
The concept of image segmentation has formed the basis of various modern Computer Vision (CV) applications. Segmentation models help computers understand the various elements and objects in a visual reference frame, such as an image or a video. Various kinds of segmentation techniques exist, such as panoptic or semantic segmentation. Each of these models has different working principles and applications.
As a result of the growing applications and the introduction of new use cases now and then, the image segmentation space has stretched thin. With a plethora of models to choose from, it becomes a challenge for developers working on practical implementations.
Understanding Segmentation
Before we dive into the intricacies of OMG-Seg, we’ll briefly recap on the topic of image segmentation. For more details, check out our Image Segmentation Using Deep Learning article.
Image segmentation models divide (or segment) an input image into various objects within that frame. It does so by recognizing the various entities present and generating a pixel mask to map the boundary and location of each.
Image segmentation works similarly to object detection but with a different approach to creating annotations. While object detection draws a rectangular boundary to indicate whether the detected object is present, segmentation labels pixels belonging to different categories, forming an accurate mask.

The granularity of image segmentation makes it useful for various practical applications such as autonomous vehicles, medical image processing, and segmenting satellite images.
However, the image segmentation domain consists of various categories. Each of these categories processes the image differently and produces different types of class labels. Let’s look into these categories in detail.
Types of Segmentation Models
Models address various segmentation tasks, including image segmentation, prompt-based segmentation, and video segmentation.
Image Segmentation
Image segmentation techniques include panoptic, semantic, and instance segmentation.
Semantic Segmentation: Classifies each pixel in an image into a category. Semantic segmentation tasks create a mask for every entity present in the entire image. However, its major shortcoming is that it does not differentiate between the various occurrences of the same object. For example, the cubes in the example below are all highlighted purple, and there is no information in the annotations to differentiate between their occurrences.

Instance Segmentation: Addresses the semantic segmentation problem. On top of creating pixel-level masks, it also generates labels to identify the instances of an object. It does so by combining object detection and semantic segmentation. The former identifies the various objects of interest, while the latter constructs pixel-perfect labels.
Instance segmentation is great for understanding countable visual elements, such as cups or cubes, but leaves out elements in the backdrop. These include the sky, the horizon, or a long-running road. These objects don’t exactly have various instances (or we say they can not be counted), but are an integral part of the visual canvas.
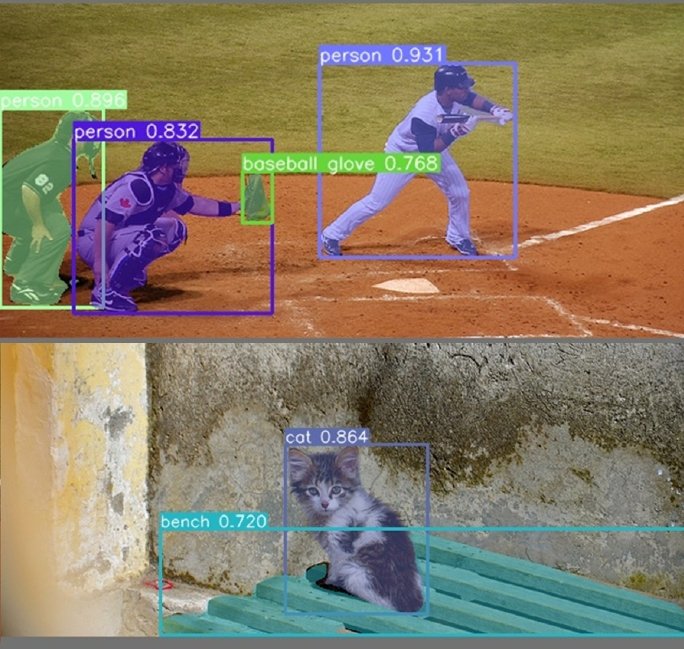
Panoptic Segmentation: Combines semantic and instance segmentation to provide details about every entity in an image. It processes the image to create instance-level labels for each object in focus and masks for background objects such as buildings, the sky, or trees.

Prompt-Based Segmentation
Moreover, modern image segmentation models are developed to handle real-life scenarios encompassing multiple seen and unseen objects. One such development is prompt-driven interactive segmentation.
Prompt-based Segmentation combines the power of natural language processing (NLP) and computer vision to create an image segmentation model. This model utilizes text and visual prompts to understand, detect, and classify objects within an image.
Luddecke and Ecker demonstrate the capabilities of using such prompts to classify previously unseen objects. The model can understand the object in question using the prompts provided. The text and visual prompts can be used in conjunction or independently to teach the model what needs to be segmented.
