The computer vision annotation tool CVAT provides a powerful solution for image annotation in computer vision. Computational vision is the research field that uses machines to collect and analyze images and videos to extract information from processed visual data.
Modern vision systems use machine learning and deep learning algorithms that must learn from images annotated by humans (supervised learning). CVAT is an open-source software tool for teams to create image and video annotations.
This article will cover the following topics:
What is CVAT?
CVAT for Businesses and Enterprises
Review and key features of CVAT
How to use the Computer Vision Annotation Tool?
Semi-automatic Image Annotation features and Artificial Intelligence (AI) tools
Get a Demo
Explore how Viso Suite helps organizations automate, optimize, and innovate with AI vision.
CVAT stands for Computer Vision Annotation Tool; it is a free, open-source digital image annotation tool written in Python and JavaScript. CVAT supports supervised machine learning tasks for object detection, image classification, image segmentation, and 3D data annotation.
The software tool recently gained high popularity among regular and commercial users. Hence, professional data annotation teams use it for developing supervised machine learning datasets. You can run CVAT on almost any modern operating system (Ubuntu, Windows, Mac)
The Computer Vision Annotation Tool (CVAT) for image and video annotation.
Who Developed CVAT?
Intel developed CVAT for computer vision image annotation. It is developed based on feedback from professional data annotation teams to make image annotation more streamlined for supervised problems in machine learning.
For training deep neural networks that are the core of AI vision, data scientists and computer vision professionals depend on a large amount of annotated data. Intel originally developed CVAT for internal use to provide a better method for large-scale image annotation of thousands of images.
This annotation process is very laborious and takes hundreds or thousands of hours. Therefore, the CVAT tool accelerates the process of annotating videos and images for use in training computer vision algorithms.
CVAT provides automatic labeling and semi-automated image annotation to speed up the annotation process and expedite annotation services (more about this later).
A deep learning model trained for AI vision inspection in Manufacturing
Where can I try CVAT?
CVAT is an open-source tool and can be hosted as a web-based online annotation tool. You can try it online on cvat.org without downloading any dependencies or packages for free. The online CVAT demo is limited to 500MB and 10 tasks per user. Also, the installation analytics are disabled.
CVAT for Business and Enterprise Teams
For professional computer vision annotation tasks, CVAT needs to be hosted in the cloud, secured, and integrated with enterprise-grade governance and operations tools. Several top-rated and popular enterprise computer vision annotation services and products are based on CVAT.
Businesses and organizations popularly use CVAT for image annotation, in combination with a broad set of additional tools for AI model management, application development, DevOps, deployment, operations, and edge device management.
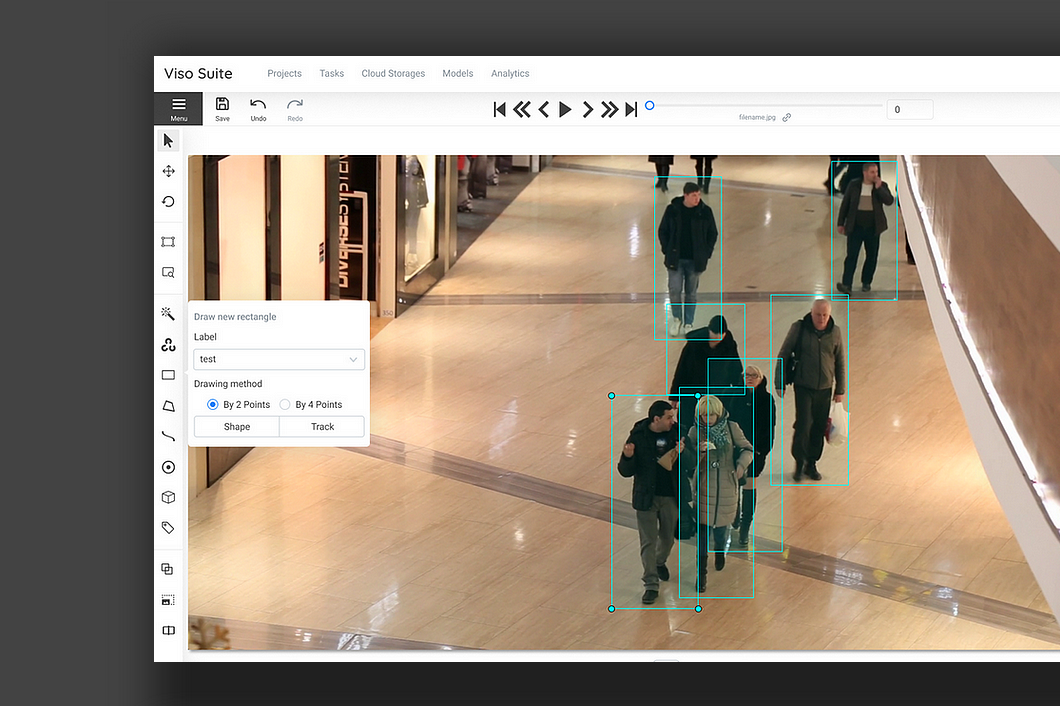
The end-to-end computer vision platform Viso Suite provides all those capabilities and integrates CVAT enterprise and business teams. Viso accelerates every step of the application development process and facilitates collaboration, governance, and scalability. The platform lets you collect video data to annotate with CVAT and manage, develop, deploy, and operate AI vision applications in one cloud workspace.
