Experiment tracking, or experiment logging, is a key aspect of MLOps. Tracking experiments is important for iterative model development, which is the part of the ML project lifecycle where you try many things to get your model performance to the level you need.
What is Experiment Tracking for Machine Learning?
Experiment tracking is recording relevant metadata while developing a machine learning model. It provides researchers with a method to keep track of important changes during each iteration.
In this context, “experiment” refers to a specific iteration or version of the model. You can think of it in terms of any other scientific experiment:
- You start with a hypothesis, i.e., how new changes will impact the outcomes.
- Then, you adjust the inputs (code, datasets, or hyperparameters) accordingly and run the experiment.
- Finally, you record the outputs. These outputs can be the results of performance benchmarks or an entirely new ML model.
Machine learning experiment tracking makes it possible to trace the exact cause and effect of changes to the model.
These parameters include, amongst others:
- Hyperparameters: Learning rate, batch size, number of layers, neurons per layer, activation functions, dropout rates.
- Model Performance Metrics: Accuracy, precision, recall, F1 score, area under the ROC curve (AUC-ROC).
- Training Parameters: Number of epochs, loss function, optimizer type.
- Hardware Usage: CPU/GPU utilization, memory usage.
- Dataset Metrics: Size of training/validation/test sets, data augmentation techniques used.
- Training Environment: Configuration files of the underlying system or software ecosystem.
- Versioning Information: Model version, dataset version, code version.
- Run Metadata: Timestamp of the run, duration of training, and experiment ID.
- Model-specific Data: Model weights or other tuning parameters.
Experiment tracking involves tracking all information to create reproducible results across every stage of the ML model development process.
Why is ML Experiment Tracking Important?
We derive machine learning models through an iterative process of trial and error. Researchers can adjust any number of parameters in various combinations to produce different results. A model can also go through an immense number of adaptations or versions before it reaches its final form.
Without knowing the what, why, and how, it’s impossible to draw informed conclusions about the model’s progress. Unfortunately, due to the complexity of these models, the causality between inputs and outputs is often non-obvious.
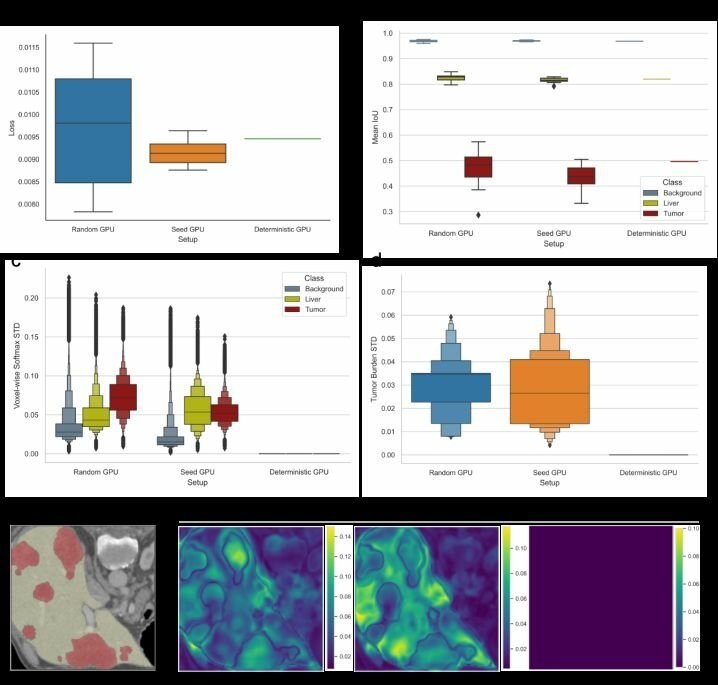
learning – source.
A small change in any of the parameters above can significantly change the output. An ad hoc approach to tracking these changes and their effects on the model simply won’t cut it. This is particularly important for related tasks, such as hyperparameter optimization.
Data scientists need a formal process to track these changes over the lifetime of the development process. Experiment tracking makes it possible to compare and reproduce the results across iterations.
