
Pascal VOC is a renowned dataset and benchmark suite that has significantly contributed to the advancement of computer vision research. It provides standardized image data sets for object class recognition and a common set of tools for accessing the data and evaluating the performance of computer vision models.
What is Pascal VOC?
Pascal VOC (which stands for Pattern Analysis, Statistical Modelling, and Computational Learning Visual Object Classes) is an open-source image dataset for several visual object recognition algorithms.
It was initiated in 2005 as part of the Pascal Visual Object Classes Challenge. This challenge was conducted till 2012, each subsequent year. The VOC dataset consists of realistic images collected from various sources including the internet and personal photographs.
Each image in the datasets is carefully annotated with bounding boxes, segmentation masks, and labels for various object categories. These annotations henceforth serve as ground truth data that enables supervised learning approaches and facilitates the development of advanced computer vision models.

Goals and Motivation Behind Pascal VOC Challenge
The Pascal VOC promotes research and development in the field of visual object classification. Its primary purpose was to provide reference data sets, benchmarks for evaluating performance, and a working platform for the research involving the detection and recognition of objects. The project focused on object classes in realistic scenes; thus, the tested images included cluttered backgrounds, occlusion, and various object orientations.
As a result of Pascal VOC, researchers and developers were able to compare various algorithms and methods on an entity basis. This helped in enhancing the object classification methods and effectively stimulated the interaction and exchange of ideas among the computer vision specialists. Thus, the annotated images with their ground truth labels, collected as the project’s datasets, can be regarded as substantial benchmarks for training and testing the object detection and image recognition models that were so crucial for advancing this field of computer vision.
Pascal VOC Dataset Development
The Pascal VOC dataset was developed from 2005 to 2012. Each year, a new dataset was released for classification and detection tasks.
Here’s a brief overview of the dataset development:
VOC2005
The VOC2005 challenge aims to identify objects from different categories in real-world scenes (not pre-segmented or isolated objects). It is fundamentally a supervised learning task, meaning a labeled image dataset will be provided to train the object recognition model.
Here is a breakdown of this challenge’s statistics:
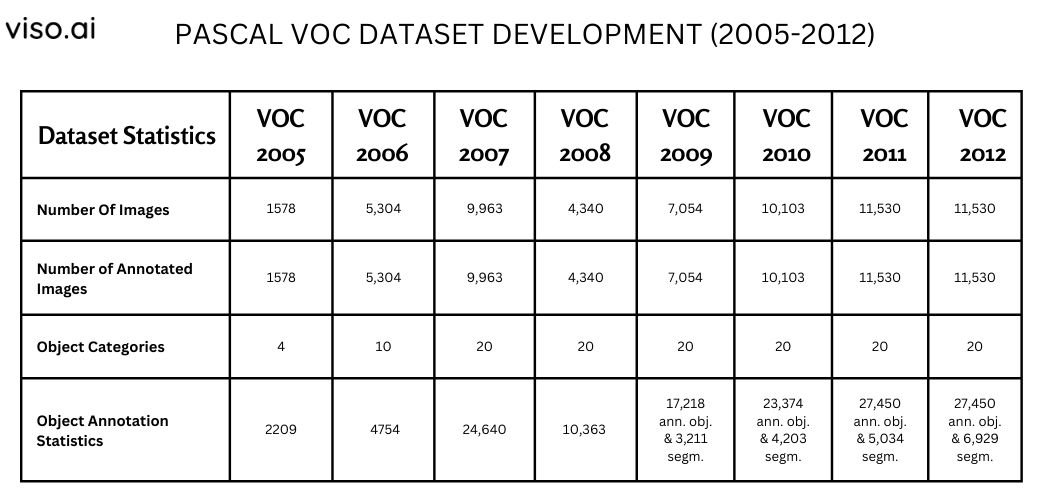
- Number Of Images: 1578
- Number of annotated images: 1578
- Object Categories: 4 Classes (Include the views of motorbikes, bicycles, people, and cars in arbitrary pose)
- Object annotation statistics: Contains 2209 annotated objects.
- Annotation Notes: Images were largely taken from existing public datasets. This dataset is now obsolete.

VOC2006
The VOC2006 challenge tasked participants with recognizing various object types in real-world scene images, rather than just pre-segmented objects. It was a supervised learning problem that included 10 object classes and more than five thousand pre-trained sets of labeled images.
Unlike the previous version (VOC2005) with clean backgrounds, VOC2006 presents a tougher challenge. Its dataset images include objects that are partially hidden behind other objects (occlusions), crammed with stuff (clutter), and captured from different angles (perspectives). This made VOC2006 more realistic but also much harder to solve.
Here is the actual breakdown of this dataset’s statistics:
- Number Of Images: 5,304
- Number of annotated images: 5,304
- Object Categories: 10 Classes (It includes the views of bicycles, buses, cats, cars, cows, dogs, horses, motorbikes, people, and sheep in arbitrary poses.)
- Object annotation statistics: Contains 4754 annotated objects.
VOC2007
VOC2007 was built on prior VOC challenges for object recognition in natural images. It expanded the dataset size and added a new task of pixel-wise object instance segmentation. The test data was more challenging, featuring increased diversity and complexity. Evaluation metrics were enhanced to analyze localization accuracy better and quantify performance across differing object truncation and occlusion levels.
Overall, VOC2007 raised the bar with its larger scale, instance segmentation task, and more comprehensive benchmarking of object detection and segmentation capabilities in realistic scenes.
Here are the dataset statistics of VOC2007:
- Number Of Images: 9,963
- Number of annotated images: 9,963
- Object Categories: 20 Classes
It includes:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor

- Object annotation statistics: Contains 24,640 annotated objects
- Annotation Notes: This year, they came up with a set of 20 categories that haven’t changed since. It was also the last year they released class labels for the test data.
VOC2008
While VOC2008 did not introduce new tasks or classes compared to VOC2007, it provided a fresh and sizeable annotated dataset of 4,340 images containing 10,363 labeled object instances across 20 categories. A key aspect of VOC2008 was the availability of pixel-wise segmentation annotations for all object instances, in addition to bounding boxes. Moreover, the dataset maintained a 50-50 trainval-test split, with standardized evaluation metrics like mean Average Precision (mAP) for ranking detection performance across Pascal VOC classes and intersection over union (IoU) for segmentation quality.
Here are the dataset statistics of VOC2008:
- Number Of Images: 4,340
- Number of annotated images: 4,340
- Object Categories: 20 Classes
It includes:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
- Object annotation statistics: Contains 10,363 annotated objects
VOC2009
The VOC2009 contains 7,054 annotated images, nearly double the size of VOC2008. Across these images, there were 17,218 annotated object instances from the same 20 classes covering people, animals, vehicles, and indoor objects.
This challenge has made this crucial change to the rules:
Test set annotations remained confidential. This means researchers had to develop algorithms that should excel in unseen data.
Here are the dataset statistics of VOC2009:
- Number Of Images: 7,054
- Number of annotated images: 7,054
- Object Categories: 20 Classes
It includes:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, TV/monitor
- Object annotation statistics: Contain 17,218 ROI annotated objects and 3,211 segmentations.
- Annotation Notes: There were no special instructions for the extra images. Moreover, the test data labels were not available.
VOC2010
VOC2010 further scaled up the benchmark, providing 10,103 annotated images – a 43% increase over VOC2009. These images contained 23,374 annotated object instances across the same twenty object classes, along with 4,203 pixel-wise segmentation masks.
This challenge has made this crucial change to the rules:
Instead of relying on pre-made samples, researchers are supposed to use all available data points that ensure a more accurate evaluation of CV algorithms.
However, like VOC2009, training, validation, and test set annotations were not publicly released. With its larger annotated Pascal VOC dataset size and updated evaluation protocol, VOC2010 presented a more comprehensive and robust benchmark for assessing object recognition capabilities on complex, real-world imagery at an increased scale.
These were the dataset statistics:
- Number Of Images: 10,103
- Number of annotated images: 10,103
- Object Categories: 20 Classes
It includes:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
- Object annotation statistics: Contains 23,374 ROI annotated objects and 4,203 segmentations.
- Annotation Formats: The way Average Precision (AP) is calculated has been updated. Instead of using a sampling method like TREC, all data points are now included in the calculation. Additionally, in that challenge, the annotations for the test data were not publicly available.
VOC2011
PASCAL VOC challenge took a big step forward in 2011 with VOC2011. This dataset released a massive amount of data that included 11,530 images – the largest collection.
It features a dataset with 27,450 labeled object instances across 20 classes. It further provides 5,034 instances with pixel-wise segmentation masks. All the rules were the same as those of VOC2010.
These were the VOC2011’s dataset statistics:
- Number Of Images: 11,530
- Number of annotated images: 11,530
- Object Categories: 20 Classes
It includes:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
- Object annotation statistics: Contains 27,450 ROI annotated objects and 5,034 segmentations.
- Annotation Notes: The approach to calculating average precision (AP) has changed. Instead of using a specific sampling method (TREC), it now considers all available data points. Additionally, annotations for the train data are no longer publicly available.
VOC2012
The Pascal VOC2012 datasets for classification, detection, and person layout are the same as VOC2011. No additional data has been annotated. It also included nearly 28,000 labeled objects from a number of 20 different categories. These objects were marked with bounding boxes and Pascal VOC segmentation masks that make it easier for computers to recognize objects.
This significant increase in data made VOC2012 a tougher test for object recognition algorithms. The dataset challenged these algorithms to perform well on real-world images with more objects and complexity, all while using the same evaluation methods.

