
In the past few years, a new type of machine learning has taken the world by storm: Generative Adversarial Networks, or GANs. So what is a GAN, and why are those AI models to popular?
In this article, we’ll introduce GANs and explain why they’re so important. We’ll also give a brief overview of the following topics:
- What GANs are and how they work
- How to Train Generative Adversarial Networks
- Popular real-world applications of GANs
- The biggest challenges of GANs
- Variants and alternatives
- Examples and tutorials
What are Generative Adversarial Networks (GANs)?
A generative adversarial network is a class of machine learning frameworks. Based on a training data set, a GAN learns to generate new data with the same statistics as the training set. The data created by the GAN can be anything, such as images, videos, or text.
What are generative models?
A generative model is a type of machine learning algorithm that is used to generate new data based on a given set of input data. This can be useful for tasks such as image generation, text generation, and other types of data synthesis.

What is the history of GANs?
In 2014, a paper on generative adversarial networks (GANs) was published by Ian Goodfellow and his colleagues. This research paper proposed a new framework for unsupervised learning, in which two neural networks are trained to compete against each other.
Since then, GANs have become one of the most popular and widely used types of neural networks for generative modeling. In recent years, GANs have also been useful for data augmentation, reinforcement learning, and semi-supervised learning techniques.
Training Generative Adversarial Networks
How do GANs work?
A generative adversarial network (GAN) is a type of AI model. The architecture of a GAN consists of two separate neural networks that are pitted against each other in a game-like scenario. The first network, known as the generator network, tries to create fake data that looks real.
The second network, known as the discriminator network, is typically a convolutional neural network (CNN) that tries to distinguish between data generated by the GAN (fake data) and real data. The network learns to classify these examples correctly, and this information is used to adjust the generator network to create more realistic data that is indistinguishable from real data, as determined by the discriminator network.
The image below visualizes the concept of how GANs work: Generative adversarial nets are trained until they reach a point when they both cannot improve because the generative distribution (green) is equal to the data-generating distribution (dotted line). And the discriminator is unable to differentiate between the two distributions (dashed blue line shows the discriminative distribution).
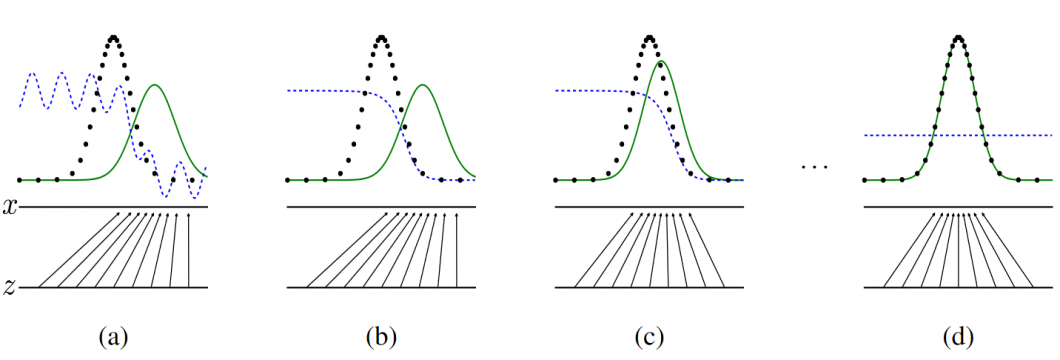
Over time, the generator gets better at creating fake data that fools the discriminator, and the discriminator gets better at distinguishing between fake and real data. In other words, the goal is to create fake data that is so realistic it can fool the generator and the discriminator.
Mathematically, GANs try to replicate a probability distribution. Therefore, they use loss functions that reflect the distance between the distribution of the fake data and the distribution of the real data.
What is a loss function?
A loss function is a mathematical function that is used to measure the difference between two datasets. In the context of a GAN, the generator model is trained by optimizing a loss function that measures the difference between the generated data and the training data (e.g., annotated images with a class label).
The discriminator model, on the other hand, is trained by optimizing a loss function that measures the difference between the generated data and the real data.
GANs as a two-player game
In the context of GANs, the two players are the two models, the generator and the discriminator. The generator algorithm tries to generate data that is indistinguishable from real data, while the discriminator algorithm tries to differentiate between generated data and real data.
One way to think about it is as a competition between two players. The generator is trying to fool the discriminator, while the discriminator is trying to spot the fakes. This game can be used to learn a generative model of data. In other words, the generator is learning to generate data that looks like real data.
The GAN game can be seen as a zero-sum game, where the generator is trying to maximize its score, and the discriminator is trying to minimize the generator’s score. The goal of training a GAN is to find a Nash Equilibrium, where neither player is able to improve their score by making any changes to their strategy.
This game-like ML technique can also be used for unsupervised learning. In this case, the generator is trying to produce new data that is similar to the real data instances, without being given annotated training data with class labels (see image annotation).

What is the difference between CNN vs. GAN?
Both Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs) are deep learning architectures. GANs are generative models that can generate new examples from a given training set, while convolutional neural networks (CNNs) are primarily used for classification and recognition tasks.
While a single CNN can also be used as a generative model if you set it up to be a Variational Autoencoder (VAE), CNNs are powerful tools for discriminative learning and are particularly suitable for classifying images in computer vision.
Discriminative Models vs. Generative Models
The discriminative model is a machine learning algorithm used to distinguish between different categories of data, for example, for image classification and object detection. A generative modeling algorithm, on the other hand, is used to generate new data that is similar to the data that was used to train the model.
One of the key differences between generative and discriminative models is that a generative model can generate new examples, while a discriminative model can classify data. Another difference is that a generative model is typically more complex than a discriminative model.
This is because a generative model needs to learn the underlying probability distribution of the data, while a discriminative model only needs to learn the mapping between inputs and outputs.
The ultimate objective of discriminative models is to separate pre-defined and learned classes. If we have some outliers present in the dataset, then discriminative models work better compared to generative models i.e., discriminative models are more robust to outliers.

The most popular applications of Generative Adversarial Networks
GANs can be used for a variety of AI tasks, such as machine learning-based image generation, video generation, and text generation (for example, in natural language processing, NLP). The major benefit of generative adversarial networks is that they can be used to create new data instances where data collection is difficult or impossible.
Hence, GANs have been successfully applied in various practical applications in image synthesis and computer vision.
Generating images from scratch
Image generation is the process of creating new images from scratch. This is often done by first training a GAN to learn the distribution of a dataset, and then generating new images from random noise vectors. GANs can be applied to generate realistic images of people, animals, and other objects. This can be used for things like creating realistic-looking advertising visuals or adding new content to video games.
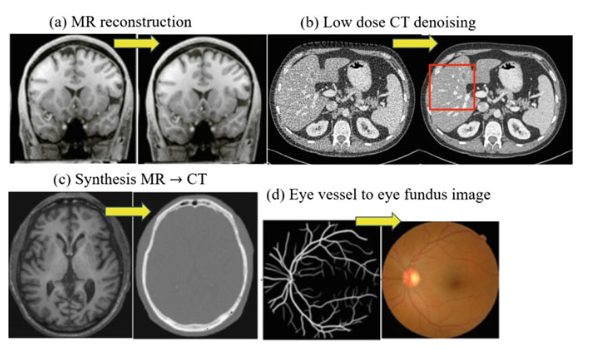
In Healthcare, GANs are very effective in generating images for medical image analysis. In particular, GANs have been used to create realistic images of organs for surgical planning or simulation training. For example, generated samples of tumors can be used for diagnosis and treatment planning.
Commercial AI generation tools like Midjourney use GANs to create photo-realistic deepfake images.

Generating 3D from 2D
Another application is to use GANs to create 3D images from 2D ones. This can be used to create more realistic-looking 3D models or add new depth and realism to existing images.
Create art with AI
GANs have been used to generate art that replicates the styles of famous artists. In one study, a generative adversarial network was trained to generate portraits in the style of Rembrandt (style transfer). The portraits generated by the GAN were indistinguishable from genuine Rembrandt portraits.
Check out our article about other generative models, such as the popular DALLE-2, which uses a version of GPT-3 to generate ultra-realistic images from text.

Face generation
GANs have also been used to generate realistic-looking images of faces, so-called deepfakes. In a research project, a GAN was trained on a dataset of celebrity faces and was able to generate new, realistic-looking faces that resembled the celebrities in the training dataset.
Medical image processing
Generative Adversarial Networks (GANs) are widely used in medical image processing for data augmentation due to their excellent image-generation capabilities. Using GANs for image augmentation in existing medical image datasets can significantly increase the sample size of training sets for AI medical image diagnosis and treatment models.
To a certain extent, it alleviates the limited sample size of medical images due to inherent limitations such as imaging cost, labeling cost, and patient privacy. Read more about computer vision in healthcare.
Improve image quality
Other applications for GANs include image super-resolution, where a low-resolution image is upscaled to a higher resolution. A generative adversarial network can be used to remove artifacts from images or to improve the resolution of images.
Additionally, GANs can be used to colorize black-and-white images or to add new details to an image.
Social media fake bots
GAN has also been used to create fake news articles and reviews and to generate text conversations that seem realistic. Using a GAN, a bot can be trained to generate data such as realistic tweets that are more likely to fool other users into thinking they are real.
This could be used for several purposes, such as creating fake accounts that are used to spread disinformation or promote a certain agenda. GANs could also be used to create believable automated replies to tweets, which is used for automated customer service on Twitter or Facebook.
Challenges of Generative Adversarial Networks
GAN training
One of the main challenges in training generative adversarial networks is getting them to converge and produce good results. GANs are often unstable and difficult to train.
Many factors can contribute to this, such as the initialization of the networks, the type of data used for training, and the way the networks are configured. Additionally, GANs often require a large amount of data to train effectively. This can be a challenge when working with limited datasets.

Mode collapse
Another challenge of GANs is mode collapse. This occurs when the generator learns to generate only a subset of the possible outputs. Mode collapse can be a problem because it limits the variety of outputs that can be generated by the GAN. For example, if a GAN is trained on images of faces, it may learn to only generate one type of face or a limited number of variations.
One way to avoid mode collapse is to use a diversity-promoting loss function. This loss function encourages the generator to generate a variety of outputs, rather than just a few. Additionally, using a larger dataset can also help to avoid mode collapse.
A very effective way to combat mode collapse is to use a machine learning technique called minibatch discrimination. With minibatch discrimination, the discriminator is not only trying to classify whether a given image is real or fake, but also which group of images it belongs to.
This forces the generator to produce more diverse outputs and can help to prevent mode collapse. Using a Convolutional neural network (CNN) has been shown to be a particularly effective solution since they are also well-suited to working with images.
Computational challenges
GANs can be computationally intensive, both in terms of machine learning training and inference. They often require large amounts of data and can take a long time to train. Additionally, GANs can be difficult to deploy because they require a lot of computational resources.
There are a number of ways to address the computational challenges of GANs. One is to use parallel training, which can help to speed up training. Another is to use distributed training, which can help to distribute the computational burden across multiple nodes or machines, for example, with edge computing.
Finally, model compression techniques can be used to reduce the size of the model, which can help to reduce the computational requirements.
Training data overtraining
Over-training is a typical challenge of training a GAN, where the generator network produces very accurate but meaningless data samples that do not reflect the real world in any way. A possible solution to the over-training problem is to use a bigger training set. This will help the network to learn more about the real world and will prevent it from overfitting to the training data.
Another solution is to use a validation set. This is a set of data that is used to test the accuracy of the network after training. If the network does not perform well on the validation set, then it is likely over-trained and needs to be retrained.
Different Generative Adversarial Network variants
There are multiple variants of GAN architectures and other related generative models. In the original paper, the authors implemented GANs using multilayer perceptron networks (MLPs) and convolutional neural networks (CNNs). In the following, we will discuss other generative models, tools, and variations of generative adversarial nets.
What is the best Generative Adversarial Network?
There is no definitive answer to this question as different GANs work best for different tasks. However, some of the most popular GANs include the Wasserstein GAN, the Improved GAN, and the DCGAN.
Conditional GAN (CGAN)
Recently, conditional GANs (cGAN) have received significant attention in the field of image generation and text-to-image synthesis. A conditional generative adversarial network (CGAN) is a supervised learning technique that involves using both labeled and unlabeled data to train a generative adversarial network. The aim is to improve the accuracy of predictions by the model.
The ability of conditional GANs to learn from both annotated and unannotated data is beneficial because it can reduce the amount of labeled data required to train the model. In addition, Conditional GANs can also handle data that is not linearly separable.
There are some drawbacks to cGAN as well. One limitation is that the model can only generate examples that are similar to the training data. This means that the model is not able to generalize to new data.
In addition, cGAN can be sensitive to changes in the training data. This can lead to model overfitting and poor performance on test data.
Adversarial Autoencoder (AAE)
An adversarial autoencoder is an autoencoder that uses an adversarial network to regularize the latent space of the autoencoder. The adversarial network is used to encourage the latent space to have desired properties, such as being Gaussian or having a uniform distribution.
The autoencoder part of the network is trained to reconstruct the input, while the adversarial network is trained to distinguish between the latent code produced by the autoencoder and a sample from the desired distribution.
This setup can be thought of as a game between the autoencoder and adversarial network, where the autoencoder is trying to fool the adversarial network by producing latent codes that match the desired distribution, and the adversarial network is trying to learn to distinguish between the codes produced by the autoencoder and the samples from the desired distribution.
Dual GAN (DGAN)
A variant of GAN where two networks are trained in parallel with two sets of unlabeled images as input, one network for generating images and the other for discriminating between generated images and real images.
DualGAN simultaneously learns two reliable image translators from one domain to the other and hence can be used for a broad range of image-to-image translation tasks.
Stack GAN (StackGAN)
A variation of GAN where multiple generators are stacked together to produce a more realistic image. Stacked GANs form a network capable of generating high-resolution images.
Cycle GAN (CycleGAN)
A CycleGAN is a technique to translate from one image domain to another for automatic image-to-image translation models, without requiring paired data samples.
Superresolution GAN (SRGAN)
A GAN that can generate high-resolution images from low-resolution inputs. Super-resolution GANs apply a deep network in combination with an adversary network to increase the resolution of input data.
Deep convolutional GAN (DCGAN)
A GAN that uses deep convolutional neural networks in the generator and discriminator. The GAN consists entirely of convolution-deconvolution layers (Fully convolutional networks). Research indicates that images generated using the DCGAN model architecture were significantly better (less noisy).
Wasserstein GAN (WGAN)
A GAN that minimizes the Wasserstein-1 distance between the real and generated distributions. The Wasserstein distance is a metric for the distance between two probability distributions.
Energy-based GAN (EBGAN)
A GAN uses an energy function to measure the similarity between real and generated images. The energy function is used to define a loss function that is minimized during training.
Mode regularized GAN (MRGAN)
A GAN variation that uses a mode regularizer to encourage the generator to generate images from all modes of the data distribution. The mode regularizer is a penalty function that encourages the generator to generate images that are close to the modes of the data distribution.
GAN alternatives and other generative models
There are many different types of generative models, each with its advantages and disadvantages. In this section, we will briefly list some of the more popular ones.
Naïve Bayes
Naïve Bayes is a simple generative model that makes strong independence assumptions between features. Despite its simplicity, it can sometimes outperform more sophisticated models.
Bayesian networks
Bayesian networks are a type of probabilistic graphical model that can represent complex dependencies between variables. They are often used in applications such as diagnosis and prediction.
Markov random fields
Markov random fields are a type of undirected graphical model that can represent complex interactions between variables. They are commonly used in image processing and computer vision.
Hidden Markov Models (HMMs)
Hidden Markov models are a type of statistical model that can be used to model time-varying processes. They are commonly used in speech recognition and bioinformatics.
Latent Dirichlet Allocation (LDA)
Latent Dirichlet allocation is a type of probabilistic model that can be used to generate text documents. It is commonly used in topic modeling and text classification.
Generative Adversarial Networks (GANs)
Generative adversarial networks are a type of neural network that can be used to generate realistic images. They are often used in image synthesis and computer vision.
Autoregressive Model (AR)
Autoregressive models are a type of statistical model that can be used to predict future values of a time series based on past values. They are commonly used in time series forecasting.
Examples and tutorials of Generative Adversarial Networks
How to create your own GAN model in Python
To create your own GAN model in Python, you will need the following: (1) a training dataset, (2) a generator script, and (3) a discriminator script.
- The training dataset will be used to train both the generator and discriminator scripts. You can use TF-GAN, a popular lightweight software library for training generative adversarial networks in TensorFlow. It is used for numerous projects at Google and the underlying technology for many commercial applications and software platforms.
- You can train the AI model using a Jupyter Notebook. To get started fast, Google Colab provides an easy way to create a GAN model in a notebook. You can find the tutorial to set up TF-GAN here.
- Once you have your training dataset and scripts, you can begin training your GAN model. Start by training the generator script on the training dataset. The generator will create artificial data that looks similar to the real data in the training dataset.
- Next, train the discriminator script on both the real data in the training dataset and the artificial data generated by the generator. The discriminator will learn to identify which data is real and which is fake.
- Finally, train the generator script on the newly generated data by the discriminator. This allows the generator to create artificial data that is more realistic and difficult for the discriminator to identify as fake.
Once you have trained your GAN model, you can use it to generate new data. For example, you could use your GAN model to generate new images of people or objects.
Tutorial to train a conditional GAN
You can find more information on how to train a conditional GAN model here, with a detailed tutorial for training a GAN conditioned on class labels to generate MNIST handwritten digits.
The Bottom Line
GANs are a type of generative model used to create new data. They are popular because they can be used to generate synthetic image samples, which can be useful for tasks such as image recognition or object detection.
In this article, we have provided an overview of GANs and how to train them. We have also provided examples of how GANs can be used to generate new data. If you are interested in learning more about GANs, we suggest checking out the resources below.