This allows them to understand past results and the cause-and-effect of adjusting various parameters. More importantly, it will help to steer the training process in the right direction.
How does an ML Experiment Tracking System work?
Before we look at different methods to implement experiment tracking, let’s see what a solution should look like.
At the very least, an experiment-tracking solution should provide you with:
- A centralized hub to store, organize, access, and manage experiment records.
- Easy integration with your ML model training framework(s).
- An efficient and accurate way to capture and record essential data.
- An intuitive and accessible way to pull up records and compare them.
- A way to leverage visualizations to represent data in ways that make sense to non-technical stakeholders.
For more advanced ML models or larger machine learning projects, you may also need the following:
- The ability to track and report hardware resource consumption (monitoring of CPU, GPU utilization, and memory usage).
- Integration with version control systems to track code, dataset, and ML model changes.
- Collaboration features to facilitate team productivity and communication.
- Custom reporting tools and dashboards.
- The ability to scale with the growing number of experiments and provide robust security.
Experiment tracking should only be as complex as you need it to be. That’s why techniques vary from manually using paper or spreadsheets to fully automated commercial-off-the-shelf tools.
The centralized and collaborative aspect of experiment tracking is particularly important. You may conduct experiments on ML models in a variety of contexts. For example, on your office laptop at your desk. Or to run an ad hoc hyperparameter tuning job using a dedicated instance in the cloud.
Now, extrapolate this challenge across multiple individuals or teams.
If you don’t properly record or sync experiments, you may need to repeat work. Or, worst case, lose the details of a well-performing experiment.
Best Practices in ML Experiment Tracking
So, we know that experiment tracking is vital to accurately reproduce experiments. It allows debugging and understanding ML models at a granular level. We also know the components that an effective experiment tracking solution should consist of.
However, there are also some best practices you should stick to.
- Establish a standardized tracking protocol: You need to have a consistent practice of experiment tracking across ML projects. This includes standardizing code documentation, version documentation, data sets, parameters (input data), and results (output data).
- Have rigorous version control: Implement both code and data version control. This helps track changes over time and to understand the impact of each modification. You can use tools like Git for code and DVC for data.
- Automate data logging: You should automate experiment logging as much as possible. This includes capturing hyperparameters, model architectures, training procedures, and outcomes. Automation reduces human error and enhances consistency.
- Implement meticulous documentation: Alongside automated logging, explain the rationale behind each experiment, the hypotheses tested, and interpretations of results. Contextual information is invaluable for future reference when working on dynamic ML models.
- Opt for scalable and accessible tracking tools: This will help avoid delays due to operational constraints or the need for training.
- Prioritize reproducibility: Check that you can reproduce the results of individual experiments. You need detailed information about the environment, dependencies, and random seeds to do this accurately.
- Regular reviews and audits: Reviewing experiment processes and logs can help identify gaps in the tracking process. This allows you to refine your tracking system and make better decisions on future experiments.
- Incorporate feedback loops: Similarly, this will help you incorporate learnings from past experiments into new ones. It will also help with team buy-in and address shortcomings in your methodologies.
- Balance detail and overhead: Over-tracking can lead to unnecessary complexity, whereas insufficient tracking can miss critical insights. It’s important to find a balance depending on the complexity of your ML models and needs.

Difference Between Experiment Tracking and MLOps
If you work in an ML team, you’re probably already familiar with MLOps (machine learning operations). MLOps is the process of holistically managing the end-to-end machine learning development lifecycle. It spans everything from:
- Developing and training models,
- Scheduling jobs,
- Model testing,
- Deploying models,
- Model maintenance,
- Managing model serving, to
- Monitoring and retraining models in production
Experiment tracking is a specialized sub-discipline within the MLOps field. Its primary focus is the iterative development phase, which involves primarily training and testing models. Not to mention experimenting with various models, parameters, and data sets to optimize performance.
More specifically, it’s the process of tracking and utilizing the relevant metadata of each experiment.
Experiment tracking is especially critical for MLOps in research-focused projects. In these projects, models may never even reach production. Instead, experiment tracking offers valuable insights into model performance and the efficacy of different approaches.