Video Segmentation
Most practical use cases of image segmentation employ it to real-time video feeds rather than single images. It treats a video as a group of images, applies segmentation to each, and groups together each masked frame to form a segmented video. Video segmentation is useful for self-driving cars and traffic surveillance applications.
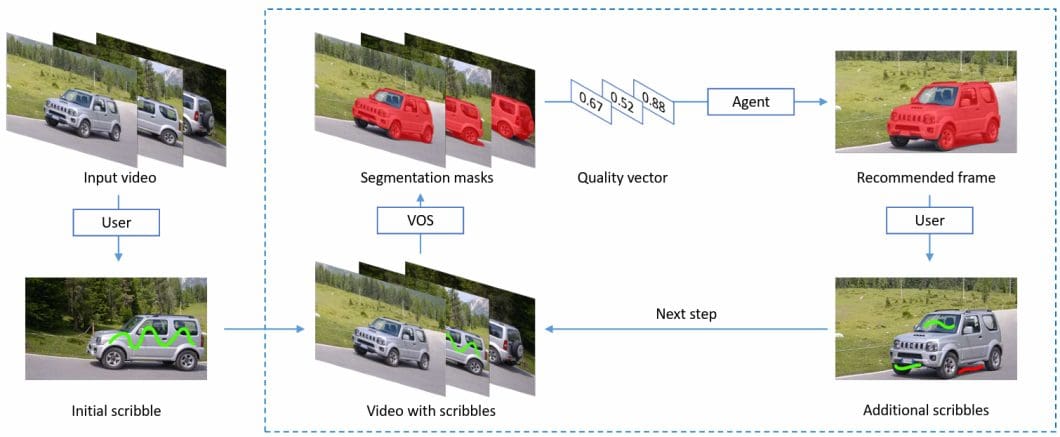
Modern video segmentation algorithms improve their results by utilizing frame pixels and causal information. These algorithms combine information from the present frame and context from previous frames to predict a segmentation mask. Other techniques for video segmentation include interactive segmentation.
This technique utilizes user input in an initial frame to localize the object. It then continues to generate segmentation masks in subsequent frames using the initial information.
Popular Image Segmentation Models
Mask-RCNN
The Mask Region-based Convolutional Neural Network (RCNN) was one of the most popular segmentation algorithms during Computer Vision’s early days. It improved upon its predecessor, Faster R-CNN, by outputting pixel-level masks rather than bounding boxes for detecting objects.
Its architecture consists of a CNN backbone (feature extractor) constructed from other popular networks like VGG or ResNet. Further, it uses a region-proposal network to narrow the search window for object locations. Lastly, it contains separate branches for object classification, detection, and mask formation for segmentation.
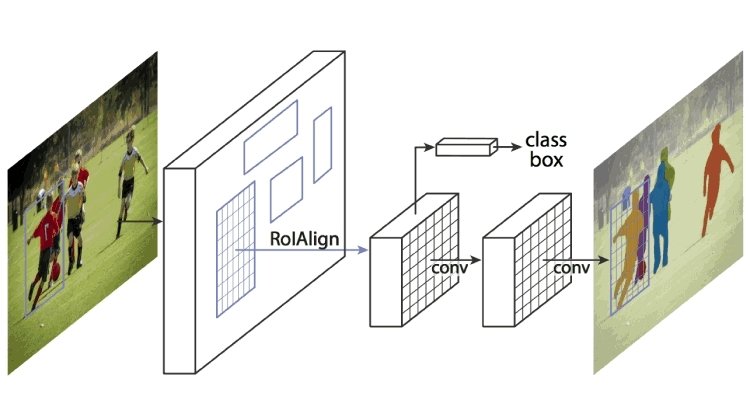
The model achieved state-of-the-art results on popular datasets such as COCO and Pascal VOC.
UNET
The U-Net architecture is popular for the semantic segmentation of Biomedical image data. Its architecture consists of a descending layer and an ascending layer. The descending layer is responsible for feature extraction and object detection via convolution and pooling layers.
The other reconstructs the features via deconvolution while generating masks for the detected object. The layers also have skip connections that connect their subsequent parts to pass information.
The final output is a feature map consisting of segmentations of objects of interest.
