
NVIDIA in 2018 came out with a breakthrough Model- StyleGAN, which amazed the world for its ability to generate ultra-realistic and high-quality images. Before StyleGAN, NVIDIA did come up with the predecessor- ProGAN, however, this model could not fine-control the features of images generated.
StyleGAN is a state-of-the-art GAN (Generative Adversarial Network), a type of Deep Learning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014. Since the development of GANs, the world saw several models introduced every year that got nearer to generating real images. However, none of them were able to generate images while controlling their output, StyleGAN was the first to introduce this feature.
Since their development, GANs have been a powerful tool for various applications, for eg, they enable Style Transfer, generate images of people that are not real, and generate training data to train DL models, cars, rooms, and a lot more.

About us: Viso Suite infrastructure allows enterprises to build, deploy, manage, and scale real-world applications. Book a demo with our team of experts to see how Viso Suite can solve your business challenges.
Brief Introduction to GANs (Generative Adversarial Networks)
GANs are made of two neural networks:
- A generator that creates new data
- A discriminator evaluates whether the generated data is real or fake.
These two networks compete against each other in a zero-sum game. The generator’s task is to create fake data that mimics real data, while the discriminator’s task is to distinguish between real and fake data. This goes on until the generator can produce data that is almost indistinguishable from real images.
This simple principle of adversarial networks allows GANs to generate highly realistic synthetic data, such as images, videos, and audio.
History and Evolution Leading Up to StyleGAN
The original GAN framework proposed by Goodfellow faced challenges:
- It faced instability during training,
- It could only generate images of very low resolution (16 x 16), which is quite low not near the standard resolution of 1920 x 1080.

ProGAN (Progressive Growing GAN)
ProGAN introduced by NVIDIA researchers in 2017 was the first model that was capable of generating resolution up to 1024×1024, and this shocked the world. This model was capable of improving the previous limitation of GAN with the help of the key concept of progressive growth.
In ProGAN progressive growth works by starting both the generator and discriminator start with low-resolution images (such as 4×4) and gradually increasing the resolution in the later layers as training progresses.
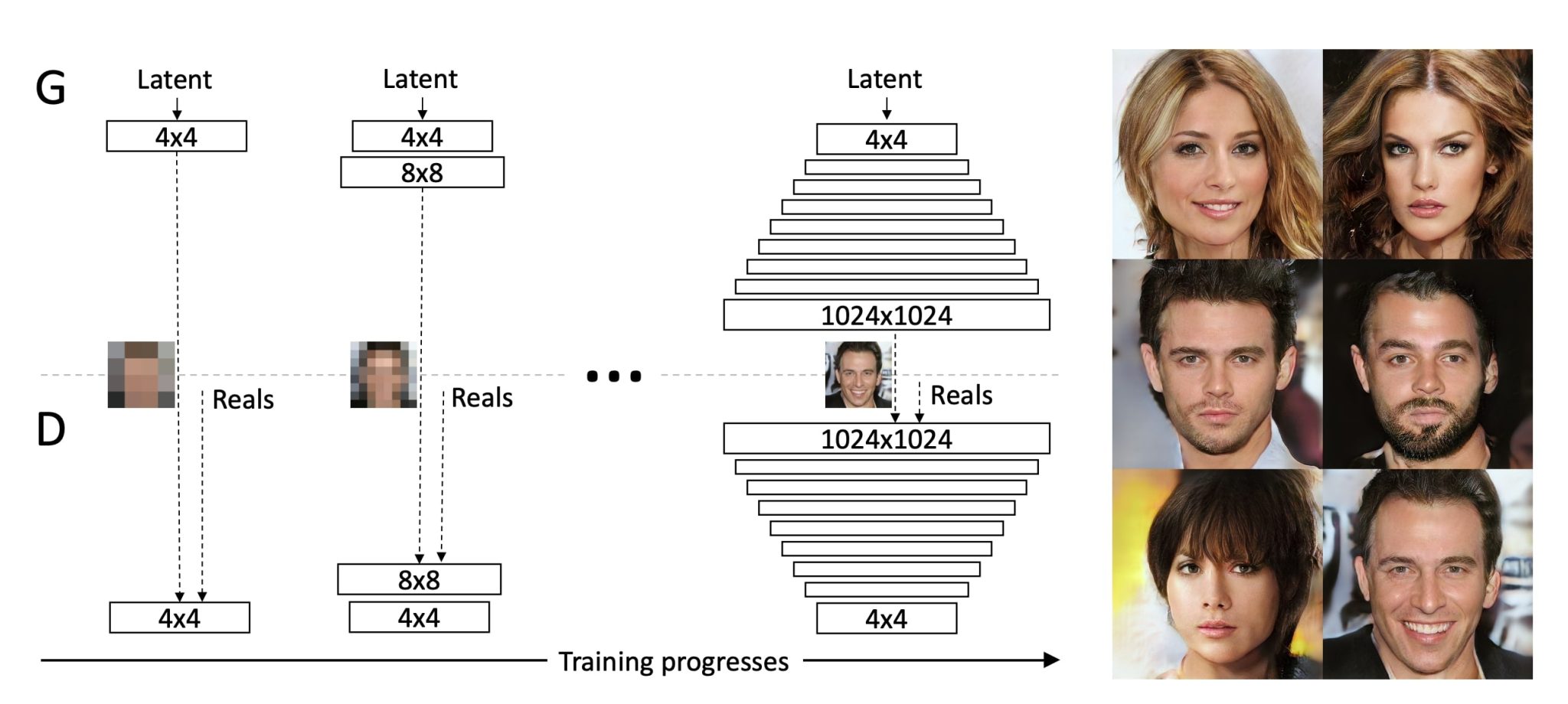
This approach had benefits:
- It stabilized the training process.
- Allowed the model to learn core features and build over them, this technique broke down the problem into parts, resulting in the capability of generating high-resolution images.
Motivation for Developing Style Generative Adversarial Network
