
ImageNet is a large-scale image database containing a vast amount of controlled and human-annotated images. This database has undoubtedly played a great impact in advancing computer vision software research.
One of the crucial tasks in today’s AI is image classification. It is a technique used in computer vision to identify and categorize the main content (objects) in a photo or video. Image classification employs AI-based deep learning models to analyze images and perform object recognition, as well as a human operator. Examples of image classification include:
- Analyzing photo(s) to determine if they include general objects like cars, people, and animals.
- Specialized applications in medicine to examine scans for diseases, i.e., diagnoses by CT scans, MRI, etc.
- Identification of cars, trucks, pedestrians, and road traffic signs in autonomous vehicles.
The Need for Image Training Datasets
To train the image classification algorithms, we need image datasets. These datasets contain multiple images similar to those that the algorithm will run in real life. Unsupervised models are usually trained with unlabeled datasets, while supervised use labeled image datasets to train and test them. The labels provide the knowledge that the algorithm can learn from.
Image datasets are often used to train image classification models. At the start – the dataset is split into training and testing sets. E.g., 70% of the images compose the training set, and the rest 30% are used as the testing set – unseen examples to test the algorithm’s performance.
The other usage of image datasets is as a benchmark in computer vision algorithms. Applying different algorithms over the same dataset is an effective way to check their performance for a given task.
What is ImageNet?
ImageNet is a publicly available large-scale database with annotated images, composed to be used in multiple computer vision tasks. It contains over 14 million images, with each image annotated using WordNet synonym sets. It is one of the largest resources available for training deep learning models in image recognition tasks. ImageNet’s images are not its property – it only provides URLs and thumbnails of the images.

ImageNet Dataset Details
- Over 14 million images in high resolution.
- Around 22000 WordNet synonym sets (also known as synsets). A synset is a phrase that describes a meaningful concept in WordNet and ImageNet.
- Over one million annotated images with bounding boxes.
- 10,000+ synsets with scale-invariant feature transform (SIFT) features.
- Over 1.2 million images with SIFT features.
ImageNet Development Timeline
2006 – AI scientist Fei-Fei Li starts the ImageNet project. Most AI researchers are focused on AI algorithms, and Li wanted to enlarge and improve the image database for training computer vision models.
2007 – Li discusses the idea with Professor Christiane Fellbaum, creator of WordNet, and starts to build ImageNet from WordNet’s word database by using some of its features.
2008 – Li, with a team of Princeton colleagues, works on the ImageNet; remote co-workers help classify images.
2009 – The ImageNet database is first presented at the Conference on Computer Vision and Pattern Recognition (CVPR) in Florida.
2010 – Fast progress in image processing. The annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is a platform that allows researchers to evaluate their algorithms and models. It brings the development of deep learning models for image classification, object detection, and other computer vision tasks. The first ILSVRC, a subset of ImageNet, used a set of only 1000 image categories (classes) and was able to classify 90 of the 120 dog breeds.
2011 – A good ILSVRC image classification error rate is 25%.
2012 – A deep convolutional neural net called AlexNet achieves a 16% error rate.
2013 – Breakthrough improvement in CV (computer vision), top performers are below a 5% error rate. This marks the start of an industry-wide artificial intelligence boom.
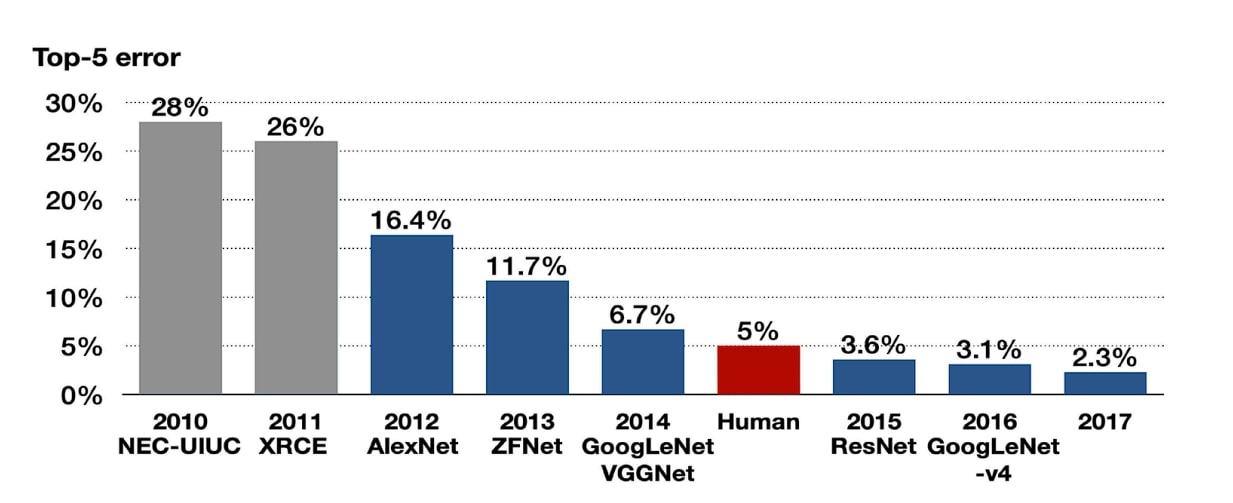
2015 – Microsoft researchers report that their Convolutional Neural Networks (CNNs) exceed human ability in pure ILSVRC tasks.
2017 – Giant leap in image classification capability, over 95% accuracy in computer vision tasks is achieved.
ImageNet Dataset Features
The ImageNet is an annotated image dataset based on the WordNet hierarchy. The hierarchy is composed of nodes that define the categories. Each category is described by a synset (a set of meaningful phrases).
Each image in ImageNet is annotated with one or several synsets, providing information for training algorithms. Thus, the models will be trained to recognize various objects and their relationships.
The ImageNet Challenge (ILSVRC) mentioned above has used this dataset since 2010 as a benchmark for image classification.The ImageNet dataset contains an annotated training set and an unannotated testing set. There are two types of image annotations in ImageNet:
- Image-level annotations assign binary labels to denote the presence or absence of a given object class within the image. For example, “there are dogs in this image” or “there are no cats.”
- Object-level annotations provide tight bounding boxes and class labels around object instances in an image. For example, “there is a dog at the coordinate (30,45) with a width of 150 pixels and height of 80 pixels.”

The Usage and Applications of ImageNet
Today the ImageNet dataset is used for training and testing of machine learning models in various CV tasks: image classification, object detection, and object localization. Popular deep learning architectures, such as ResNet, AlexNet, and VGG have been developed and benchmarked using the ImageNet dataset. You’ll need only a few lines of Python code to train a deep learning model on the ImageNet dataset.
The ImageNet dataset contains high-resolution images belonging to thousands of object categories, providing a diverse and extensive dataset for the training and evaluation of CV models.
ImageNet is also used for benchmarking and evaluation of computer vision tasks, particularly for image classification and object detection tasks. Some recent research in these areas performed by utilizing ImageNet include:
- Image Classification – NoisyNN: Exploring the Influence of Information Entropy Change in Learning Systems, published by Xiaowei Yu et al. (2023). They achieved over 95% accuracy by using pre-trained ImageNet (21K) with 86M parameters.
- Object Detection and Instance Segmentation – DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network, published by Xuan Shen et al., CVPR 2023. They applied deep CNN over pre-trained ImageNet-1K, with 24.2M parameters, achieving an accuracy of around 84%.
- Self-supervised Image Classification – DINOv2: Learning Robust Visual Features without Supervision, published by Maxime Oquab et al. (2023). They applied ViT-Large architecture on ImageNet-22k with 1.1B parameters and achieved 84.5% accuracy.
ImageNet Classification with Deep Convolutional Neural Networks
The object recognition task is quite a complex task, so the problem can’t be specified even by a large dataset such as ImageNet. The model should possess prior knowledge to compensate for the missing data, and CNNs are a class of such models. By changing their depth and breadth, we determine their capacity. CNNs also give quite accurate assumptions about the nature of images (i.e., stationarity of statistics and locality of pixel dependencies).
Compared to standard feed-forward neural networks with a similar number of layers, CNNs have fewer connections and parameters so they are easier to train. Their theoretically best performance is also superior to regular neural networks.
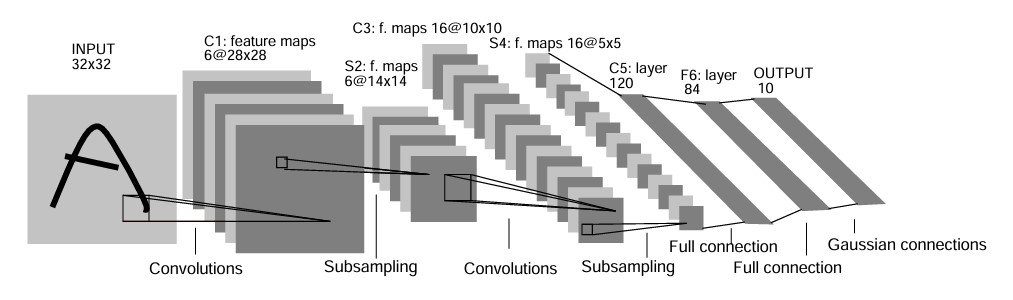
AlexNet at the ImageNet Competition 2012
Alex Krizhevsky and his team (AlexNet) won the ImageNet Challenge in 2012 by conducting the research “ImageNet Classification with Deep Convolutional Neural Networks”. This research brought up significant contributions: they trained one of the largest CNNs at that moment over the ImageNet dataset used in the ILSVRC-2010 / 2012 challenges and achieved the best results reported on these datasets.
The team implemented a highly optimized GPU of 2D convolution including all required steps in CNN training, and published the results. Their CNN contained several new and unusual features which improved its performance and reduced its training time.
The size of their network caused overfitting (even with 1.2 million labeled training examples), so they applied several techniques to prevent it. Their final CNN contained five convolutional and three fully connected layers, and the depth was quite important. They found that removing any convolutional layer (each of which contained no more than 1% of the model’s parameters) resulted in inferior performance.
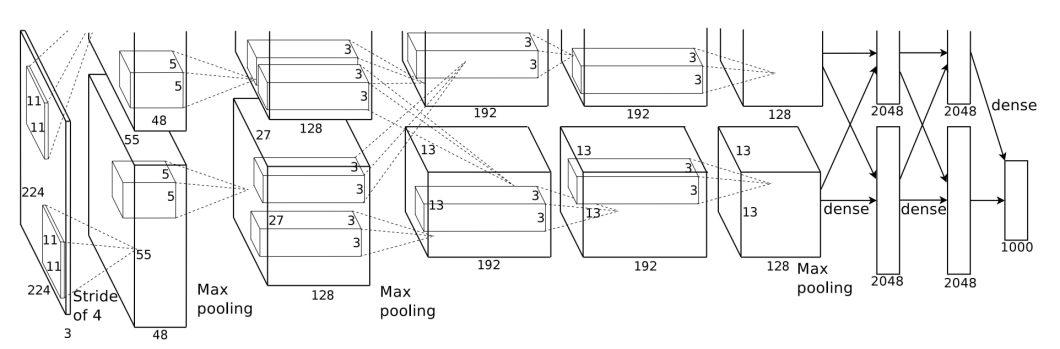
AlexNet Structure
The overall architecture of their CNN is displayed in the figure below – the net contains eight layers with weights; the first five are convolutional and the remaining three are fully connected. The output of the last fully connected layer is fed to a 1000-way softmax, which produces a distribution over the 1000 class labels. This CNN maximized the multinomial logistic regression objective, i.e. it maximized the average across training cases to assign a correct label.
The team reported their results on the Fall 2009 version of ImageNet with 10,184 categories and 8.9 million images. From that dataset, they used half of the images for training and half for testing.
At the time, there wasn’t an established test set and the random split affected the results only slightly. They achieved top-1 and top-5 error rates on that dataset – 67.4% and 40.9%, attained by CNN above, with an additional, 6-th convolutional layer over the last pooling layer. Their best-achieved results on that dataset were 78.1% and 60.9%.
The same CNN, with an extra sixth convolutional layer, was used to classify the entire ImageNet Fall 2011 release (15M images, 22K categories). After fine-tuning on ImageNet-2012 ,it gave an error rate of 16.6%. The second-best contest entry achieved an error rate of 26.2% with an approach that averages the predictions of several classifiers trained on Fisher vectors.

The Future of ImageNet
During its existence, ImageNet has expanded to include millions of images across thousands of categories, driving innovation and setting new standards in the field. The ImageNet data is available for free to researchers for non-commercial use.
Since its beginning, ImageNet has provided researchers with a common set of images to benchmark their models and algorithms. Thus, it has driven research in machine learning and deep neural networks, making it easier to classify images and complete other computer vision tasks.
ImageNet has impacted computer vision research, from early approaches to deep learning architectures, and continues to shape image understanding and classification tasks in contemporary AI research and applications.
To further understand the concepts in this blog, we recommend checking out the following blogs:
- Machine Vision: What You Need to Know
- Intel Xe GPU Series For Machine Learning: An Overview
- Faster R-CNN: A Beginner’s to Advanced Guide
- OpenCV: The Complete Guide