This may help inform or direct future ML projects without having an immediate application or end goal. MLOps is of more critical concern in projects that will enter production and deployment.
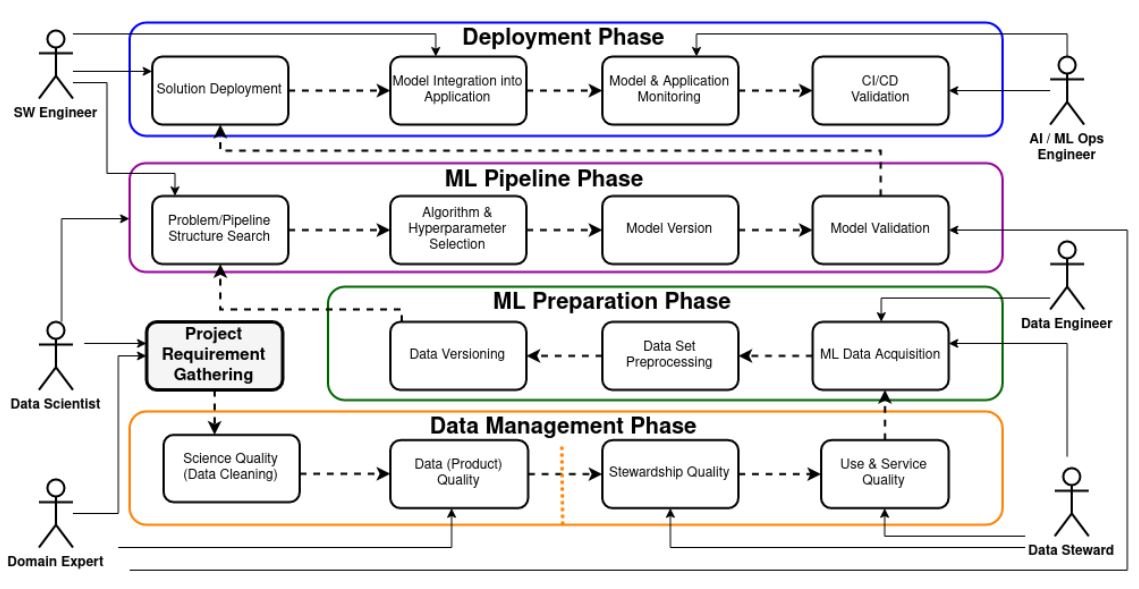
How to Implement Experiment Tracking
Machine learning projects come in different shapes and sizes. Accordingly, there are a variety of ways you can track your experiments.
You should carefully select the best approach depending on:
- The size of your team
- The number of experiments you plan to run
- The complexity of your ML models
- The level of detail you require regarding experiment metadata
- The key goals of your project/research. I.e., improving capabilities in a specific task or optimizing performance
Some of the common methods used today include:
- Manual tracking using spreadsheets and naming conventions
- Using software versioning tools/repositories
- Automated tracking using dedicated ML experiment tracking tools
Let’s do a quick overview of each.
Manual Tracking
This involves using spreadsheets to manually log experiment details. Typically, you’ll use systematic naming conventions to organize files and experiments in directories. For example, by naming them after elements like model version, learning rate, batch size, and main results.
For example, model_v3_lr0.01_bs64_acc0.82.h5 might indicate version 3 of a model with a learning rate of 0.01, a batch size of 64, and an accuracy of 82%.
