
Autonomous underwater vehicles (AUVs) are unmanned underwater robots controlled by an operator or pre-programmed to explore different waters autonomously. These robots are usually equipped with cameras, sonars, and depth sensors, allowing them to autonomously navigate and collect valuable data in challenging underwater environments. Unlike remotely operated vehicles (ROVs), AUVs do not require continuous input from operators, and with the development of AI, those vehicles are more capable than ever. AI has enabled AUVs to navigate complex underwater environments, make intelligent decisions, and perform various tasks with minimal human intervention.
In this article, we’ll delve into AI in AUVs. We’ll explore the key AI technologies that enable them, examine real-world applications, and a hands-on tutorial for obstacle detection.
About us: Viso Suite is the end-to-end platform for building, deploying, and scaling visual AI. It makes it possible for enterprise teams to implement AI solutions like people tracking, defect detection, and intrusion alerting seamlessly into their business processes. To learn more about Viso Suite, book a demo with our team.
AI Technologies for Autonomous Underwater Vehicles (AUVs)
Artificial intelligence (AI) and machine learning (ML) have been transforming various industries including autonomous vehicles. Whether it is self-driving cars or AUVs, AI technologies like computer vision (CV), provide abilities that take those ideas to reality. CV is a field of AI that enables machines to understand through vision. There are multiple ways a machine can “see”, this includes techniques like depth estimation, object detection, recognition, and scene understanding. This section will explore the AI technologies engineers use for autonomous underwater vehicles.
Computer vision (CV)
Computer Vision is one of the main AI applications in AUVs. There are a lot of things to consider with underwater vision, it is a challenging task and there are several factors that can affect this vision. Underwater, objects are less visible because of lower levels of natural illumination because light travels differently underwater. So, high-quality cameras capable of capturing clear images in low-light conditions are a requirement for effective computer vision. Furthermore, the depth level not only affects the vision but also affects the hardware. Deep waters have high pressures and equipment must be able to withstand that.

With these challenges solved AI can start analyzing footage and doing a wide range of tasks. Following are some computer vision tasks autonomous underwater vehicles perform.
- Object Detection
- Image classification
- Underwater Mapping
Most popular underwater object detection models utilize regular models like YOLOv8. Those models are based on convolutional neural networks (CNNs) which are a popular type of artificial neural networks (ANNs) that work great for vision tasks like classification and detection. However, researchers fine-tune those machine learning models and come up with variations that work better for underwater object detection tasks. Some modifications include adding a cross-stage multi-branch (CSMB) module and a large kernel spatial pyramid (LKSP) module.
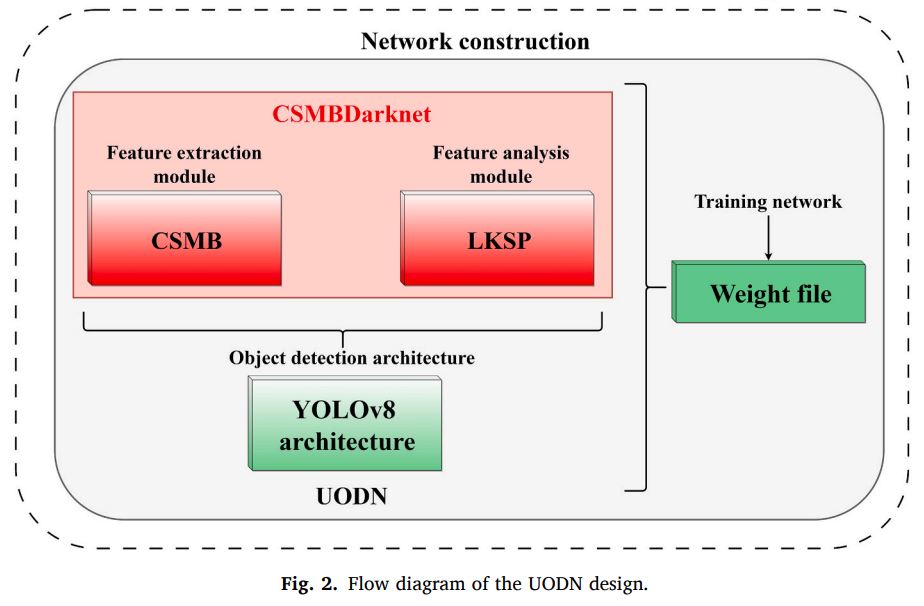
Other tasks include underwater mapping, where autonomous underwater vehicles (AUVs) play a crucial role. AUVs enable the creation of detailed 3D maps of the ocean floor and underwater structures. This process often involves combining computer vision techniques with other sensor data, such as sonar and depth sensors. Depth estimation can be used to generate depth maps, that can be used for 3D reconstruction and mapping.