CVAT for business teams, as part of the computer vision platform Viso Suite
What is Image Annotation for CVAT?
The training of deep learning models, for example, for object detection and object recognition, requires extensive image collections with ground truth labels. Image annotation is the process of creating those labels on images from a dataset that can be used for model training (supervised learning). Those labels provide information about the object classes present in each image and their shape, locations, and additional attributes such as pose.
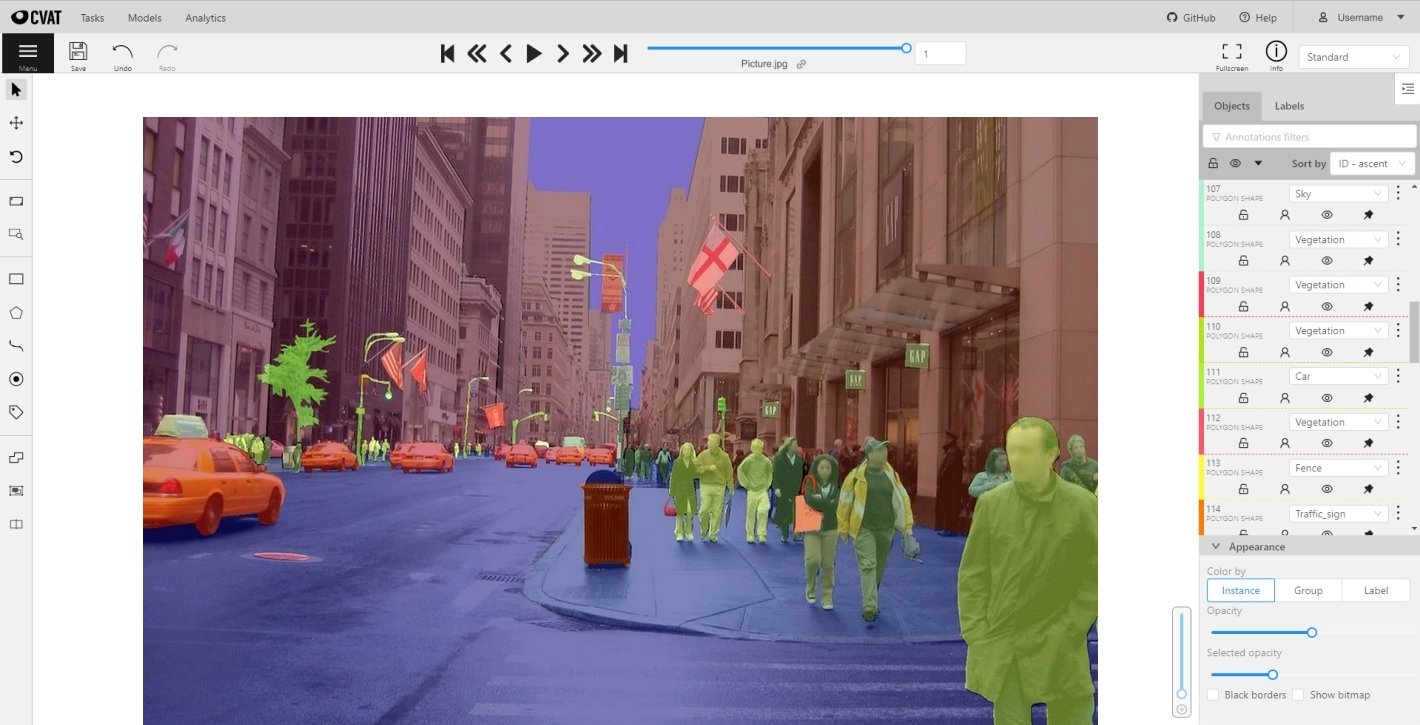
Annotation example with different shapes of the CVAT computer vision annotation tool – Source
What is an Image Annotation Tool?
Image annotation tools such as CVAT facilitate the creation of images or video frames by creating workflows, managing classes, and providing shapes (rectangles, polygons, etc.) to indicate the exact location of classes. Such tools for annotation can be run on a local computer or as web-based annotation tools that allow collaboration between team members.
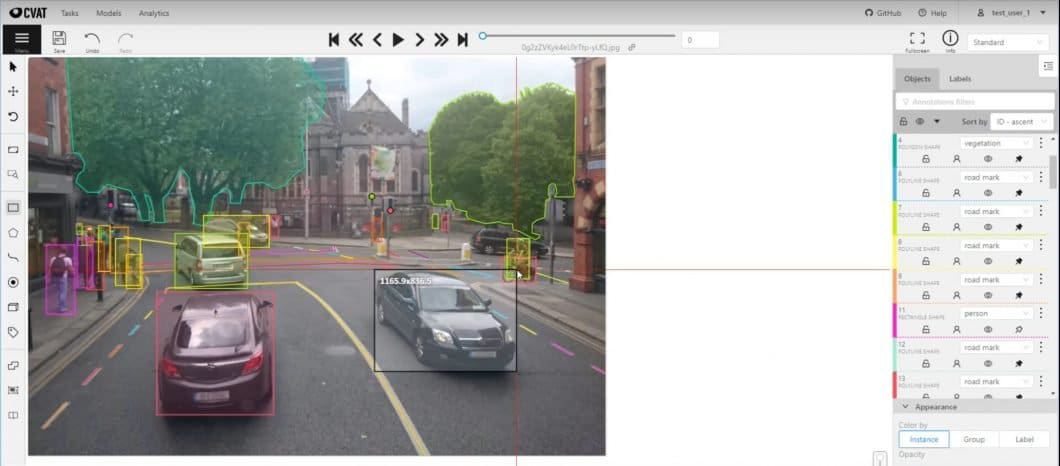
CVAT is one of the most popular computer vision annotation software tools
How to Annotate Images Faster
Image annotation to develop and train algorithms is a long and time-consuming process that can be very costly. Therefore, it shouldn’t be the AI engineers who annotate images but either an internal annotation team or an external image annotation company.
Image annotation services are provided by specialized companies that coordinate a workforce of qualified people and set up workflows to annotate images quickly. Annotation services are costly but provide sound quality that will impact the algorithm’s accuracy.
Outsourcing companies allow the workforce to annotate images quickly using the tools that are provided to them. This way is comparably cost-efficient, but the quality may not be sufficient if the annotators were not instructed well enough.
Internal data annotation tools like CVAT to efficiently annotate images and speed up the process. The software tool can quickly assign new tasks and manage the work process. It’s easy to balance the price and quality of the work.
CVAT Software Review
The CVAT interface makes the application remarkably easy to use for beginners and experts looking to build real-time vision systems. The image and video annotation software can be used entirely web-based without the need to install a local client. It supports work scenarios for both individuals and teams. Compared to other image annotation tools, CVAT provides many features (semi-automatic annotation, 3D annotation, keyframe interpolation, etc.) but is still very intuitive to use.
Advantages of CVAT
Advantage #1: CVAT is web-based; there is no installation of an application needed to annotate data.
Advantage #2: Users can collaborate and create a public task to split the work between other users.
Advantage #3: Automatic annotation in CVAT allows users to employ interpolation between keyframes.
Advantage #5: CVAT is suitable for integration into computer vision platforms, for example, Viso Suite.
Limitations of CVAT
Limitation #1: Limited browser support of CVAT requires the use of Google Chrome.
Limitation #2: Lack of source code documentation can make it challenging to understand the tool’s inner workings.
Limitation #3: Testing checks are manual, slowing the development process.
Key Features of CVAT
Automatic Annotation
Use the integrated features for typical annotation tasks such as automation. The most important automation tools are “copy and propagate” objects, interpolation, automatic annotation using the TensorFlow Object Detection API or other, visual settings shortcuts, filters, and more.
Interpolation Mode
CVAT can interpolate bounding boxes and attributes between multiple keyframes. This automatically annotates a set of images, for example, to not draw the same bounding box multiple times.
Attribute Annotation Mode
The attribute annotation mode of CVAT is optimized for image classification. It speeds up the process of attribute annotation by focusing on just one exact attribute.
In CVAT, you can upload annotations or dump annotations (download). There are multiple annotation formats to choose from; the formats below are supported for import and export:
What Types of Image Annotation Shapes are Available in CVAT?
CVAT offers the following shapes to annotate images:
Rectangle or Bounding box
Polygon
Polyline
Points
Cuboid
Cuboid in 3d task
CVAT different image annotation shapes overview. Upper row: 1) Rectangle, 2) Polygon, 3) Polyline. Lower row: 4) Points, 5) Cuboid, 6) Cuboid in 3D annotation.
Use Cases of CVAT
In the past 10 years, artificial neural networks (ANN) have shown great success in computer vision applications. The use of neural network-based solutions for computational vision depends on visual data (pictures, photos, videos, deep maps) to train an AI algorithm for image recognition and image processing tasks. When AI engineers develop neural network algorithms, they often face the problem of insufficient, reliable training data that is used as ground truth examples for model training. The amount of such data influences the prediction quality of the algorithm.
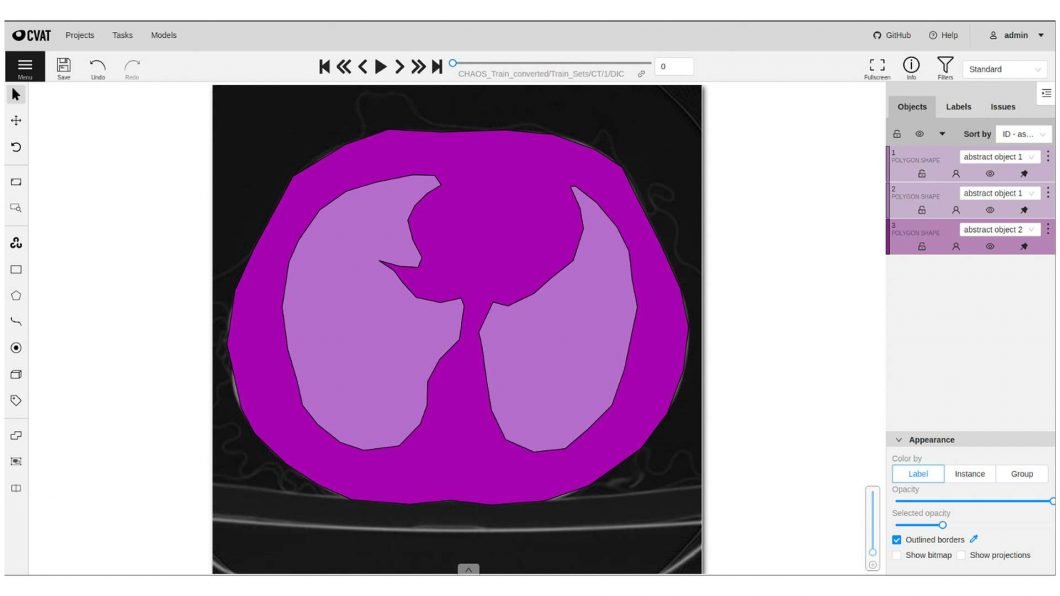
Since AI is a significant technology in medicine, especially in the times of the COVID-19 pandemic. There is a high demand for image annotation in medical use cases. CVAT is one of the few image annotation tools to label DICOM data (Digital Imaging and Communication in Medicine), a standard to store medical images and data in .dcm files. Hence, CVAT is an alternative to simple annotation tools such as md.ai or complex solutions with a lot of features for data annotation that come with restrictions for commercial use (medseg.ai).
While CVAT was not been developed to support the .dcm format, it is possible to use CVAT to annotate medical images. It is quite challenging since DICOM data may contain complex data with different content, such as CT (computed tomography), CR (computed radiography), LEN (lensometry), MR (magnetic-resonance therapy), and others, with a huge number of different attributes or tags specified. Some medical imaginary data could include multiple images (slices) that often cannot be interpreted as regular pixels since they are defined as physical values measured by a certain device.
The CVAT development team at Intel used the Python module of a library to convert DICOM files to regular images. Find a complete tutorial on how to use CVAT for medical image annotation here.
Step #1: Create an annotation task by providing the name, specifying the data labels using the constructor to enter the label, and setting the color.
