
Large Action Models (LAMs) are deep learning models that aim to understand instructions and execute complex tasks and actions accordingly. LAMs also combine language understanding with reasoning and software agents.
Although still under research and development, these models can be transformative in the Artificial Intelligence (AI) world. LAMs represent a significant leap beyond text generation and understanding. They have the potential to revolutionize how we work and automate tasks across many industries.
What Are Large Action Models and How Do They Work?
Large Action Models (LAMs) are AI software designed to take action in a hierarchical approach where tasks are broken down into smaller subtasks. Actions are performed from user-given instructions using agents.
Unlike large language models, a Large Action Model combines language understanding with logic and reasoning to execute various tasks. This approach can often learn from feedback and interactions, although not to be confused with reinforcement learning.
Neuro-symbolic programming has been an important technique in developing more capable Large Action Models. This technique combines learning capabilities and logical reasoning from neural networks and symbolic AI. By combining the best of both worlds, LAMs can understand language, reason about potential actions, and execute based on instructions.
The architecture of a Large Action Model can vary depending on the wide range of tasks it can perform. However, understanding the differences between LAMs and LLMs is essential before diving into their components.
LLMs VS. LAMs
| Feature | Large Language Models (LLMs) | Large Action Models (LAMs) |
|---|---|---|
| What can it do | Language Generation | Task Execution and Completion |
| Input | Textual data | Text, images, instructions, etc. |
| Output | Textual data | Actions, Text |
| Training Data | Large text corporation | Text, code, images, actions |
| Application Areas | Content creation, translation, and chatbots | Automation, decision-making, and complex interactions |
| Strengths | Language understanding, text generation | Reasoning, planning, decision-making, and real-time interaction |
| Weaknesses | Limited reasoning, lack of action capabilities | Still under development, ethical concerns |
At this point, we can delve deeper into the specific components of a large action model. Those components usually are:
- Pattern Recognition: Neural Networks