Navigation and Path Planning
Artificial intelligence becomes particularly useful for tasks like navigation and path planning. The underwater environment, especially at high depths, puts forward various challenges. Those challenges include poor communication making it hard for a ground operator to navigate the waters accurately. Additionally, underwater environments are different, making adaptability a key to navigating correctly. This includes always taking the best path for energy consumption and mission goals. AI enables these capabilities by providing algorithms and techniques that allow AUVs to adapt to dynamic conditions and make intelligent decisions.
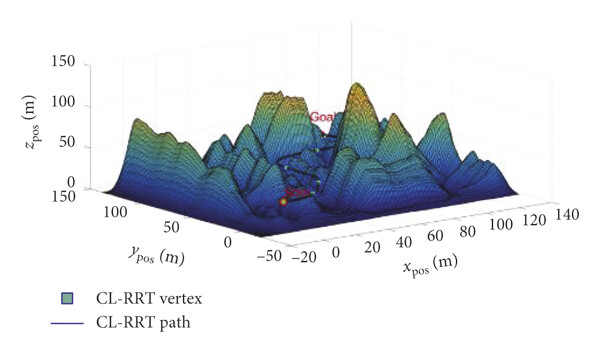
Before an autonomous underwater vehicle can navigate the environment, it needs to understand its surroundings. This is usually done with environment modeling, using techniques like underwater mapping. This model as seen above includes obstacles, currents, and other relevant features of the environment. Once the environment is modeled, the AUV needs to plan a path from its starting point to its destination depending on factors like energy consumption and the mission goal. This requires using a variety of path-learning algorithms to optimize against certain criteria. Following are some of those algorithms.
- A* Search
- Dijkstra’s Algorithm
- Reinforcement Learning
- Neural Networks
- Swarm Intelligence
- Genetic Algorithms
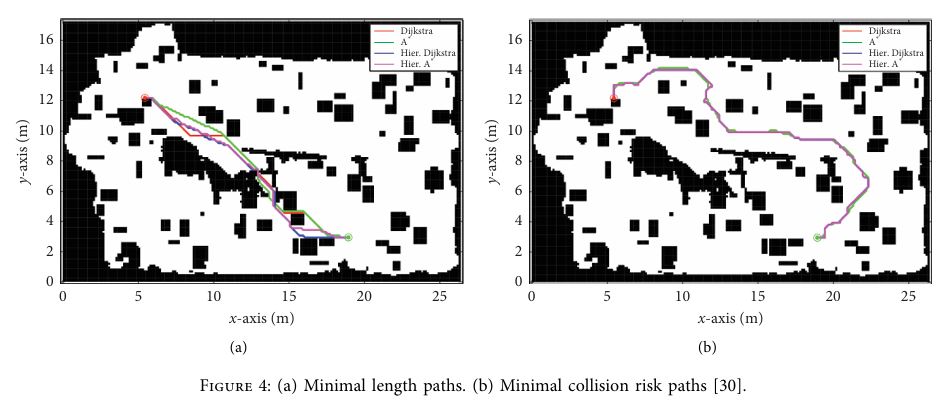
Each algorithm can benefit path planning differently. For example, neural networks are a great way to optimize for adaptability, by learning complex relationships between sensor data and optimal control actions. Swarm intelligence is especially useful for multiple AUVs sharing data for cooperative tasks. Researchers also use more classical algorithms like A* and Dijkstra’s. They work by finding the most optimal path depending on the goal, which is great for environments with well-defined obstacles.
Underwater Mapping
Underwater mapping can be undertaken from different platforms, such as ships, autonomous underwater vehicles, or even low-wing aircraft. The vehicle must be equipped with devices like sonars, sensors, cameras, and more. The data from these devices can then be turned into maps, AI techniques can be used to enhance the map and accelerate its creation in several ways.
- Occupancy Grids
- Depth Estimation
- Oceanographic Data Integration

As seen in the image above, accurate depth maps can be created by using sensor and sonar data. AI algorithms can process this data to update the occupancy grid and provide a representation of the obstacles in the environment. Combined with deep learning techniques like depth estimation and 3D reconstruction, this data can be further used to create detailed maps of the underwater environment. Plus, makes the map highly customizable and adaptable.
For example, researchers might add additional data to the mapping process like current forecasts, water temperatures, and wave speeds and lengths. Underwater mapping is an essential task to understand the environment under the oceans and seas, it can help with path planning, but it can also help with things like tsunami risk assessments. Let’s explore more applications of AUVs in the next section.
Applications of AI-Powered Autonomous Underwater Vehicles
AI-powered AUVs are essential to many applications in the water. This section will explore some of the most impactful ways AI AUVs are being used in industries and underwater research.
Oceanographic Research
AI-powered AUVs are crucial for oceanographic research, they provide a more autonomous and efficient way to collect and analyze vast amounts of data from the ocean. AI can analyze the data from sensors to measure parameters like temperature, salinity, currents, and even the presence of specific marine organisms. The transformation is the ability of modern AI algorithms to analyze and provide insights into this data in real time.
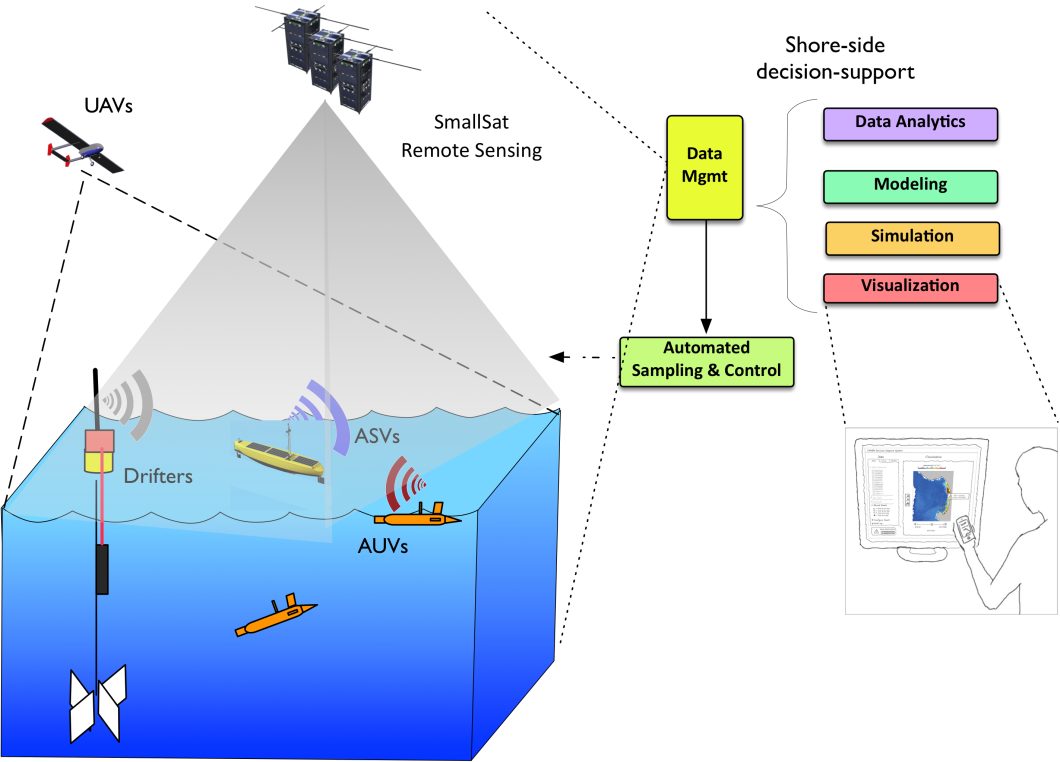
The ocean is a very vast and complex environment, research has only discovered and studied 5% of the oceans. However, current developments in AI are enabling capable underwater autonomous vehicles, that facilitate the discovery and research accelerating it towards the future. Additionally, the AI data analysis helps identify subtle changes in ocean currents, track the movement of schools of fish, or even identify potential sites for underwater geological formations.
Environmental Monitoring
Environmental monitoring is another area where AI-powered AUVs are making a significant impact. Researchers are deploying them to monitor the health of underwater ecosystems, assess pollution levels, or even inspect underwater infrastructure. It could identify signs of coral bleaching, detect the presence of invasive species, or even monitor changes in water quality that might threaten the reef’s health. Engineers can also adapt the vehicle structure, mimicking the biology and physics of fish, making it last more in the environment and adapt to it to gather accurate data.
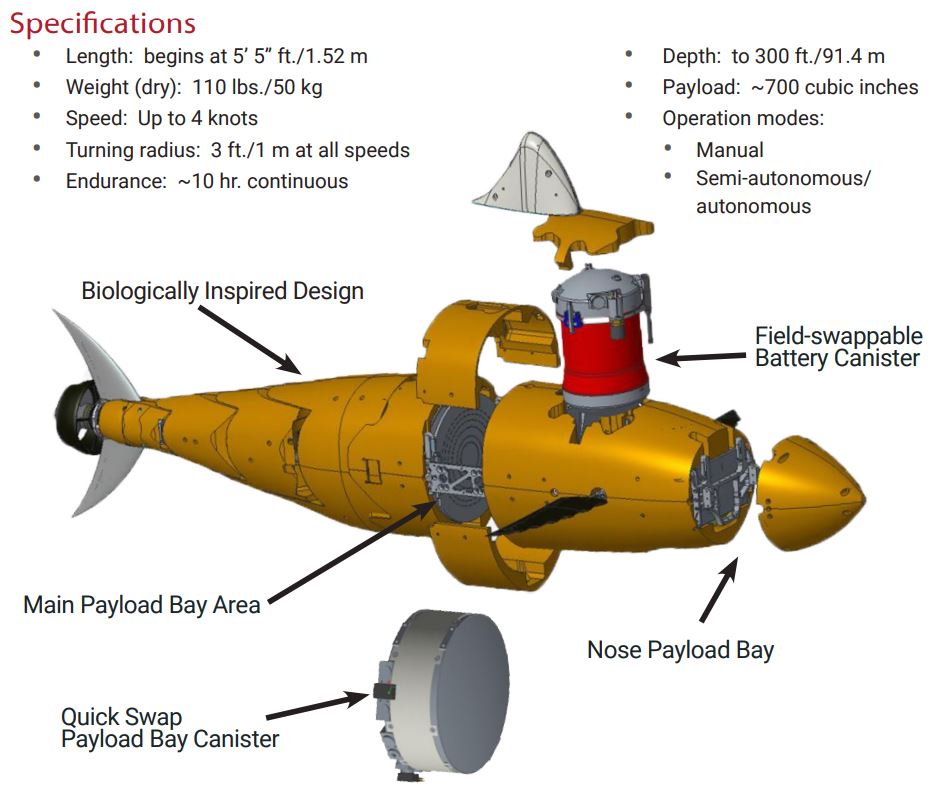
In another scenario, an AI-powered AUV could be used to inspect underwater pipelines or cables, identifying signs of corrosion, damage, or potential leaks. This type of proactive monitoring can help prevent costly repairs or even environmental disasters.
Underwater Archaeology
Underwater archaeology is an interesting field that often involves exploring and documenting shipwrecks, ancient ruins, or other historical sites hidden under the seas. AI-powered AUVs are providing new tools for archaeologists to investigate these sites without disturbing them. Autonomous under water vehicles are also used to create 3D models and structures for those sites. AI algorithms can analyze the data collected from images and sensors to identify potential artifacts or reconstruct the ship back allowing us to create interesting simulations.

Light AUVs are a popular tool archaeologists use to explore and understand historical sites underwater. Those sites are usually fragile and can be hard to navigate, but LAUVs provide a non-invasive approach. This non-invasive approach not only helps preserve delicate underwater sites but also allows for a better and more comprehensive view with techniques like lighting correction.
Those are only a few interesting applications of AUVs in research and engineering, but there are many more. Furthermore, in the next section, we will explore a step-by-step tutorial to build an obstacle detection model.
Hands-on Tutorial: Underwater Object Detection For Autonomous Underwater Vehicles
The autonomous mechanism in AUVs primarily uses reinforcement learning, and computer vision combined with hardware like sensors and cameras. Those vehicles are usually sent on missions, which can include looking for something specific, like inspecting submarines for damages or looking for a particular species in the ocean. Almost any mission goal can use object detection capabilities to increase efficiency. This tutorial will use object detection to look for waste plastic underwater.
Collecting The Data
For this tutorial, we will use Kaggle, Python, and YOLOv5. Kaggle will provide the space to collect data, process it, and train the model. Kaggle also contains a wide collection of datasets to use for autonomous underwater vehicles. However, since our mission object is to detect and find waste we will use one specific dataset here. Our first step is to start the Kaggle notebook and load the specified dataset into it. Then we can import the libraries we need.
import os import yaml import matplotlib.pyplot as plt import matplotlib.patches as patches from PIL import Image
Now let’s look at what kind of objects are included in this dataset. Those are called classes, and we can find them in the “data.yaml” file. The following Python code defines the path, finds the “data.yaml” file, and prints all the classes.
dataset_path = "/kaggle/input/underwater-plastic-pollution-detection/underwater_plastics"
with open(os.path.join(dataset_path, "data.yaml"), 'r') as f:
data = yaml.safe_load(f)
class_list = data['names']
print("Classes in the dataset:", class_list)
This dataset includes the following classes: [‘Mask’, ‘can’, ‘cellphone’, ‘electronics’, ‘gbottle’, ‘glove’, ‘metal’, ‘misc’, ‘net’, ‘pbag’, ‘pbottle’, ‘plastic’, ‘rod’, ‘sunglasses’, ‘tire’], however, we will not need all of them so in the next section we will process it and take the classes we need. But first, let’s look at some samples from this dataset. The following code will show the defined number of samples from the dataset, also showing the annotated bounding boxes.
def visualize_samples(dataset_path, num_samples=10):
with open(os.path.join(dataset_path, "data.yaml"), 'r') as f:
data = yaml.safe_load(f)
class_list = data['names']
image_dir = os.path.join(dataset_path, "train", "images")
label_dir = os.path.join(dataset_path, "train", "labels")
for i in range(num_samples):
image_file = os.listdir(image_dir)[i]
label_file = image_file[:-4] + ".txt"
image_path = os.path.join(image_dir, image_file)
label_path = os.path.join(label_dir, label_file)
img = Image.open(image_path)
fig, ax = plt.subplots(1)
ax.imshow(img)
with open(label_path, 'r') as f:
lines = f.readlines()
for line in lines:
class_id, x_center, y_center, width, height = map(float, line.strip().split())
class_name = class_list[int(class_id)]
x_min = (x_center - width / 2) * img.width
y_min = (y_center - height / 2) * img.height
bbox_width = width * img.width
bbox_height = height * img.height
rect = patches.Rectangle((x_min, y_min), bbox_width, bbox_height, linewidth=1, edgecolor='r', facecolor='none')
ax.add_patch(rect)
ax.text(x_min, y_min, class_name, color='r')
plt.show()
visualize_samples(dataset_path)Following are some samples of classes we are interested in.

As mentioned previously, it is better to take only the needed classes from the dataset, so for the mission goal the following classes seem to be the most relevant: [“can”, “cellphone”, “net”, “pbag”, “pbottle”, ‘Mask’, “tire”]. Next, let’s process this data to extract the classes we need.
Data Processing
In this section, we will take a list of classes from the dataset to use later in training the YOLOv5 model. The mission goal is to detect trash and waste for removal. The dataset we have has many classes but we only want a handful of those. With Python, we can extract the needed classes and organize them in a new folder. For this, I have prepared a simple Python function that will take a dataset and extract the needed classes into a new output folder.
import os
import shutil
import yaml
from pathlib import Path
from tqdm import tqdm
def extract_classes(dataset_path, classes_to_extract, output_dir):
"""
Extracts specified classes from the dataset into a new dataset.
Args:
dataset_path (str): Path to the dataset directory
classes_to_extract (list): List of class names to extract
output_dir (str): Path to the output directory for the new dataset
"""
dataset_path = Path(dataset_path)
output_dir = Path(output_dir)
# Read class names from yaml
try:
with open(dataset_path / "data.yaml", 'r') as f:
data = yaml.safe_load(f)
class_list = data['names']
# Get indices of classes to extract
class_indices = {class_list.index(class_name) for class_name in classes_to_extract
if class_name in class_list}
if not class_indices:
raise ValueError(f"None of the specified classes {classes_to_extract} found in dataset")
except FileNotFoundError:
raise FileNotFoundError(f"Could not find data.yaml in {dataset_path}")
except KeyError:
raise KeyError("data.yaml does not contain 'names' field")
# Create output structure
output_dir.mkdir(parents=True, exist_ok=True)
# Copy data.yaml with only extracted classes
new_data = data.copy()
new_data['names'] = classes_to_extract
with open(output_dir / "data.yaml", 'w') as f:
yaml.dump(new_data, f)
# Process each split
for split in ['train', 'valid', 'test']:
split_dir = dataset_path / split
if not split_dir.exists():
print(f"Warning: {split} directory not found, skipping...")
continue
# Create output directories for this split
out_split = output_dir / split
out_images = out_split / 'images'
out_labels = out_split / 'labels'
out_images.mkdir(parents=True, exist_ok=True)
out_labels.mkdir(parents=True, exist_ok=True)
# Process label files first to identify needed images
label_files = list((split_dir / 'labels').glob('*.txt'))
needed_images = set()
print(f"Processing {split} split...")
for label_path in tqdm(label_files):
keep_file = False
new_lines = []
try:
with open(label_path, 'r') as f:
lines = f.readlines()
for line in lines:
parts = line.strip().split()
if not parts:
continue
class_id = int(parts[0])
if class_id in class_indices:
# Remap class ID to new index
new_class_id = list(class_indices).index(class_id)
new_lines.append(f"{new_class_id} {' '.join(parts[1:])}\n")
keep_file = True
if keep_file:
needed_images.add(label_path.stem)
# Write new label file
with open(out_labels / label_path.name, 'w') as f:
f.writelines(new_lines)
except Exception as e:
print(f"Error processing {label_path}: {str(e)}")
continue
# Copy only the images we need
image_dir = split_dir / 'images'
if not image_dir.exists():
print(f"Warning: images directory not found for {split}")
continue
for img_path in image_dir.glob('*'):
if img_path.stem in needed_images:
try:
shutil.copy2(img_path, out_images / img_path.name)
except Exception as e:
print(f"Error copying {img_path}: {str(e)}")
print("Extraction complete!")