However, ProGAN presented another challenge. Despite the high resolution; there was no control over the features of generated images. NVIDIA again came up with a unique solution that allowed it to control the features of generated images.
Key Innovations in StyleGAN
The three key innovations in StyleGAN are:
- The style-based generator GAN architecture,
- Progressive growth,
- And noise injection.
We will look at each of them in detail.
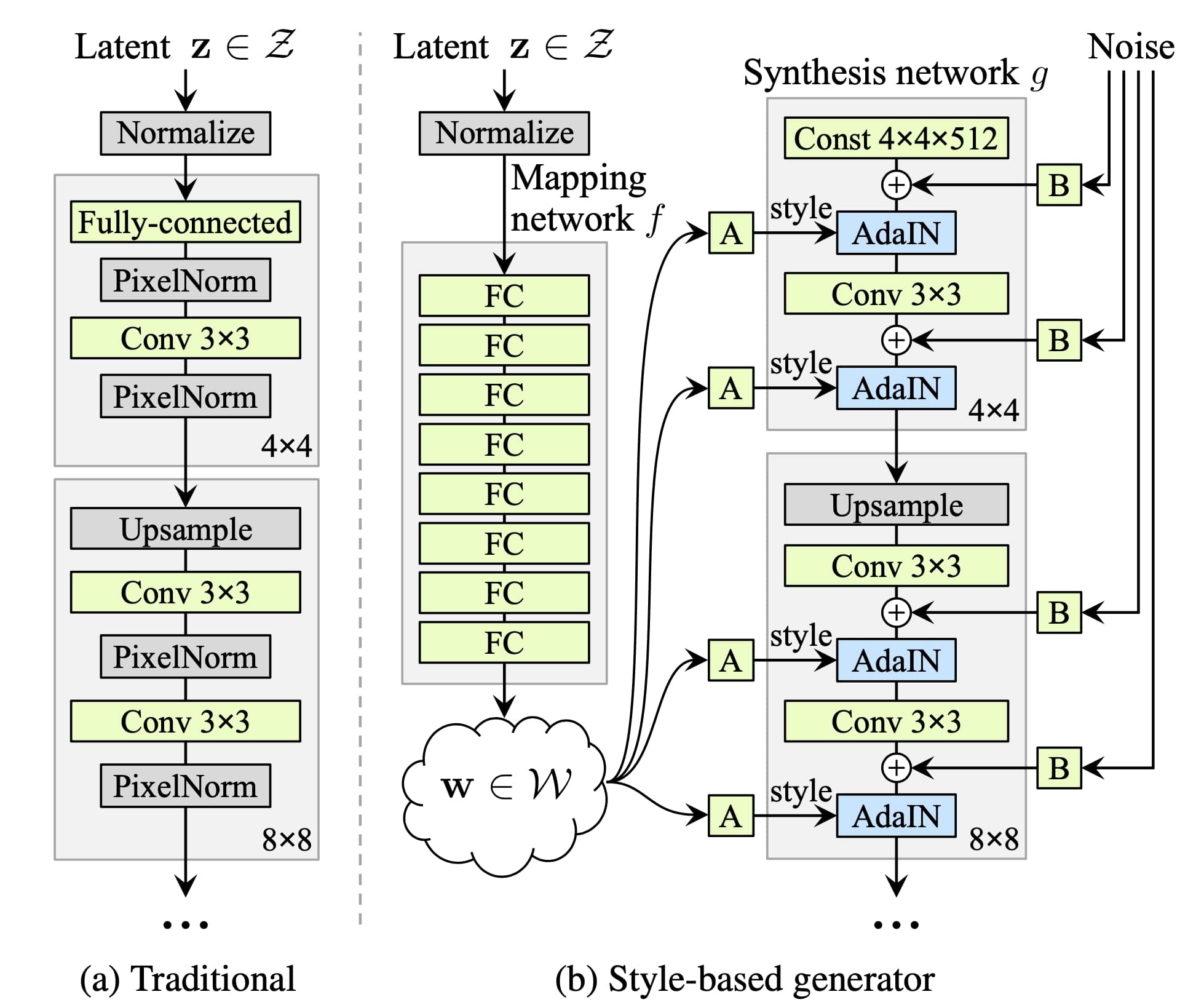
StyleGAN Generator Architecture

The StyleBased architecture in StyleGAN works as follows:
- GANs generate images from a single latent vector.
- However, StyleGAN uses a mapping network to transform the latent vector into an intermediate vector
- This latent vector controls the generator through Adaptive Instance Normalization (AdaIN) layers.
This architecture allows for fine-grained control over different aspects of the image, such as facial features, textures, and colors.
Progressive Growing
Progressive growing was first introduced in ProGAN. StyleGAN also employs the progressive growing technique.
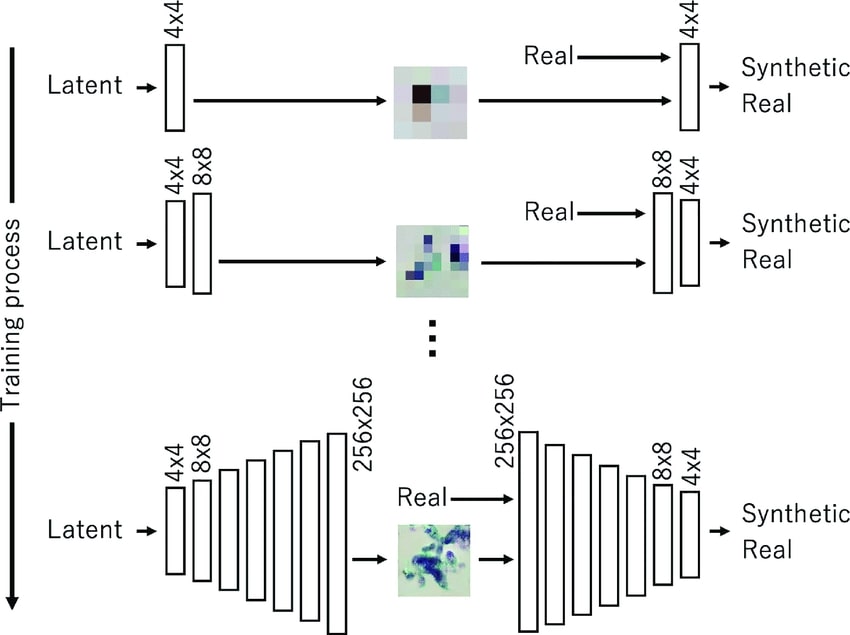
In this technique, the generator and discriminator start with low-resolution images and gradually increase the resolution during training. This allows the networks to focus on coarse structures first, and then refine the details. Here is a detailed breakdown of how it works:
- Start with Low Resolution: The generator produces low-resolution images (e.g., 4×4 pixels) first, which the discriminator checks whether is fake or not.
- Incremental Resolution Increase: Once the learning has stabilized, the resolution of the images is doubled (e.g., from 8×8 pixels to 16×16 pixels), and new layers are added to both the generator and discriminator to handle the increased resolution.
- Smooth Transition: During each resolution transition, there is a blending period that ensures a smooth adaptation of the model, this is done by gradually mixing the output of the new high-resolution layers with the existing lower-resolution layers.
- Full Resolution: The same process is repeated multiple times, and continues until the desired final resolution is reached (e.g., if you want 1024×1024 pixels).
This is called progressive and what allowed GANs to output high-resolution images.
Moreover, progressive growth had other benefits. It stabilized the training, as the original big problem was broken down into parts, and now the network learns the coarse structure’s features first and then focuses on the finer details. This eventually reduced the very common problem of GANs, the risk of mode collapse (when the generator model produces a limited set of outputs that fail to capture the full diversity of the real data distribution).
This process improved the image quality and resolution.
Noise Injection
Noise injection was first introduced in StyleGAN. This is a process in which random noise is added at multiple layers of the generator, this introduces stochastic variation into the generated images. These random values (or noise) influence the features of the generated images and add variability and complexity to the final output.
- This introduction of random noise at different layers results in fine details and subtle variations in the generated images. This makes the images look more natural and diverse. The natural world is full of subtle variations and imperfections, and adding noise replicates this process.
For example, introducing slight variations and imperfections in lighting, texture, and other fine details contributes to the overall authenticity of the images. Making each image unique.

This process has another benefit apart from creating a unique image, as it also helps reduce overfitting. The noise forces the model to generate unique examples and stops the model from generating the same image again and again. The noise vectors are sampled from a Gaussian distribution, this is what allows us to control the image generation process, as we can influence what kind of noise needs to be injected.
StyleGAN Architecture
As we discussed above, the architecture of StyleGAN consists of two components, a generator and a discriminator.
Generator
The generator has the following parts:
- Mapping Network: This network transforms a simple latent vector Z into an intermediate latent vector W. This intermediate vector is then used to control the generator through the style vectors.
- Adaptive Instance Normalization (AdaIN) Layers: AdaIN helps with applying style vectors to the generator at different levels. Each AdaIN layer normalizes the feature maps and scales them based on the style vector, ensuring that different styles can be applied to different layers.
- Synthesis Network: This is the network that uses the style vectors to generate the final image. The synthesis network is composed of convolutional layers that progressively refine the image from a low resolution to the final high resolution.
Discriminator
The discriminator in StyleGAN is a standard Convolutional Neural Network (CNN) designed to distinguish between real and generated images.
Components of the Generator
Latent Space and Mapping Network
The latent space is a high-dimensional vector space where each point represents a potential image. During inception, a random vector Z is sampled from a standard normal distribution, then this vector serves as the starting point for the image generation process.