- Symbolic AI: Logical Reasoning
- Action Model: Execute Tasks (Agents)
Neuro-Symbolic Programming
Neuro-symbolic AI combines neural networks’ ability to learn patterns with symbolic AI reasoning methods, creating a powerful synergy that addresses the limitations of each approach.
Symbolic AI, often based on logic programming (basically a bunch of if-then statements), excels at reasoning and explaining its decisions. It uses formal languages, like first-order logic, to represent knowledge and an inference engine to draw logical conclusions based on user queries.
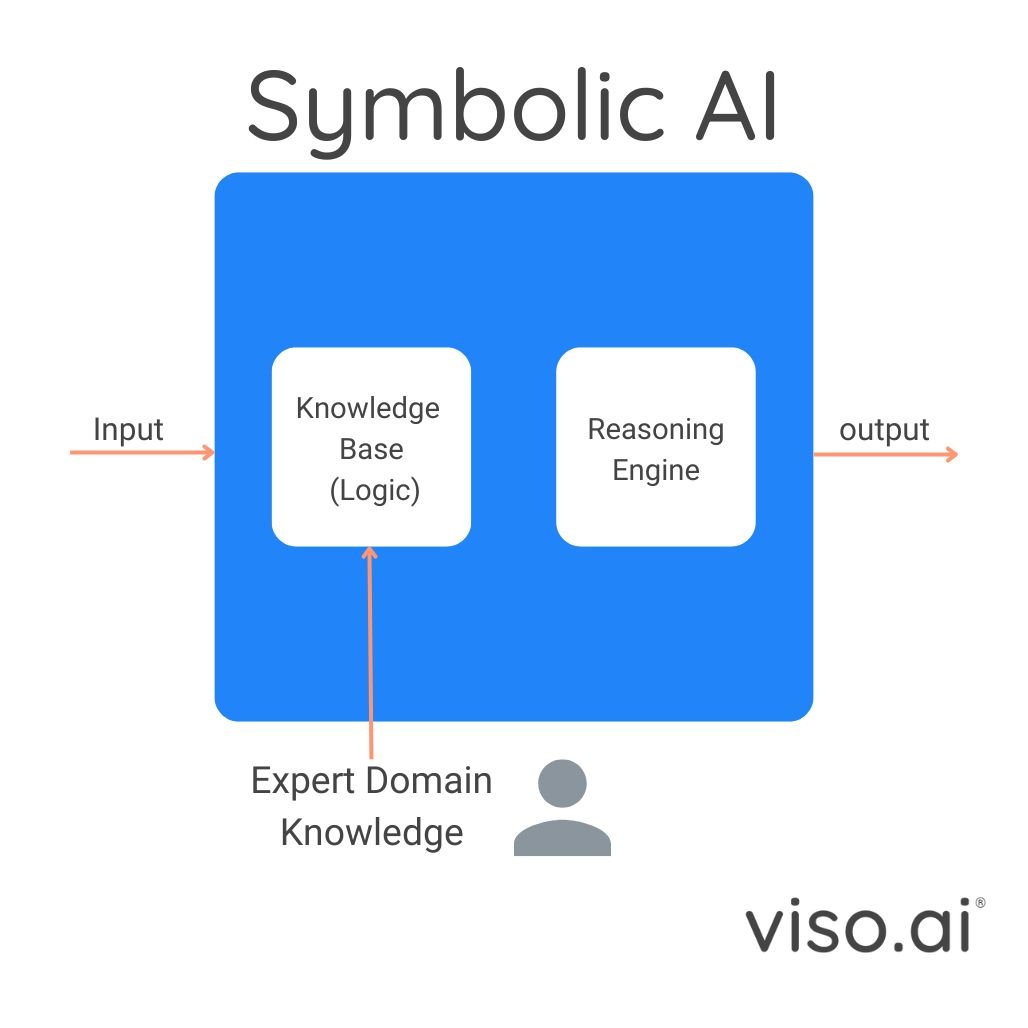
This ability to trace outputs to the rules and knowledge within the program makes the symbolic AI model highly interpretable and explainable. Additionally, it allows us to expand the system’s knowledge as new information becomes available. But this approach alone has its limitations:
- New rules don’t undo old knowledge
- Symbols are not linked to representations or raw data.
In contrast, the neural aspect of neuro-symbolic programming involves deep neural networks like LLMs and vision models, which thrive on learning from massive datasets and excel at recognizing patterns within them.
This pattern recognition capability allows neural networks to perform tasks like image classification, object detection, and predicting the next word in NLP. However, they lack the explicit reasoning, logic, and explainability that symbolic AI offers.
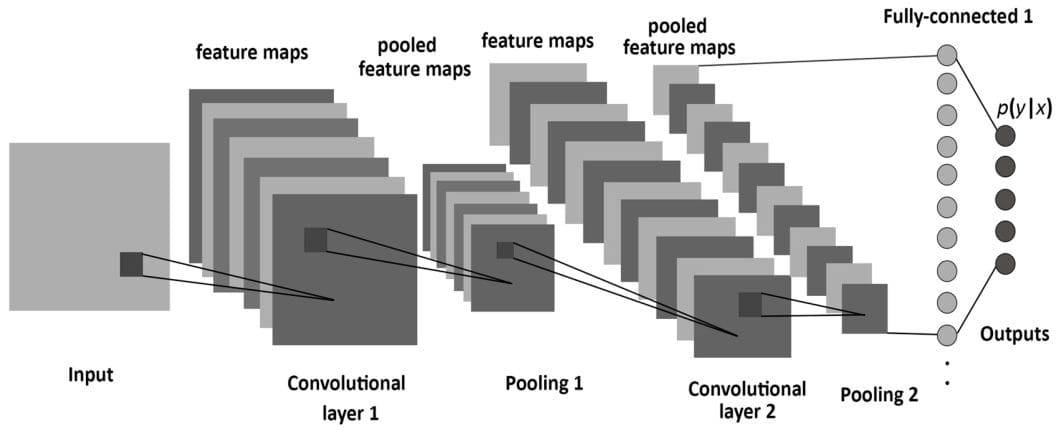
Neuro-symbolic AI aims to merge these two methods, giving us technologies like Large Action Models (LAMs). These systems can blend the powerful pattern-recognition abilities of neural networks with the symbolic AI reasoning capabilities, enabling them to reason about abstract concepts and generate explainable results.
Neuro-symbolic AI approaches can be broadly categorized into two main types:
- Compressing structured symbolic knowledge into a format that can be integrated with neural network patterns. This allows the model to reason using the combined knowledge.
- Extracting information from the patterns learned by neural networks. This extracted information is then mapped to structured symbolic knowledge (a process called lifting) and used for symbolic reasoning.
Action Engine
In Large Action Models (LAMs), neuro-symbolic programming empowers neural models like LLMs with reasoning and planning abilities from symbolic AI methods.