Step #2: Provide the files (bulk images or video) loaded from a local computer, from your network, from a connected file share, or a remote source via URL.
Step #3: Create and open the task, and select a job link in the jobs list. Next, choose the correct section for your task type and start annotating using the annotation shapes, bounding box, polygon, etc.
Step #4: To download the annotations (dump annotation), save your changes first and select “Export task dataset” from the menu. Select the dump annotation format to start the download.
For a detailed step-by-step guide, check out the official documentation with the command line inputs here.
Semi-automatic and Automatic Annotation in CVAT
CVAT is optimized for semi-automatic and automatic image annotation with deep learning models. The use of AI tools requires that the corresponding models be available in the models section. CVAT provides built-in GPU support, but it requires you to install the Nvidia Container Toolkit and make sufficient GPU memory available.
Interactors
Create polygons semi-automatically with interactors. The interaction uses a deep learning model to get a mask for an object using positive points and negative points to determine the shape of the polygon (positive points are those related to the object). After placing the required number of points (depending on the model), the request is sent to the server to create a polygon. The created polygon can be adjusted by manually setting or removing points.
Semi-automatic annotation with interactors – Source
Deep Extreme Cut (DEXTR)
The deep extreme cut (DEXTR) model uses the information about the extreme points of an object to get its mask and convert it into a polygon. On CPU, this is the fastest interactor.
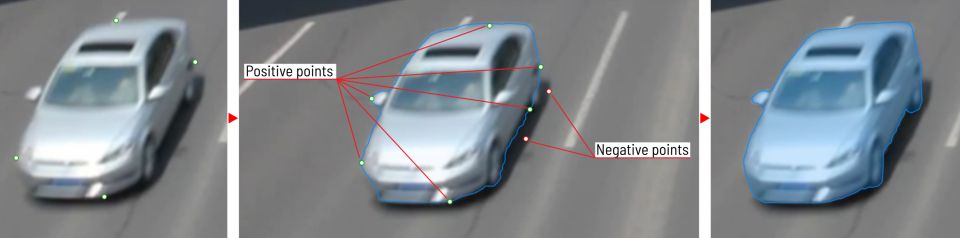
Inside-outside guidance is a model that uses a bounding box and points (inside/outside) to create a mask and create the polygon. Create the automated annotation with a bounding box that wraps the object. Set positive and negative points to tell the model where the object is and where the background is.
Semi-automatic image annotation with inside-outside guidance: 1) Draw bounding box, 2) Set positive points (object), 3) Set negative points (background, optional). – Source
Automatic Image Annotation Tools in CVAT
There are different ways to automate image annotation with CVAT. The two prominent use cases involve 1) preliminary annotations for multiple images or 2) model-based annotations in one image frame.
Create Preliminary Annotations for Tasks
Automatic image annotation uses deep learning models to create preliminary annotations and speed up the annotation process. In CVAT, primary AI models, or manually uploaded ones, can be used and managed from the models section.
Automated Annotation in One Image Frame
Detectors can automatically annotate image frame data with deep-learning models that support specific labels. CVAT supports the automated detection of objects. Select the DL model, match the model’s labels with the labels in your task, and click annotate.
Automatic Annotation Docs: Read more on how to use automated image annotation tasks with CVAT here.
OpenCV in CVAT
The OpenCV tools let you use computer vision models during annotation. The integrated tool is based on the OpenCV computer vision library, another open-source project that includes many computer vision algorithms. Some of them facilitate the annotation process.
The tools include Intelligent Scissors, a CV method of creating a polygon by placing points with the automatic drawing of a line between them.
Another tool is Histogram Equalization, a computer vision method that improves the contrast in an image to improve the intensity range, increase global contrast, and improve the brightness.
TrackerMIL includes multiple trackers to automatically annotate an object on video. The tracker is not bound to labels and can be used for any object. It can automatically track all labeled frames when moving to the next frame.
Start with Computer Vision CVAT
CVAT provides a free and simple image and video annotation tool for regular and commercial use. Individual developers, image annotation professionals, and labeling service providers can select their operating system and download and install the open-source image annotation tool by themselves.
Enterprises and businesses often use CVAT for their internal teams and need an integrated turnkey solution for image annotation and computer vision projects. Businesses can use CVAT as part of Viso Suite, which covers not only image annotation but the entire lifecycle of computer vision. This includes scalable infrastructure, security, model management, rapid development, edge device management, and more.
Read more about other topics related to computer vision, machine learning, deep learning, and AI.