PyTorchVideo is a new efficient, flexible, and modular deep learning library for video understanding research. The library was built using PyTorch; it covers a full stack of video understanding tools, and it scales to a variety of applications for video understanding.
The article provides an easy-to-understand overview of PyTorchVideo:
- Video Understanding with Artificial Intelligence
- What is PyTorchVideo?
- Key characteristics of PyTorchVideo
- What can PyTorchVideo be used for?
The Need for Video Understanding With AI
Recording, saving, storing, and watching videos have become a regular part of our everyday lives. As the Internet of Things (IoT) expands with sensors and connected cameras, the global data volume is going to explode.
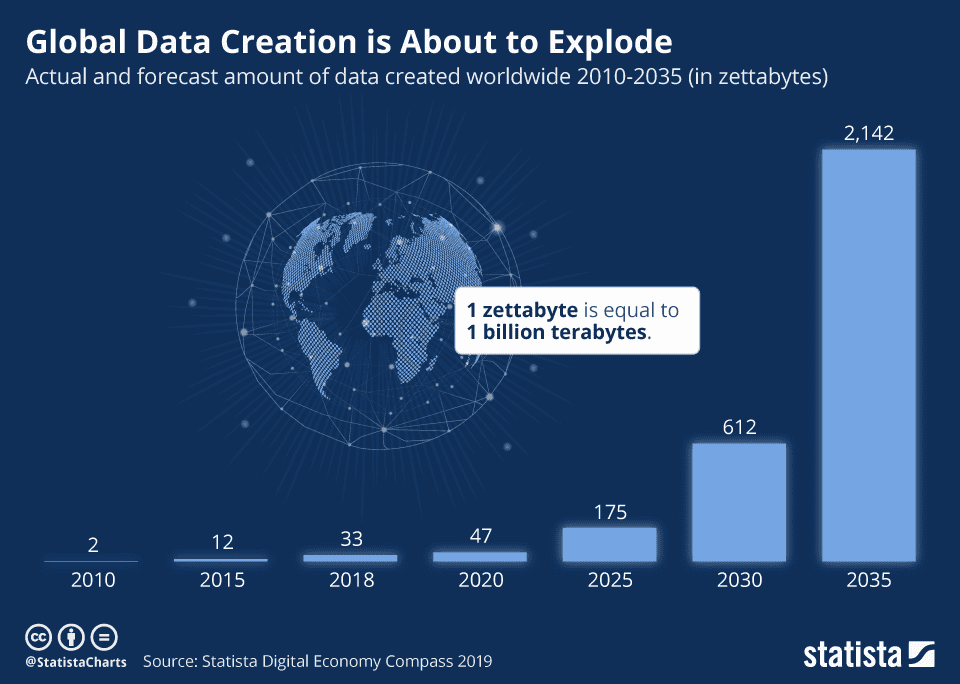
With this immense amount of video data, it is now more important than ever to build machine learning and deep learning frameworks for video understanding with computer vision.
New artificial intelligence technology provides ways to analyze visual data effectively and develop new, intelligent applications and smart vision systems. Use cases include video surveillance, smart city, sports and fitness, or smart manufacturing applications.


With the growing popularity of deep learning, researchers have made considerable progress in video understanding through advanced data augmentation, revolutionary neural network architectures, AI model acceleration, and better training methods. In any case, the amount of data that video produces makes video understanding a big challenge, which is why effective solutions are non-trivial to execute.
Until now, several well-known video understanding developer libraries have been released, which offer the implementation of established video processing models, such as Gluon-CV, PySlowFast, MMAction2, and MMAction. But unlike other modularized libraries that can be imported into various projects, these libraries are built around a training workflow, which restricts their adoption beyond use cases tailored to one particular codebase.
This is why researchers developed a modular, feature-focused video understanding framework to overcome the main limitations the AI video research community faces.

What is PyTorchVideo?
PyTorchVideo is an open-source deep learning library developed by Facebook AI and initially released in 2021. It provides developers a set of modular, efficient, and reproducible components for various video understanding tasks, including object detection, scene classification, and self-supervised learning.
The library is distributed with the open-source Apache 2.0 License and is available on GitHub. The official documentation can be found on the PyTorch Video website.