The core concept of AI agents is used to execute the generated plans and possibly adapt to new challenges. Open-source LAMs often integrate logic programming with vision and language models, connecting the software to tools and APIs of useful apps and services to perform tasks.
Let’s see how these AI agents work.
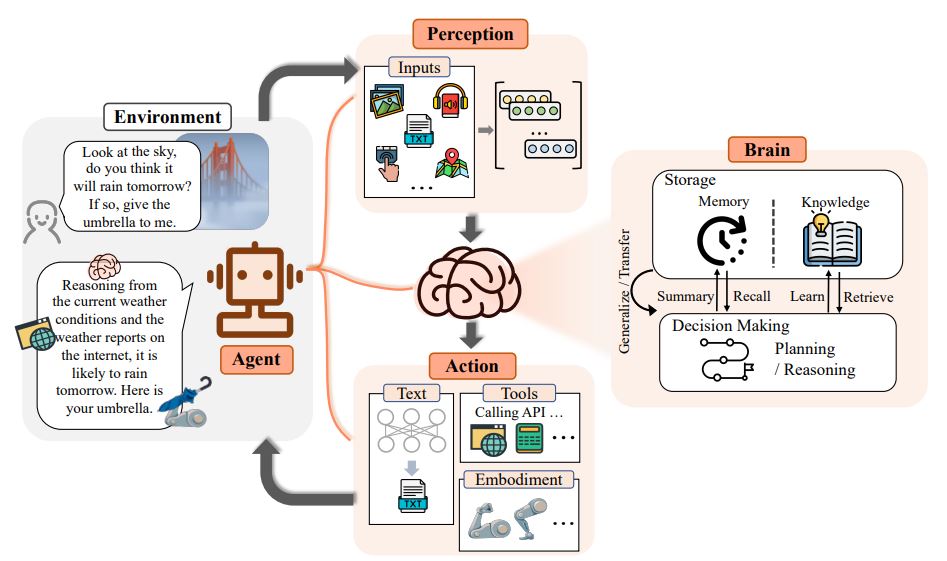
An AI agent is software that can understand its environment and take action. Actions depend on the current state of the environment and the given conditions or knowledge. Furthermore, some AI agents could adapt to changes and learn based on interactions.
Using the visualization above, let’s put the way a Large Action Model makes our requests into action:
- Perception: A LAM receives input as voice, text, or visuals, accompanied by a task request.
- Brain: This could be the neuro-symbolic AI of the Large Action Model, which includes capabilities to plan, reason, memorize, and learn or retrieve knowledge.
- Agent: This is how the large action model takes action, as a user interface or a device. It analyzes the given input task using the brain and then takes action.
- Action: This is where the doing starts. The model outputs a combination of text, visuals, and actions. For example, the model could reply to a query using an LLM capability to generate text and take action based on the reasoning capabilities of symbolic AI. The action involves breaking down the task into subtasks, performing each subtask using features like calling APIs or leveraging apps, tools, and services through the agent software program.
What Can Large Action Models Do?
Large Action Models (LAMs) can almost do any task they are trained to do. By understanding human intention and responding to complex instructions, LAMs can automate simple or complex tasks, and make decisions based on text and visual input. Crucially, LAMs often can incorporate explainability allowing us to trace their reasoning process.
Rabbit R1 is one of the most popular large action models and a great example to showcase the power of these models. Rabbit R1 combines:
- Vision tasks
- Web portal for connecting services and applications, and adding new tasks with teach mode.
- Teach mode allows users to instruct and guide the model by doing the task themselves.
While the term large action models already existed and was an ongoing area of research and development, Rabbit R1 and its OS popularized it. Open-source alternatives existed, often incorporating similar principles of logic programming and vision/language models to interact with APIs and perform actions based on user requests.
