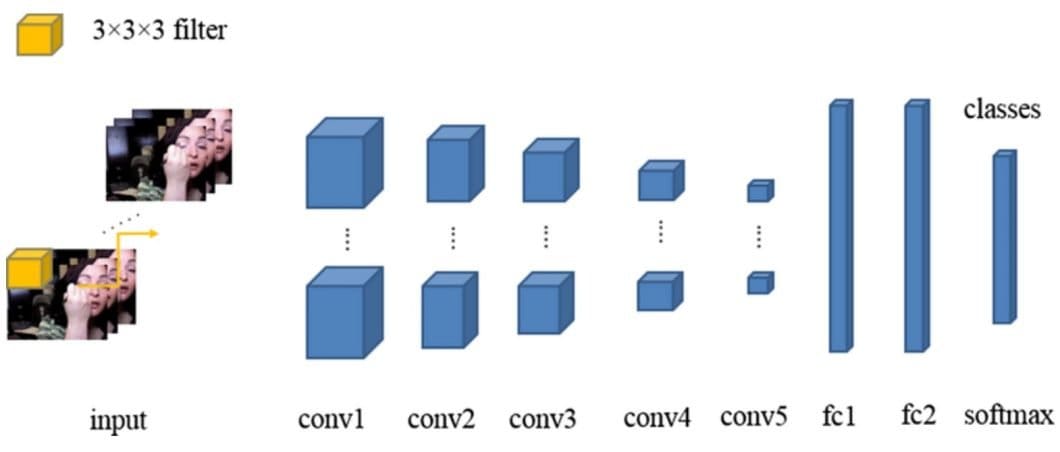
- Region-based CNNs (R-CNNs): This approach uses the concept of Regional Proposal Networks (RPNs) to capture actions within video frames more efficiently.
- Temporal Segment Networks (TSNs): TSNs divide a video into equal segments and extract a snippet from each of them. CNNs then extract features from each snippet and average out the actions in them to create a cohesive representation. This allows the model to capture temporal dynamics while being efficient enough for real-time applications.
The relative performance and efficiency of these different approaches depend on the dataset you train them on. Many consider I3D to be one of the most accurate methods, although it requires pre-training on large datasets. R-CNNs are also highly accurate but require significant computational resources, making them unsuited for real-time applications.
On the other hand, TSNs offer a solid balance between performance and computational efficiency. However, trying to cover the entire video can lead to a loss of fine-grained temporal detail.
Measuring Performance
Of course, researchers must have common mechanisms to measure the overall progress of spatial-temporal action recognition systems. With this in mind, there are several commonly used metrics to assess the performance of these systems:
- Accuracy: How well can a system correctly label all action classes in a video?
- Precision: What’s the ratio of correct positives to false positives for a specific action class?
- Recall: How many actions can the system detect in a single video?
- F1 score: A metric that’s a function of both a system’s precision and recall.
The F1 score is used to calculate what’s called the “harmonic mean” of the model’s precision and recall. Simply put, this means that the model needs a high score for both metrics to get a high overall F1 score. The formula for the F1 score is straightforward:
F1 = 2 (precision x recall / precision + recall)
An F1 score of one is considered “perfect.” In essence, it produces the average precision across all detected action classes.
The ActivityNet Challenge is one of the popular competitions for researchers to test their models and benchmark new proposals. Datasets like Google’s Kinetic and AVA also provide standardized environments to train and evaluate models. By including annotations, the AVA-Kinetics dataset is helping to improve performance across the field.
Successive releases (e.g., Kinetics-400, Kinetics-600, Kinetics-700) have enabled a continued effort to push the boundaries of accuracy.
To learn more about topics related to Computer Vision and Deep Learning Algorithms, read the following blogs:
- Explore the difference between CNN and ANN.
- An easy-to-understand guide to Deep Reinforcement Learning.
- Read an Introduction to Self-Supervised Learning.
- Learn about the difference between Deep Learning vs. Machine Learning.
- An introduction to Graph Neural Networks (GNNs).
- An Overview of Gradient Descent in Computer Vision.