The PyTorch Video machine learning library provides the following benefits:
- Real-time video classification through on-device, hardware-accelerated support
- A modular design with an extendable developer interface for video modeling using Python
- Reproducible datasets and pre-trained video models are supported and benchmarked in a detailed model zoo
- Full-stack video understanding ML features from established datasets to state-of-the-art AI models
- Several input modalities, such as IMU, visual, optical flow, and audio data
- Vision tasks, including self-supervised learning (SSL), low-level vision tasks, and human classification or detection
The Key Characteristics of PyTorchVideo
The PyTorchVideo library is based on the three main principles of modularity, compatibility, and customizability.
Modularity
PyTorchVideo is meant to be feature-focused: It provides singular plug-and-play features capable of mix-and-match in any use case. This could be achieved by structuring models, data transformations, and datasets separately, only applying consistency through common argument naming guidelines.
For example, in the pytorchvideo.data module, all the datasets offer a data_path argument. Or, in the case of the PyTorchVideo.models module, the name dim_in is used for input dimensions. This kind of duck-typing offers flexibility and high extensibility for new applications.
Compatibility
The PyTorchVideo library has been built in a way that it can be used with other libraries and domain-specific frameworks. Compared to the existing video frameworks, this particular library does not depend on a configuration system. PyTorchVideo uses keyword arguments as a “naive configuration system” to enhance its compatibility with Python-specific libraries with arbitrary configuration systems.
On the other hand, this library supports interoperability with other standard domain-specific frameworks by fixing canonical modality-based tensor types (video, audio, spectrograms, etc.).
Customizability
One of the fundamental use cases of this library is that it supports the most recent research approaches. This way, researchers and scientists can easily contribute their work without architecture modifications or refactoring. Therefore, the creators of PyTorchVideo designed the library to reduce the overhead of adding new components or sub-modules.
This library has a composable interface consisting of injectable skeleton classes. This is combined with an interface that builds reproducible implementations through composable classes. As a result, researchers can simply plug in new sub-components into the structure of larger models such as ResNet.
Core Features of PyTorchVideo: In a Nutshell
The PyTorchVideo developer library currently provides features that can be used for a myriad of video-understanding applications. The library contains reusable implementations of popular models for video classification, event detection, optical flow, human action localization in video, and self-supervised learning algorithms.
The PyTorchVideo library provides an environment (accelerator) for the hardware deployment of models for fast inference on edge devices, a concept known as Edge AI. With different features, the PyTorchVideo Accelerator provides a complete environment for hardware-aware model design and deployment optimized for fast inference.
Facebook AI’s PyTorchVideo has a lot of potential in the video understanding domain. Some of the core features include:
- Access to a range of toolkits and standard scripts for video processing, including but not limited to optimal flow extracting, tracking, and decrypting.
- Researchers can develop new video architectures through video models and pre-trained weights with tailored features.
- Optimized, hardware-aware model design and high-speed on-device model deployment are achieved through effective building blocks.
- Support of multiple downstream tasks such as self-supervised learning (SSL), action classification, acoustic event detection, and action detection.
- Compatibility with many datasets and tasks for benchmarking different video models is possible using different evaluation protocols.
Examples and Use Cases of Video Understanding with AI
In the following, we highlight some of the most important use cases of video understanding with AI, ranging from object detection and face recognition to emotion and sentiment analysis, and video summarization.
- Surveillance and security: AI-powered video analysis can be used to monitor public spaces, detect security threats, and alert authorities in real time. Explore applications in security and surveillance.
- Marketing and advertising: AI can analyze consumer behavior, preferences, and emotions from video data to help companies tailor their marketing strategies and improve customer engagement.
- Healthcare: AI algorithms can help medical professionals diagnose and treat patients by analyzing videos of physical exams, surgeries, and other procedures. Read about computer vision in Healthcare.
- Automated video editing: AI models can be used to automatically edit videos by identifying the most interesting and relevant content, cutting out boring or redundant scenes, and compellingly organizing the footage.
- Sports analysis: AI can be used to analyze player performance, tactics, and game strategies in real time, providing valuable insights to coaches and teams. Read more about computer vision in Sports.
- Video content classification: AI algorithms can automatically categorize videos based on their content, such as sports, music, news, and entertainment.
The Bottom Line
Video-based machine learning (ML) models are becoming increasingly popular. PyTorchVideo provides a flexible and modular deep learning library for video understanding that scales to various research and production AI video analysis applications.
Hence, this new library offers a higher level of easy code bases that speed up the development rate and analysis of computer vision with video image models.
Explore more articles about related topics: