
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computer vision. This state-of-the-art instance segmentation model showcases a groundbreaking ability to perform complex image segmentation tasks with unprecedented precision and versatility.
Unlike traditional models that require extensive training on specific tasks, the segment-anything project design takes a more adaptable approach. Its creators took inspiration from recent developments in natural language processing (NLP) with foundation models.
SAM’s game-changing impact lies in its zero-shot inference capabilities. This means that SAM can accurately segment images without prior specific training, a task that traditionally requires tailored models. This leap forward is due to the influence of foundation models in NLP, including the GPT and BERT models.
These models revolutionized how machines understand and generate human language by learning from vast data, allowing them to generalize across various tasks. SAM applies a similar philosophy to computer vision, using a large dataset to understand and segment a wide variety of images.

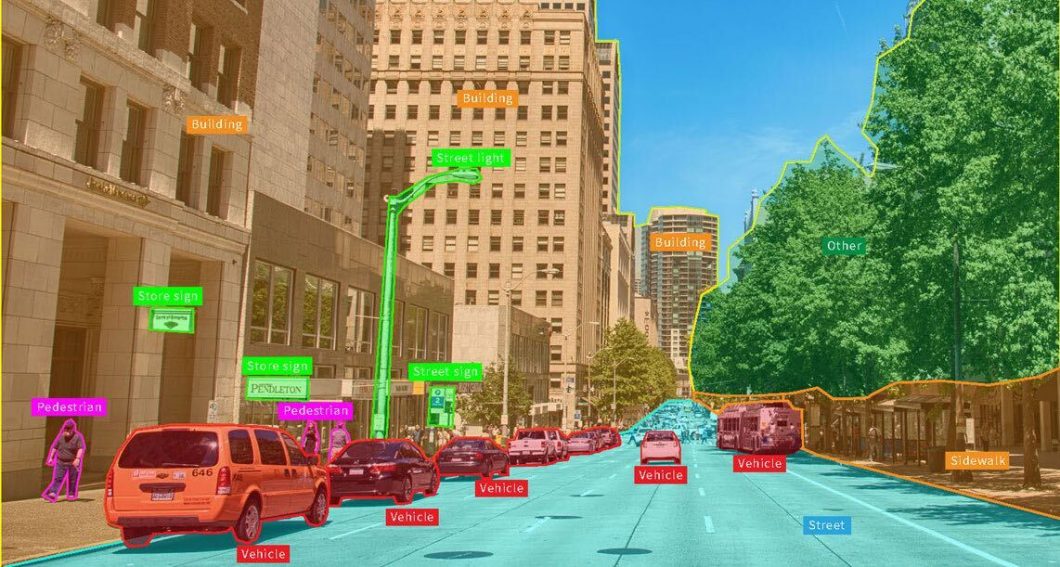
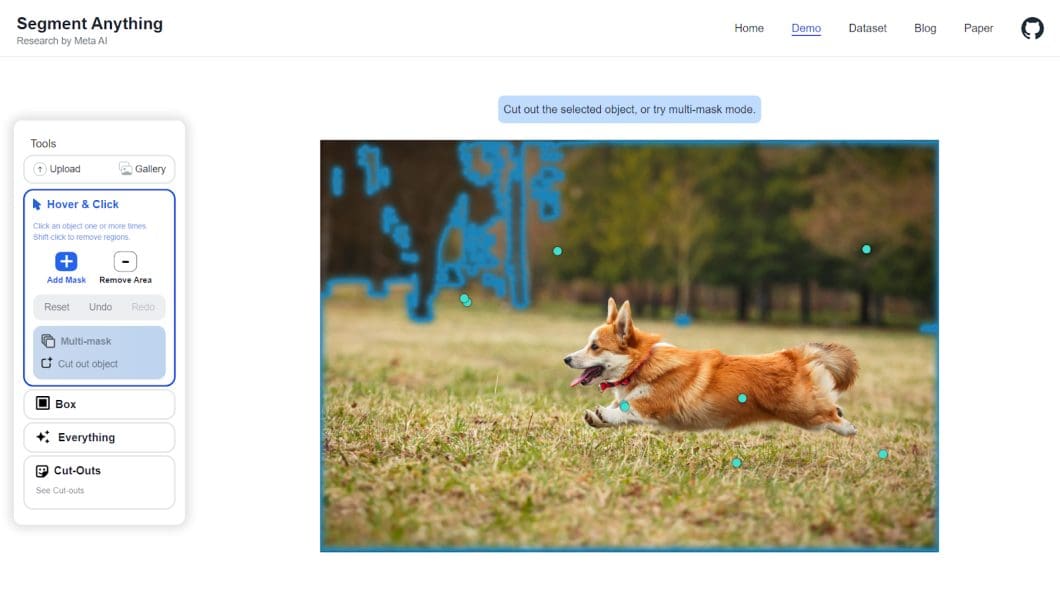
One of its standout features is the ability to process multiple prompts. You can hover or click on elements, drag boxes around them, automatically segment everything, and create custom masks or cut-outs.

While effective in specific areas, previous models often needed extensive retraining to adapt to new or varied tasks. Thus, SAM is a significant shift in making these models more flexible and efficient, setting a new benchmark for computer vision.
Computer Vision at Meta AI: A Brief History
Meta, formerly known as Facebook, has been a key player in advancing AI and computer vision technologies. The Meta AI Lab, previously known as Facebook AI Research or FAIR, was established in late 2013 to advance the state of artificial intelligence through open research. With notable researchers like Yann LeCun joining, Meta’s AI lab has since released several influential models and tools that have shaped today’s AI landscape.
The development of PyTorch, a popular open-source machine learning library, marked a significant milestone, offering researchers and developers a flexible platform for AI experimentation and deployment. Similarly, the introduction of the Segment Anything Model (SAM) represents a major advancement in the field of image segmentation.
Recently, the computer vision project SAM has gained enormous momentum in mobile applications, automated image annotation tools, facial recognition systems, and image classification applications.
The Segment Anything Model (SAM) Architecture
SAM’s revolutionary capabilities are primarily based on its revolutionary architecture, which consists of three main components: the image encoder, prompt encoder, and mask decoder.
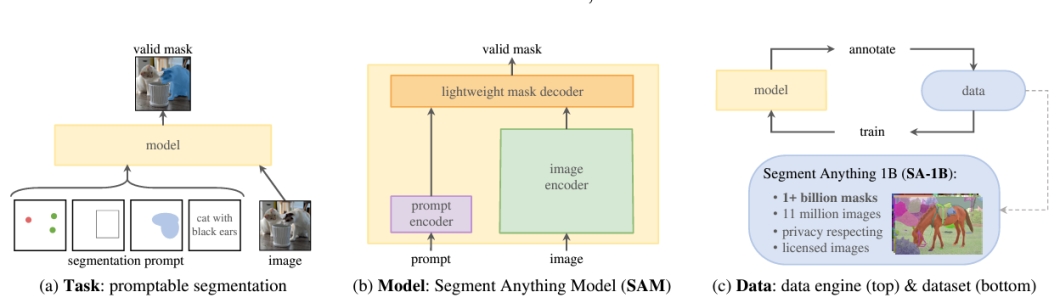
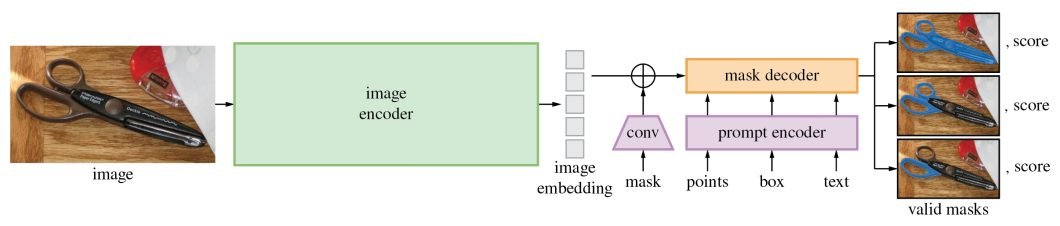
Image Encoder
- The image encoder is at the core of SAM’s architecture, a sophisticated component responsible for processing and transforming input images into a comprehensive set of features.
- Using a transformer-based approach, like what’s seen in advanced NLP models, this encoder compresses images into a dense feature matrix. This matrix forms the foundational understanding from which the model identifies various image elements.
Prompt Encoder
- The prompt encoder is a unique aspect of SAM that sets it apart from traditional image segmentation models.
- It interprets various forms of input prompts, be they text-based, points, rough masks, or a combination thereof.
- This encoder translates these prompts into an embedding that guides the segmentation process. This enables the model to focus on specific areas or objects within an image as the input dictates.
Mask Decoder
- The mask decoder is where the magic of segmentation takes place. It synthesizes the information from both the image and prompt encoders to produce accurate segmentation masks.
- This component is responsible for the final output, determining the precise contours and areas of each segment within the image.
- How these components interact with each other is equally vital for effective image segmentation as their capabilities:
- The image encoder first creates a detailed understanding of the entire image, breaking it down into features that the engine can analyze.
- The prompt encoder then adds context, focusing the model’s attention based on the provided input, whether a simple point or a complex text description.
- Finally, the mask decoder uses this combined information to segment the image accurately, ensuring that the output aligns with the input prompt’s intent.
Technical Backbone of the Segment Anything Model
Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs) play a foundational role in the capabilities of SAM. These deep learning models are central to the advancement of machine learning and AI, particularly in the realm of image processing. They provide the underpinning that makes SAM’s sophisticated image segmentation possible.
Convolutional Neural Networks (CNNs)
CNNs are integral to the image encoder of the Segment Anything Model architecture. They excel at recognizing patterns in images by learning spatial hierarchies of features, from simple edges to more complex shapes.
In SAM, CNNs analyze and interpret visual data, efficiently processing pixels to detect and understand various features and objects within an image. This ability is crucial for SAM’s architecture’s initial image analysis stage.
Generative Adversarial Networks (GANs)
GANs contribute to SAM’s ability to generate precise segmentation masks. Consisting of two parts, the generator and the discriminator, GANs are adept at understanding and replicating complex data distributions.
The generator focuses on producing lifelike images, and the discriminator evaluates these images to determine if they are real or artificially created. This dynamic enhances the generator’s ability to create highly realistic synthetic images.

CNN and GAN Complementing Each Other
The synergy between CNNs and GANs within SAM’s framework is vital. While CNNs provide a robust method for feature extraction and initial image analysis, GANs enhance the model’s ability to generate accurate and realistic segmentations.
This combination allows SAM to understand a wide array of visual inputs and respond with high precision. By integrating these technologies, SAM represents a significant leap forward, showcasing the potential of combining different neural network architectures for advanced AI applications.
CLIP (Contrastive Language-Image Pre-training)
CLIP, developed by OpenAI, is a model that bridges the gap between text and images.
CLIP’s ability to understand and interpret text prompts in relation to images is invaluable to how SAM works. It allows SAM to process and respond to text-based inputs, such as descriptions or labels, and relate them accurately to visual data.
This integration enhances SAM’s versatility, enabling it to segment images based on visual cues and follow textual instructions.

Transfer Learning and Pre-trained Models
Transfer learning involves utilizing a model trained on one task as a foundation for another related task. Pre-trained models like ResNet, VGG, and EfficientNet, which have been extensively trained on large datasets, are prime examples of this.
ResNet is known for its deep network architecture, which solves the vanishing gradient problem, allowing it to learn from a vast amount of visual data. VGG is admired for its simplicity and effectiveness in image recognition tasks. EfficientNet, on the other hand, provides a scalable and efficient architecture that balances model complexity and performance.
Using transfer learning and pre-trained models, SAM gains a head start in understanding complex image features. This is essential for its high accuracy and efficiency in image segmentation. Thus, this makes SAM powerful and efficient in adapting to new segmentation challenges.

SA-1B Dataset (Segment Anything): A New Milestone in AI Training
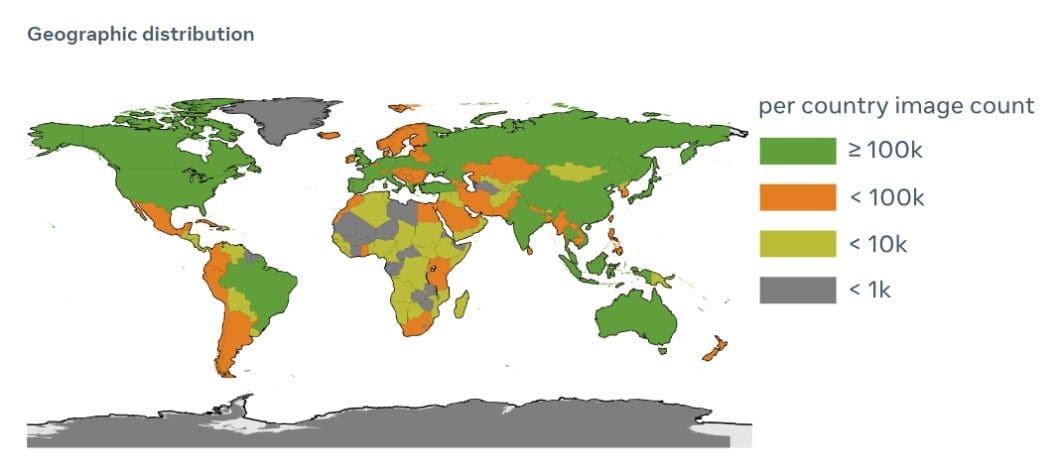
SAM’s true superpower is its training data, called the SA-1B Dataset. Short for Segment Anything 1 Billion, it’s the most extensive and diverse image segmentation dataset available.