- Number Of Images: 11,530
- Number of Annotated Images: 11,530
- Object Categories: 20 Classes
It includes:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, TV/monitor
- Object annotation statistics: Contains 27,450 ROI annotated objects and 6,929 segmentations.
- Annotation Notes: The dataset for classification, detection, and person layout tasks remains unchanged from VOC2011.
Key Tasks Supported by Pascal VOC
The Pascal VOC datasets support and evaluate various computer vision tasks, including:
Object Classification
The Pascal VOC dataset supports object classification by providing labeled images with multiple object categories, enabling training and evaluation of models that assign a single label to an entire image based on the object’s presence.

Object Detection
For object detection, the dataset has images that provide annotated bounding boxes around objects to help the models learn which categories of objects to identify and their positions in images.
Image Segmentation
Some images have ground-truth pixel-level annotations, which allow for semantic segmentation where the model models segment and classify individual pixels, precisely delineating object boundaries.

Action Classification
The dataset contains annotations for human actions that enable the training and evaluation of action classification models. They can identify and differentiate between various human actions or interactions with objects within images.
Notable Methodologies And Models Evaluated On Pascal VOC
The Pascal VOC datasets served as a testbed for various computer vision methodologies and models, ranging from traditional approaches to deep learning techniques. Here are some notable examples:
Traditional Approaches
- Sliding Window Detectors: This method uses a fixed-size window to compare object presence in different places of the image. The examples include Viola-Jones detectors and Histogram of Oriented Gradients detectors.
- Bag-of-Visual-Words Models: These models represented images as histograms of visual words, and each visual word from the histogram corresponded to a local image patch or texture feature. The two most recognized and potentially effective approaches are Spatial Pyramid Matching (SPM) and Bag of Visual Words (BoVW).
- Deformable Part-based Models: These models worked on the assumption that objects were made up of a smaller number of geometric pieces that could be distorted, which made the models more versatile. An example of such representations is constituted by the Deformable Part Model introduced by Felzenszwalb et al.
Deep Learning Approaches
- Convolutional Neural Networks (CNNs): The CNNs including AlexNet, VGGNet, and ResNet helped solve computer vision problems by learning the hierarchal features directly from the Pascal VOC data. These models were able to set benchmark accuracy on the Pascal VOC classification and detection challenges.
- Region-based Convolutional Neural Networks (R-CNNs): Fast R-CNN and Faster R-CNN models integrated region proposal strategies with CNNs for object detection and localization with very high accuracy on Pascal VOC datasets.
- You Only Look Once (YOLO): The YOLO model presented a unified method of detection of object detection. YOLO, along with its variants, was tested on Pascal VOC datasets and demonstrated high performance and real-time capabilities.
- Mask R-CNN: Mask R-CNN is an extension of the Faster R-CNN model. It predicts segmentation masks for state-of-the-art instance segmentation on Pascal VOC datasets.
Transition To Newer Datasets
Over time, computer vision studies and deep learning algorithms developed, and the limitations of Pascal VOC datasets became increasingly noticeable. Researchers also saw a demand for increased and more varied benchmarks and higher-quality annotations that are important for further development of the field.
COCO
The COCO dataset was created in 2014 and it was much larger with over 300,000 images describing 80 categories of objects and detailed annotations, including instance segmentation masks and captions.
OpenImages
The OpenImages dataset contains over 9 million training images with bounding boxes, segmentation masks, and visual relationships. It offers variety and difficulty since it can be used for multiple computer vision.
Future Directions
The Pascal VOC has a promising future in computer vision. As the field advances, there will be a need to use larger, more diverse, and more challenging datasets to drive the field forward. Any data with more complicated scenarios from multi-modal data to real-world situations will be essential for training general and stable learning models.
To sum up, benchmark datasets like Pascal VOC indeed play an important role in computer vision studies. We expect to see further developments of Pascal VOC benchmark datasets enhancing the machine learning domain.
What’s Next?
As computer vision research progresses and new challenges emerge, the development of more diverse, complex, and large-scale datasets will be critical for pushing the boundaries of what is possible. While the Pascal VOC dataset has played a pivotal role in shaping the field, the future lies in embracing new datasets and benchmarks that better reflect the diversity and complexity of the real world.
To learn more about computer vision and machine learning, we suggest checking out our other blogs:
- Learn about different computer vision datasets, such as COCO and ImageNet
- The Definitive Guide to Object Detection
- Understand the Concepts of Image Segmentation – Semantic, Instance, and Panoptic Segmentation
- Best AI Software Tools and Solutions for Image Annotations