
A Vision Processing Unit (VPU) is a computing chip that is optimized for AI tasks. Therefore, VPUs enable the transition of computer vision and deep learning from the laboratory setting to real-world applications.
About us: Viso Suite is our end-to-end computer vision enterprise infrastructure. With Viso Suite, businesses gain full control of the application lifecycle and can realize time to value in just three days. Learn more by booking a demo with our team.
Megatrend Deep Learning
The recent advances in deep learning methods and convolutional neural networks (CNNs) have drastically impacted the role of machine learning in a wide range of computer vision tasks.
With deep learning, object classification, and object detection accuracy have been greatly improving. The inference error rate of machine learning algorithms has become remarkably low and reaches a state that already surpasses human performance in certain scenarios (e.g., in face recognition).
Optimized Deep Learning Hardware
With the deep learning trend comes the need for new specialized hardware architectures that enable higher performance for machine learning tasks, both during training and inference.
The use of general-purpose processors for machine learning applications is limited, mainly due to the irregularity of memory access that comes with long memory stalls and large bandwidth requirements. As a side effect, this leads to significant increases in power consumption and thermal dissipation requirements.
Innovations at the software level introduced novel data formats that use tensors. A tensor is a generalization of vectors and matrices, easily understood as a multidimensional array. These breakthroughs provide multiple advantages in terms of performance and power consumption.
The industry is shifting towards designing processors where cost, power, and thermal dissipation are key concerns. Hence, specialized co-processors have emerged to reduce energy consumption constraints while improving the overall computing performance for deep learning tasks.
Therefore, the adoption of power-efficient AI accelerators for computer vision and machine learning on the “edge”, or Edge AI, is an important field in robotics and the Internet of Things (IoT).
What is a VPU (Vision Processing Unit)?
A Vision Processing Unit (VPU) is a type of processor that emerges as a category of chips that aims to provide ultra-low power capabilities without compromising performance. Hence, Vision Processing Unit chips are optimized to perform inference tasks using pre-trained convolutional network (CNN) models.
The term “vision” relates to the chips’ original purpose, which is to accelerate computer vision applications on the “edge”. The multicore, always-on system chips are optimized to power computer vision for the edge, mobile, and embedded applications.
Myriad 2 VPU
A popular exponent is the Movidius Myriad 2 VPU based on the Intel Neural Compute Stick (NCS) platform that can be used for inference in convolutional networks with a pre-trained network.
The Myriad 2 VPU is designed as a 28-nm co-processor that provides high-performance tensor acceleration. Hence, it provides high-level APIs that allow application programmers to easily take advantage of its features and a software-controlled memory subsystem that enables fine-grained control of different workloads.
The architecture of this chip is inspired by the observation that beyond a certain frequency limit for any particular design and target process technology, the cost is quadratic in power for linear increases in operating frequency. The Myriad 2 VPU was designed following this principle, with 12 highly parallelizable vector processors, named Streaming Hybrid Architecture Vector Engines (SHAVE). Its parallelism and instruction set architecture provide highly sustainable performance efficiency across a range of computer vision applications, including those with low latency requirements on the order of milliseconds.
The Myriad 2 VPU aims to provide an order of magnitude higher performance efficiency, allowing high-performance computer vision systems with very low latency to be built while dissipating less than 1 watts.
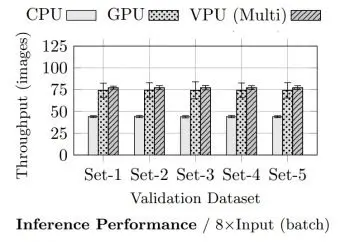
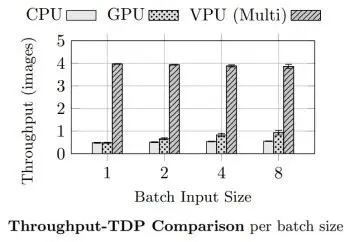
Performance benchmarks have shown that a combination of multiple VPU chips can potentially provide equivalent performance compared to a reference CPU and GPU-based system while reducing the thermal-design power (TDP) up to 8 times.
Meanwhile, the number of inferences per watt of VPUs is over 3 times higher in comparison to reference CPU or GPU systems. In tests, the estimated top-1 error rate was 32% on average, with a confidence error difference of 0.5%.
Myriad X VPU
Intel’s Myriad X VPU is the third generation and the most advanced VPU from Movidius. The Myriad X VPU, for the first time in its class, features the Neural Compute Engine, a specialized AI dedicated hardware accelerator for deep neural network deep-learning inferences.
The Neural Compute Engine, in conjunction with the 16 SHAVE cores and an ultra-high throughput (Movidius states that it can achieve over one trillion operations per second of peak DNN inferencing throughput), makes Myriad X a popular option for on-device deep neural networks and computer vision applications.
The Myriad X VPU has a native 4K image processor pipeline with support for up to 8 HD sensors connecting directly to the VPU. As with Myriad 2, the Myriad X VPU is programmable via the Myriad Development Kit (MDK), which includes development tools, frameworks, and APIs to implement custom vision, imaging, and deep neural network workloads on the chip.
How to use VPUs to Power AI Vision Systems
Movidius Neural Compute Stick 2 (NCS) is a tiny fanless USB deep-learning device built on the latest Intel Movidius Myriad X VPU. Those Vision Processing Units are used to power scalable, always-on computer vision applications at the edge (Edge Intelligence).
You can use the development kits provided by Intel to deploy pre-trained and custom-trained models to an edge computing device (for example, an Intel NUC or any comparable computing device) connected to a VPU via a USB port. So, multi-VPU solutions are commonly built using a USB hub to connect up to 8 NCS devices to one edge computer.
While you can code a solution yourself, using a low-code platform is most likely the easiest way to use VPUs, because you don’t need to worry about container deployment, security, infrastructure, DevOps, and everything else around your AI solution.
Therefore, dedicated software platforms can efficiently distribute and scale AI algorithms to distributed edge devices. Low-code platforms like Viso Suite are built to integrate software for AI processing with next-gen AI hardware, offering an integrated workspace to build your AI solutions and deploy them to edge devices with one or multiple VPUs (multi-device computing ready).
A wide range of vision-based deep learning applications can be powered using vision processing units, for example, people counting systems or human fall detectors.

What’s Next?
If you want to learn more about other computer vision topics, we recommend you read the following articles:
- An overview of Deep Face Recognition in 2022
- Read about Self-Supervised Learning
- A guide to Edge AI to democratize AI
- Learn about Fall Detection applications
Viso is a member of the Intel Partner Alliance and provides next-gen technology to leverage Intel Edge AI technology for computer vision applications. Book a demo to learn more about Viso Suite.