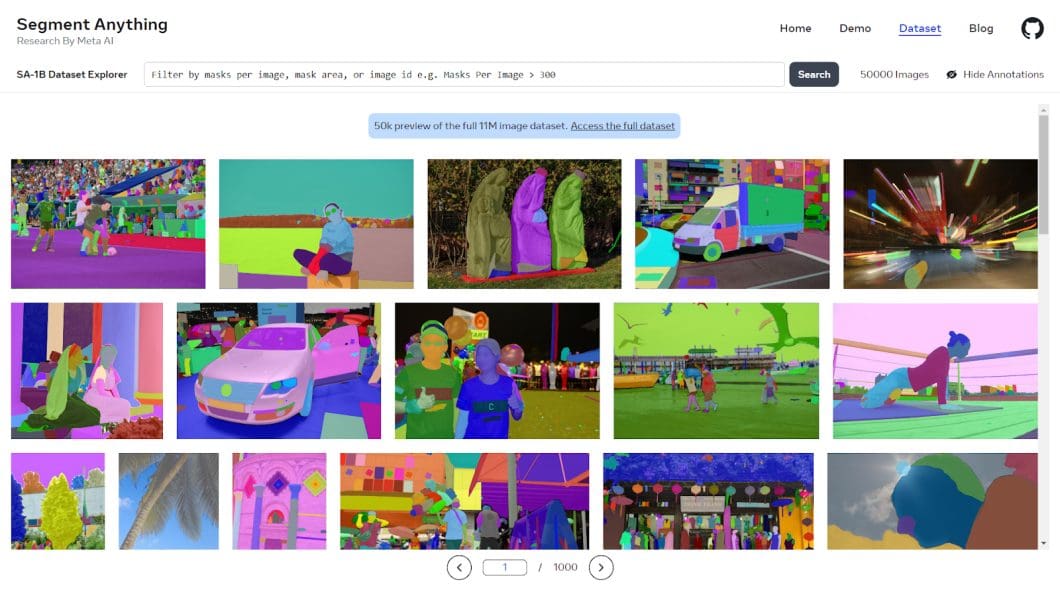
It encompasses over 1 billion high-quality segmentation masks derived from a vast array of 11 million images and covers a broad spectrum of scenarios, objects, and environments. Hence, SA-1B is an unparalleled, high-quality resource curated specifically for training segmentation models.
Creating this dataset took multiple stages of production:
- Assisted Manual: In this initial stage, human annotators work alongside the Segment Anything Model, ensuring that every mask in an image is accurately captured and annotated.
- Semi-Automatic: Annotators are tasked with focusing on areas where SAM is less confident, refining and supplementing the model’s predictions.
- Full-Auto: SAM independently predicts segmentation masks in the final stage, showcasing its ability to handle complex and ambiguous scenarios with minimal human intervention.
The vastness and variety of the SA-1B Dataset push the boundaries of what’s achievable in AI research. Hence, such a dataset enables more robust training, allowing models like SAM to handle an unprecedented range of image segmentation tasks with high accuracy. It provides a rich pool of data that enhances the model’s learning, ensuring it can generalize well across different tasks and environments.
Segment Anything Model Applications
As a giant leap forward in image segmentation, SAM can be used in almost every possible application.
Here are some of the applications in which SAM is already making waves:
- AI-Assisted Labeling: SAM significantly streamlines the process of labeling images. It can automatically identify and segment objects within images, drastically reducing the time and effort required for manual annotation.
- Medicine Delivery: In healthcare, SAM’s precise segmentation capabilities enable the identification of specific regions for drug delivery. Thus, ensuring precision in treatment and minimizing side effects.
- Land Cover Mapping: SAM can be utilized to classify and map different types of land cover, enabling applications in urban planning, agriculture, and environmental monitoring.

The Future Potential of the Segment Anything Model
SAM’s potential extends beyond current applications. In fields like environmental monitoring, it could aid in analyzing satellite imagery for climate change studies or disaster response.
In retail, SAM could revolutionize inventory management through automated product recognition and categorization.
SAM’s unequaled adaptability and accuracy positions it to be the new standard in image segmentation. Its ability to learn from a vast and diverse dataset means it can continuously improve and adapt to new challenges.
We can expect SAM to evolve with better real-time processing capabilities. With this evolution, we can expect to see SAM become ubiquitous in fields like autonomous vehicles and real-time surveillance. In the entertainment industry, we could see advancements in visual effects and augmented reality experiences.