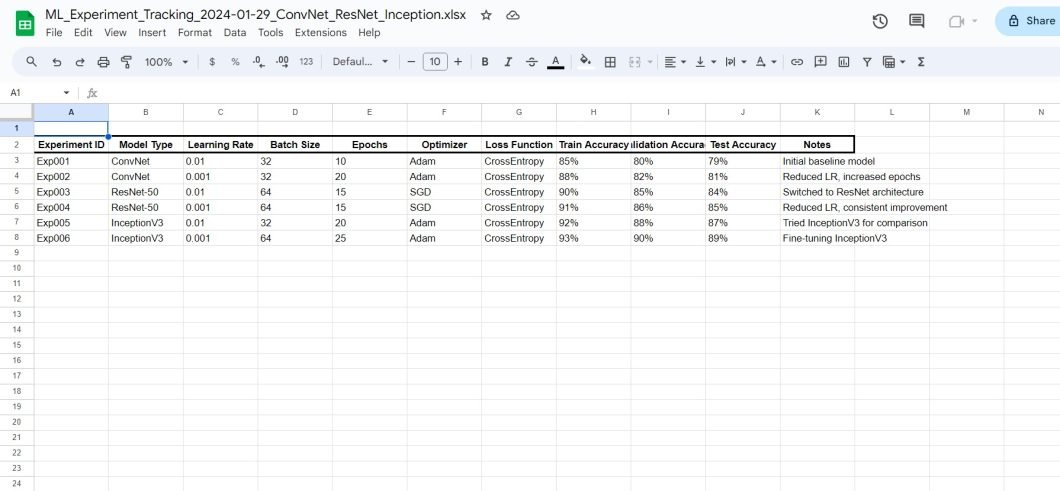
This method is easy to implement, but it falls apart at scale. Not only is there a risk of logging incorrect information, but also of overwriting others’ work. Plus, manually ensuring version tracking conventions are being followed can be time-consuming and difficult.
Still, it may be suitable for small-scale or personal research projects using tools like Excel or Google Sheets.
Automated Versioning in a Git Repository
You can use a version control system, like Git, to track changes in machine learning experiments. Each experiment’s metadata (like hyperparameters, model configurations, and results) is stored as files in a Git repository. These files can include text documents, code, configuration files, and even serialized versions of models.
After each experiment, it commits changes to the repository, creating a trackable history of the experiment iterations.
While it’s not fully automated, it does bring some of its benefits. For example, the system will automatically follow the naming conventions you implement. This reduces the risk of human error when you log metrics or other data.
It’s also much easier to revert to older versions without having to create, organize, and find copies manually. They have the built-in ability to branch and run parallel workflows.
These systems also have built-in collaboration, making it easy for team members to track changes and stay in sync. Plus, it’s relatively technology-agnostic, so you can use it across projects or frameworks.
However, not all these systems are optimized for large binary files. This is especially true for ML models where huge data sets containing model weights and other metadata are common. They also have limited features for visualizing and comparing experiments, not to mention live monitoring.
This approach is highly useful for projects that require a detailed history of changes. Also, many developers are familiar with deep learning platforms like Git, so adoption should be seamless for most teams. However, it still lacks some of the advanced capabilities on offer with dedicated MLOps or experiment tracking software.

Using Modern Experiment Tracking Tools
There are specialized software solutions designed to systematically record, organize, and compare data from machine learning experiments. Designed specifically for ML projects, they typically offer seamless integration with common models and frameworks.
On top of tools to track and store data, they also offer a user interface for viewing and analyzing results. This includes the ability to visualize data and create custom reports. Developers can also typically leverage APIs for logging data to various systems and compare different runs. Plus, they can monitor the experiment’s progress in real time.
Built for ML models, they excel at tracking hyperparameters, evaluation metrics, model weights, and outputs. Their functionalities are well-suited to typical ML tasks.
Common experiment tracking tools include:
- MLFlow
- CometML
- Neptune
- TensorBoard
- Weights & Biases
The Viso Suite platform also offers robust experiment tracking through its model evaluation tools. You can gain comprehensive insights into the performance of your computer vision experiments. Its range of functionalities includes regression, classification, detection analyses, semantic, and instance segmentation etc.
You can use this information to identify anomalies, mine hard samples, and detect incorrect prediction patterns. Interactive plots and label rendering on images facilitate data understanding, augmenting your MLOps decision-making.
What’s Next With Experiment Tracking?
Experiment tracking is a key component of ML model development, allowing for the recording and analysis of metadata for each iteration. Integration with comprehensive MLOps practices enhances model lifecycle management and operational efficiency, meaning that organizations can drive continuous improvement and innovation in their ML initiatives.
As experiment tracking tools and methodologies evolve, we can expect to see the model development process change and improve as well.