However, unlike standard GANs which use latent vectors directly, StyleGAN introduces a mapping network to transform z into an intermediate latent space w. This helps with controlling the output of the generator.
Transforming the Latent Vectors into Style Vectors (W)
The mapping network in StyleGAN consists of several fully connected layers that transform the latent vector Z into a style vector W.
This transformation helps to disentangle the latent space, making it easier to manipulate and control specific features of the generated images.
- In a highly entangled latent space, different factors of variation (e.g., facial expression, lighting, background) are not separated. Changing one dimension of the latent vector might affect multiple aspects of the generated image simultaneously. This makes it difficult to control specific attributes of the generated data. For example, adjusting the latent vector to change the hairstyle might also unintentionally change the face shape or background.
- Disentanglement is achieved when the latent space is structured such that each dimension (or a small subset of dimensions) corresponds to a distinct and independent feature of the generated data. As a result of this, In a disentangled latent space, changing one component of the latent vector affects only the specific aspect of the generated image associated with that component, without altering other features.
The fully connected mapping network learns this process of disentanglement. The resulting style vector W is then used to modulate the generator network through adaptive instance normalization (AdaIN) layers.
Adaptive Instance Normalization (AdaIN)
AdaIN helps you control the overall style and specific details of the generated images. This is performed by applying style vector W at different stages of generation rather than giving the style vector at the start. This process helps in the following ways:
- At first, in the early layers, the generator focuses on low-resolution images, which shape broad features like pose, general shape, and layout. Here the AdaIN layers normalize the feature map.
- When the resolution increases in the later layers, daIN modifies the vector W according to the style vector provided, which helps with crafting the finer details such as textures, colors, and patterns.
Synthesis Network
The synthesis network is the network that generates images. It consists of a series of convolutional layers that progressively refine the image from a low resolution to the final high resolution.
Each layer of the synthesis network corresponds to a different resolution level, StyleGAN starts from 4×4 pixels and doubles in size until reaching the desired output resolution (e.g., 1024×1024 pixels).
The synthesis network takes various styles and injects them at various levels using the AdaIN layers.

Noise Injection and Stochastic Variation
Role of Noise Injection in Adding Fine Details
Noise injection is a crucial technique in StyleGAN that contributes to the generation of highly detailed and realistic images. In StyleGAN, noise is added at multiple layers of the generator network. This noise is typically Gaussian and serves as a source of random variation that the generator uses to create fine details.

- Adding Texture and Details: The injected noise provides a source of randomness that can be used to generate intricate textures and fine details in the images. This is particularly important for creating realistic hair strands, skin textures, and other micro-details that enhance the overall realism of the generated images.
- Preventing Overfitting: By introducing random noise, the generator is encouraged to produce a variety of outputs rather than overfitting specific patterns in the training data. This helps in generating a wider range of realistic images.
What did we learn about StyleGAN?
In this blog, we looked into the architecture of StyleGAN, focusing on its innovative components and advancements. We started by introducing architecture for Generative Adversarial Networks (GANs) and their role in generating synthetic images and data, emphasizing their significance in AI and image generation. Then, we discussed the evolution of GANs leading up to the development of StyleGAN. We also saw key milestones such as the original GANs and ProGAN architecture for Generative Adversarial Networks.
We then explored the style-based generator architecture, progressive growing technique, noise injection, and their roles in enhancing image quality and control. And how the mapping network transforms latent vectors, the role of Adaptive Instance Normalization (AdaIN), and the structure of the synthesis network in generating detailed and realistic images. We then looked at key terms such as progressive growing, and noise injection from stochastic variation.
If you enjoyed reading this article, we recommend reading the below:
- NVIDIA Beats Microsoft: The World’s Most Valuable Company
- Generative AI: A Guide To Generative Models
- AlphaPose: A Comprehensive Guide to Pose Estimation
- Smart Hospitality: Computer Vision for Hotels and Casinos
- Artificial Super Intelligence: Exploring the Frontier of AI