# Print statistics
print("\nDataset statistics:")
for split in ['train', 'valid', 'test']:
if (output_dir / split).exists():
n_images = len(list((output_dir / split / 'images').glob('*')))
print(f"{split}: {n_images} images")Deep learning datasets usually split the data into 3 folders, those are training, testing, and validation, in the code above we go to each of those folders, find the images folder and the labels folder, and extract the images with the labels we want. Now, we can use this code by calling it as follows.
classes_to_extract = ["can", "cellphone", "net", "pbag", "pbottle", 'Mask', "tire"] output_dir = "/kaggle/working/extracted_dataset" extract_classes(dataset_path, classes_to_extract, output_dir)
Now we are ready to use the extracted dataset to train a YOLOv5 model in the next section.
Train Model
We will first start by downloading the YOLOv5 repository and install the needed libraries.
!git clone https://github.com/ultralytics/yolov5 !pip install -r yolov5/requirements.txt
Now we can import the installed libraries.
import os import yaml from pathlib import Path import shutil import torch from PIL import Image from tqdm import tqdm
Lastly, before starting the training script let’s prepare our data to match the model requirements like resizing the images, updating the data configuration file “data.yaml” and defining a few important parameters for the YOLOv5 model.
DATASET_PATH = Path("/kaggle/working/extracted_dataset")
IMG_SIZE = 640
BATCH_SIZE = 16
EPOCHS = 50
# Read original data.yaml
with open(DATASET_PATH / 'data.yaml', 'r') as f:
data = yaml.safe_load(f)
# Create new YAML configuration
train_path = str(DATASET_PATH / 'train')
val_path = str(DATASET_PATH / 'valid')
nc = len(data['names']) # number of classes
names = data['names'] # class names
yaml_content = {
'path': str(DATASET_PATH),
'train': train_path,
'val': val_path,
'nc': nc,
'names': names
}
# Save the YAML file
yaml_path = DATASET_PATH / 'dataset.yaml'
with open(yaml_path, 'w') as f:
yaml.dump(yaml_content, f, sort_keys=False)
print(f"Created dataset config at {yaml_path}")
print(f"Number of classes: {nc}")
print(f"Classes: {names}")Great! Now we can use the train.py script we got by downloading the YOLOv5 repository to train the model. However, this is not training from scratch, as that would need extensive time and resources, we will use a pre-trained checkpoint which is the YOLOv5s (small) this model is efficient and will be practical to install on a trash collection autonomous underwater vehicle. Additionally, we have defined the number of epochs the model will train for. Following is how we would use the defined parameters with the training script.
!python train.py \
--img {IMG_SIZE} \
--batch {BATCH_SIZE} \
--epochs {EPOCHS} \
--data {yaml_path} \
--weights yolov5s.pt \
--workers 4 \
--cacheThis process will take around 30 minutes to complete 50 epochs, this can be reduced but might provide less accurate results. After the training, we can infer our trained model with a few examples online to test the model on images different from what exists in the dataset. The following code loads the trained model.
from ultralytics import YOLO
# Load a model
model = YOLO("/kaggle/working/yolov5/runs/train/exp2/weights/best.pt")Next, Let’s try it out!
results = model("/kaggle/input/test-AUVs_underwater_pollution/image.jpg")
results[0].show()Following are some results.

The Future Of Autonomous Underwater Vehicles
The advancements in AI and AUVs have opened up new possibilities for underwater exploration and research. AI algorithms are enabling AUVs to become more intelligent and capable of operating with greater autonomy. This is particularly important in underwater environments where communication is limited and the ability to adapt to dynamic conditions is crucial. Furthermore, the future of AUVs is promising, with potential applications in various fields.
In oceanographic research, AI-powered AUVs can explore vast and uncharted places, collecting valuable data and providing insights into the mysteries of our oceans. In environmental monitoring, AUVs can play a crucial role in assessing pollution levels, monitoring underwater ecosystems, and protecting marine biodiversity. Moreover, AUVs can be used for underwater infrastructure inspection, such as pipelines, cables, and offshore platforms, ensuring their integrity and preventing potential hazards.
As AI technology continues to advance, we can expect AUVs to become even more sophisticated and capable of performing complex tasks with minimal human intervention. This will not only expand their applications in research and industry but also open up new possibilities for underwater exploration and discovery.