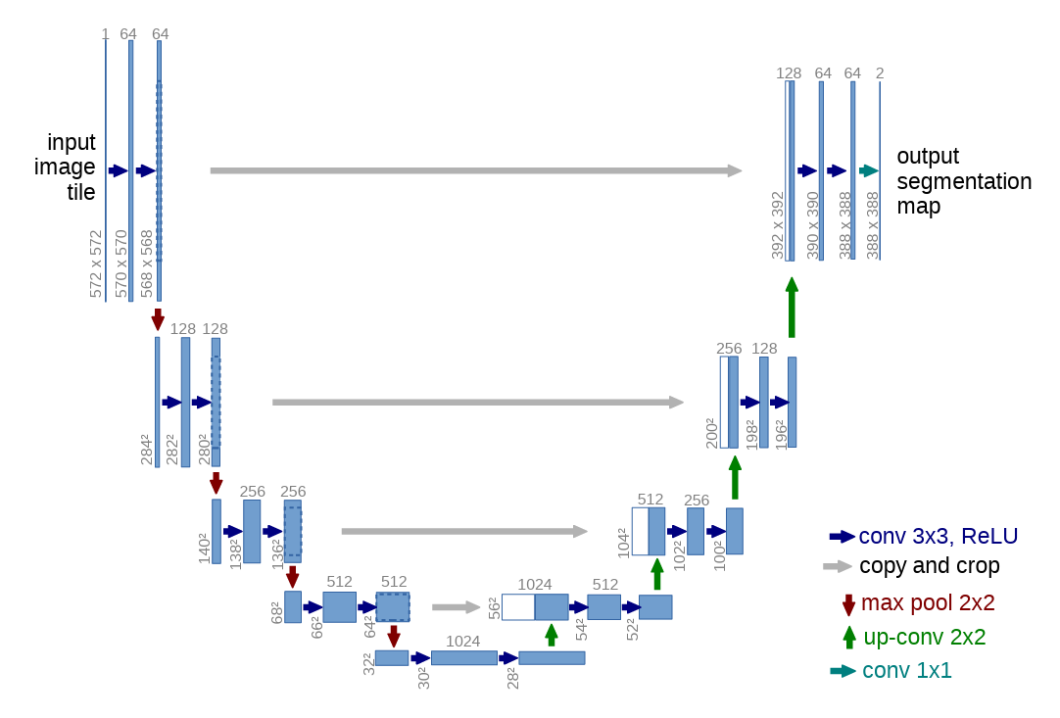
Over the years, the architecture has evolved to produce UNet++ and Attention UNet.
Segment Anything Model (SAM)
Segment Anything Model (SAM) is the perfect example of what modern computer vision looks like. This is an open-source image segmentation model developed by Meta and is trained on 11 Million images and over a billion masks.
SAM provides an interactive interface where users can simply click on the objects they want to segment or leave out of the segmentation. Moreover, it allows zero-shot generalization to segment images with a single input and a prompt. The prompt can be descriptive text, a rough bounding box, a mask, or just a few coordinates on the object to be segmented.
-

Segment Anything Model demo example

SAM’s architecture consists of an image encoder, a prompt encoder, and a mask decoder. The model is pre-trained on the SA-1B dataset, allowing it to generalize on new classes without re-training.
OMG-Seg: Unified Image Segmentation
So far, all the methodologies and architectures we have discussed were task-specific, i.e., plain image segmentation, video segmentation, prompt segmentation, etc. Each of these models has state-of-the-art results on their respective tasks, but it is challenging to deploy multiple models because of hardware costs and limited resources.

To solve this, Li et al. (2024) have introduced OMG-seg, an all-in-one segmentation model that can perform various segmentation tasks. The model is a transformer-based encoder-decoder architecture that supports over ten distinct segmentation tasks, including semantic, instance, and panoptic segmentation, as well as their video counterparts. It can also handle prompt-driven tasks, interactive segmentation, and open-vocabulary settings for easy generalization.
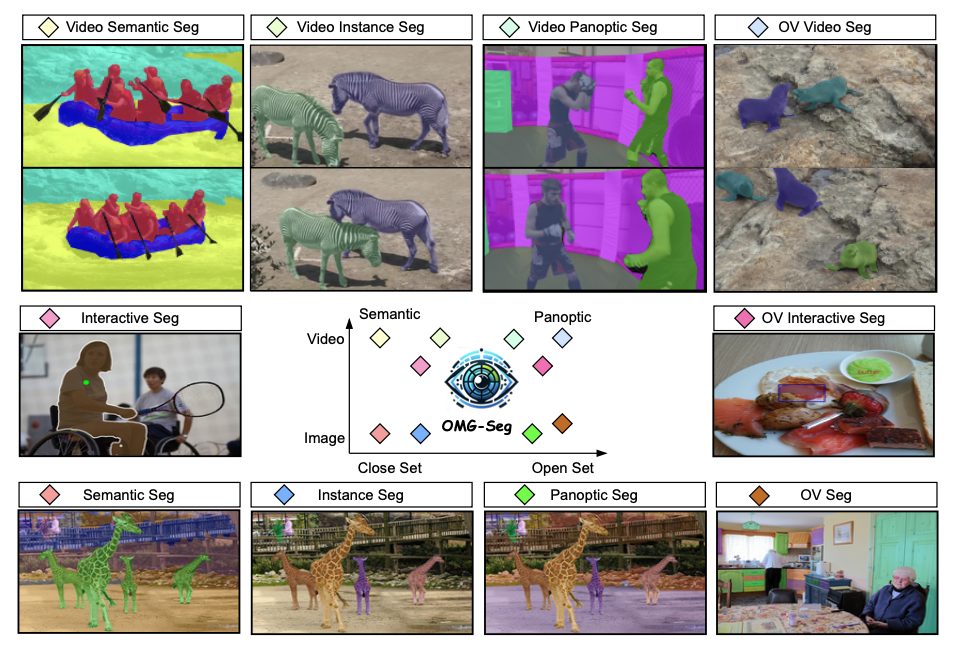
The segmentation classes included in the framework are as follows:
- Semantic
- Instance
- Panoptic
- Interactive
- Video Semantic
- Video Instance
- Video Panoptic
- Open-Vocabulary
- Open-Vocabulary Interactive
- Open-Vocabulary Video
OMG-Seg Architecture
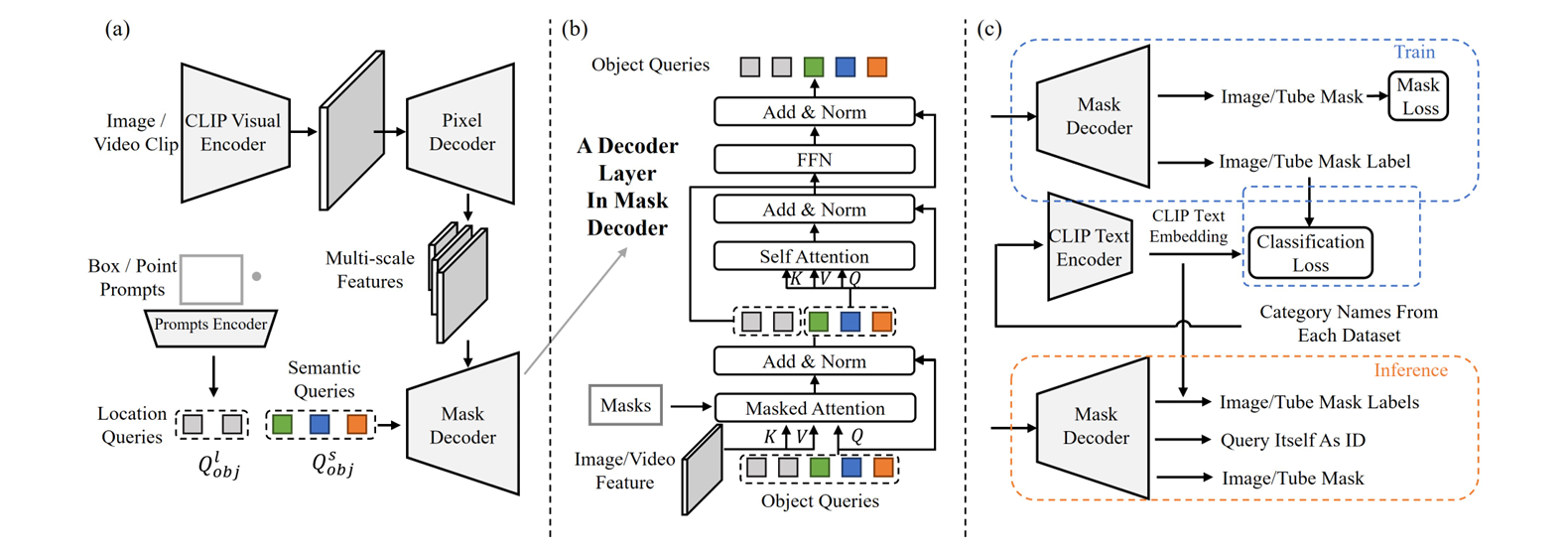
OMG-Seg follows a similar architecture to Mask2Former, including a backbone, a pixel decoder, and a mask decoder. However, it includes certain alterations to support the different tasks. This overall architecture consists of:
- VLM Encoder as a Backbone: OMG-Seg replaces the original backbone with the frozen CLIP model as a feature extractor. This Vision-Language Model (VLM) extracts multi-scale frozen features and enables open-vocabulary recognition.