Open-Source Models
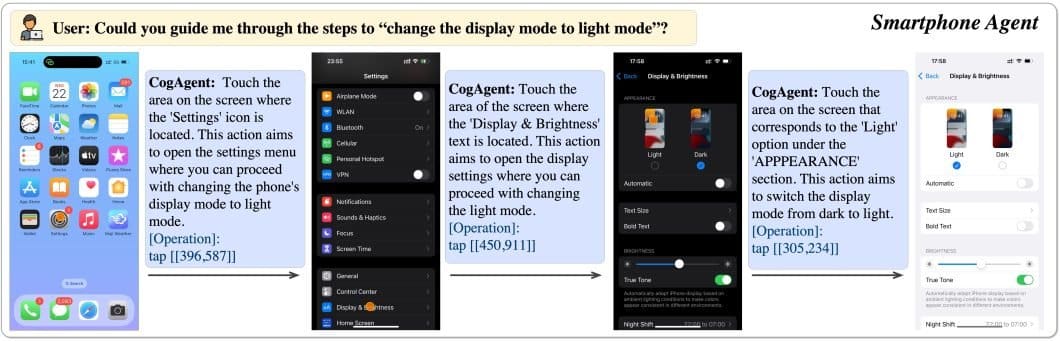
1. CogAgent
CogAgent is an open-source Action Model, based on CogVLM, an open-source vision language model. It is a visual agent capable of generating plans, determining the next action, and providing precise coordinates for specific operations within any given GUI screenshot.
This model can also do visual question answering (VQA) on any GUI screenshot and OCR-related tasks.
2. Gorilla
Gorilla is an impressive open-source large action model empowering LLMs to utilize thousands of tools through precise API calls. It accurately identifies and executes the appropriate API call, by understanding the needed action from natural language queries. This approach has successfully invoked over 1,600 (and growing) APIs with exceptional accuracy while minimizing hallucination.
Gorilla utilizes its proprietary execution engine, GoEx, as a runtime environment for executing LLM-generated plans, including code execution and API calls.
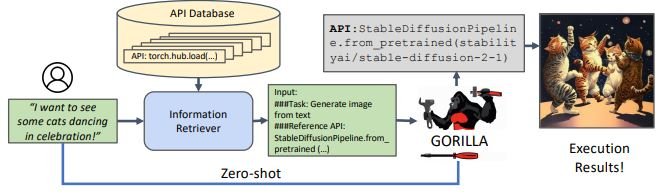
The visualization above shows a clear example of large action models at work. Here, the user wants to see a specific image, and the model retrieves the needed action from the knowledge database and executes the needed code through an API call, all in a zero-shot manner.
Real-World Applications of Large Action Models
The power of Large Action Models (LAMs) is reaching into many industries, transforming how we interact with technology and automate complex tasks. LAMs are proving their worth as a comprehensive tool.
Let’s delve into some examples where large action models can be applied.
- Robotics: Large Action Models can create more intelligent and autonomous robots capable of understanding and responding. This enhances human-robot interaction and opens new avenues for automation in manufacturing, healthcare, and even space exploration.
- Customer Service and Support: Imagine a customer service AI agent who understands a customer’s problem and can take immediate action to resolve it. LAMs can make this a reality by streamlining processes like ticket resolution, refunds, and account updates.
- Finance: In the financial sector, LAMs can analyze complex data based on knowledgeable input, and provide personalized recommendations and automation for investments and financial planning.
- Education: Large Action Models could transform the educational sector by offering personalized learning experiences depending on each student’s needs. They can provide instant feedback, assess assignments, and generate adaptive educational content.
These examples highlight just a few ways LAMs can revolutionize industries and enhance our interaction with technology. Research and development in Large Action Models are still in the early stages, and we can expect them to unlock further possibilities.
What’s Next For Large Action Models?
Large Action Models (LAMs) could redefine how we interact with technology and automate tasks across various domains. Their unique ability to understand instructions, reason with logic, make decisions, and execute actions all has immense potential. From enhancing customer service to revolutionizing robotics and education, LAMs offer a glimpse into a future where AI-powered agents seamlessly integrate into our lives.
As research progresses, we can anticipate LAMs becoming more sophisticated, capable of handling even high-level complex tasks and understanding domain-specific instructions. However, as with any power comes responsibility. Ensuring the safety, fairness, and ethical use of LAMs is crucial.
Addressing challenges like bias in training data and potential misuse will be vital as we develop and deploy these powerful models. The future of LAMs is bright. As they evolve, these models will have a role in shaping a more efficient, productive, and human-centered technological landscape.
Learn More About Computer Vision
We post about the latest news, updates, technology, and releases in the world of computer vision on the viso.ai blog. Whether you’ve been in the field for a while or are just getting your start, check out our other articles on computer vision and AI:
- An Exhaustive Guide to AI Models
- Open Source Computer Vision: Introducing OpenCV
- A Deep Dive into AI at the Edge
- Gradient Descent in Computer Vision
- OpenAI Sora: Discussing the Text-Driven Video Generative AI
- What are Liquid Neural Networks?