- Pixel Decoder as Feature Adapter: The decoder consists of multi-layer deformable attention layers. It transforms the frozen features into fused features.
- Combined Object Queries: Each object query generates mask outputs for different tasks. For images, the object query focuses on object localization and recognition, while for videos, it also considers temporal features. For interactive segmentation, OMG-Seg uses the prompt encoder to encode the various visual prompts into the same shape as object queries.
- Shared Multi-task Decoder: The final mask decoder takes in the fused features from the pixel decoder and the combined object queries to produce the segmentation mask. The layer uses a multi-head self-attention for image segmentation and combines pyramid features for video segmentation.
Training and Benchmarks
The model is trained for all segmentation tasks simultaneously. It uses a joint image-video dataset and a single entity label and mask for the different types of segmentations present. Further, it replaces the classifier with the CLIP text embeddings to avoid cross-dataset taxonomy conflicts.
OMG-Seg explores co-training on various datasets, including COCO panoptic, COCO-SAM, and Youtube-VIS-2019. Each helps develop different tasks, such as panoptic segmentation and open vocabulary settings.
The training was conducted in a distributed training environment using 32 A100 GPUs. Each mini-batch included one image per GPU, and large-scale jitter was introduced for augmentation.
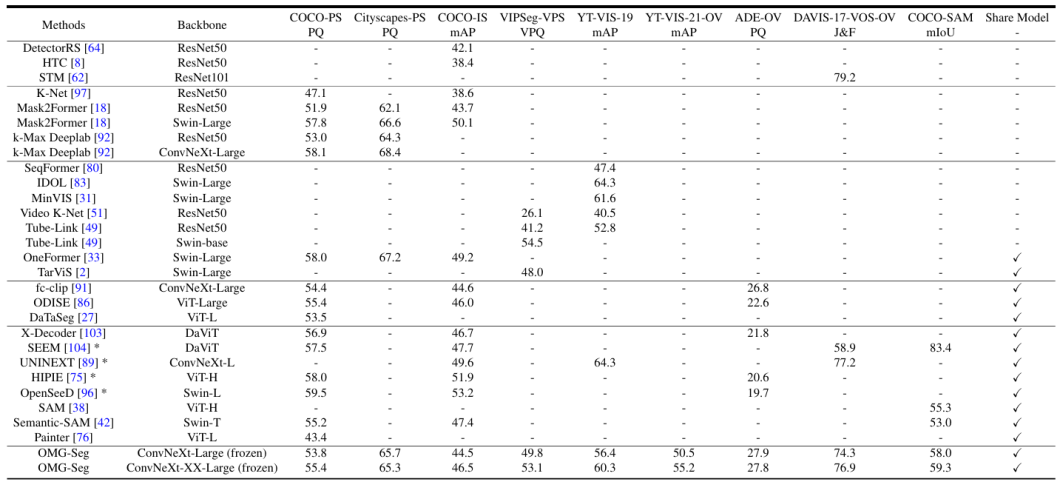
The above table has two interesting takeaways.
- It showcases the wide array of datasets (hence tasks) OMG-Seg can work with.
- Its performance against each task is quite comparable to, if not better than, the competitor models.
OMG-Seg: Key Takeaways
The image segmentation domain covers various tasks, including image, semantic, instance, panoptic, video, and prompt-based segmentation. Each of these tasks is performed by different models on different datasets.

OMG-Seg introduces a unified model for several segmentation tasks. Here’s what we learned about it:
- Having different models introduces practical limitations during application integration.
- OMG-Seg performs over ten segmentation tasks from a single model.
- The tasks include Instance, Semantic, Panoptic Segmentation, and their video counterparts. It also works on open-vocabulary settings and interactive segmentation.
- Most of its architecture follows that of the Mask2Former model.
- The model displays comparable performance against popular models such as SAM and Mask2Former on datasets like COCO and CityScapes.
Modern machine learning has come a long way. Here are a few topics where you can learn more about Computer Vision:
- Computer Vision in Robotics – An Autonomous Revolution
- Image Segmentation with Deep Learning (Guide)
- Semantic vs Instance Segmentation
- Grounded-SAM: Explained: A New Image Segmentation Paradigm?